
クラウドインテグレーション事業部 セキュリティセクションの日下です。
今回は、Amazon Inspector でEC2インスタンスのスキャンした結果をのレポートを
Lambda関数を使って修正する方法について、簡単ではありますが記載していきます。
そもそもAmazon Inspectorとは?
まず、Amazon Inspectorについてですが、ざっくりいうとAWSが提供する脆弱性管理サービスのことで、
クラウド環境におけるセキュリティリスクを特定し、修正を支援してくれるサービスです。
EC2インスタンスやコンテナ(ECS、EKS)、Lambdaに対して、自動で脆弱性のスキャンを実行し
既知の脆弱性(CVE)やソフトウェアの不備を検出してくれます。
検出した結果について
出力された脆弱性は、AWSコンソール上だけでなく、JSON もしくは csv形式のファイルでまとめて出力することができます。
レポートに記載されている項目は以下になります。
レポートに記録される項目一覧※該当しない項目は空白で表示されます。
- AWS Account Id: AWSアカウントID
- Severity: 重大度
- Fix Available: 修正の有無
- Finding Type: 発見タイプ
- Title: タイトル
- Description: 説明
- Finding ARN: 発見のARN
- First Seen: 初めて検出された日時
- Last Seen: 最後に検出された日時
- Last Updated: 最後に更新された日時
- Resource ID: リソースID
- Container Image Tags: コンテナイメージタグ
- Region: リージョン
- Platform: プラットフォーム
- Resource Tags: リソースタグ
- Affected Packages: 影響を受けたパッケージ
- Package Installed Version: インストール済みのパッケージバージョン
- Fixed in Version: 修正バージョン
- Package Remediation: パッケージ修正方法
- File Path: ファイルパス
- Network Paths: ネットワークパス
- Age (Days): 経過日数
- Remediation: 修正方法
- Inspector Score: インスペクターのスコア
- Inspector Score Vector: インスペクターのスコアベクトル
- Status: ステータス
- Vulnerability Id: 脆弱性ID
- Vendor: ベンダー
- Vendor Severity: ベンダーの重大度
- Vendor Advisory: ベンダーアドバイザリ
- Vendor Advisory Published: ベンダーアドバイザリの公開日時
- NVD CVSS3 Score: NVD CVSS3スコア
- NVD CVSS3 Vector: NVD CVSS3ベクトル
- NVD CVSS2 Score: NVD CVSS2スコア
- NVD CVSS2 Vector: NVD CVSS2ベクトル
- Vendor CVSS3 Score: ベンダーCVSS3スコア
- Vendor CVSS3 Vector: ベンダーCVSS3ベクトル
- Vendor CVSS2 Score: ベンダーCVSS2スコア
- Vendor CVSS2 Vector: ベンダーCVSS2ベクトル
- Resource Type: リソースタイプ
- Ami: AMI
- Resource Public Ipv4: リソースのパブリックIPv4
- Resource Private Ipv4: リソースのプライベートIPv4
- Resource Ipv6: リソースのIPv6
- Resource Vpc: リソースVPC
- Port Range: ポート範囲
- Exploit Available: 攻撃可能な状態
- Last Exploited At: 最後に悪用された日時
- Lambda Layers: Lambdaレイヤー
- Lambda Package Type: Lambdaパッケージタイプ
- Lambda Last Updated At: Lambdaの最終更新日時
- Reference Urls: 参照URL
検出結果の項目についての公式ドキュメントはこちらです。
修正しようとした理由について
今回Lambda関数を用いてレポートの内容を修正した理由は以下の4つです。
- インスタンス名の記載が欲しいため
- 中身が英語だったため日本語で出力したいため
- 必要な項目のみを出したいため
- 日本時間で管理したいため
1.インスタンス名の記載が欲しい
検出されたファイルのうち、Resource Tagsでインスタンス名がわかる場合もありますが
個人的に対象の脆弱性がどのインスタンスに対して検出されたかを分かりやすくしたいと思いました。
2.日本語で出力したい
ファイルに記載された内容は、すべて英語で出力されますので、項目名だけでも日本語に翻訳できたらいいなと思いました。
3.必要項目のみを出力したい
私の場合、インスタンスの脆弱性を管理したいという背景から
コンテナやLambda関数の脆弱性に関する項目は不要であり、それらを削ったファイルが出力できればいいなと思いました。
4.日本時間で出力したい
以下をはじめ、出力される時刻はUTC(協定世界時)で出力されますことから
個人的には日本時間で出した方がわかりやすいなと思いました。
First Seen: 初めて検出された日時
Last Seen: 最後に検出された日時
Last Updated: 最後に更新された日時
変更にあたって必要なこと
今回Lambda関数を用いてレポートの内容を編集する上で必要な設定は大きく以下3つです。
- ロールの作成
- KMSキーとバケットのポリシーを変更
- Lambda関数の作成
1.ロールの作成
まず実行するLambda関数に割り当てるロールを作成します。
IAM → ロールからロールを作成より、以下の流れで作成していきます。
- 信頼されたエンティティタイプ:AWSサービス
- 許可ポリシー:以下の5つを追加
AmazonEC2ReadOnlyAccess:AWS管理
AmazonS3FullAccess:AWS管理
TranslateReadOnly:AWS管理
KMSPolicy:カスタマー管理
LogGroupManagementPolicy:カスタマー管理
残りはロール名を入力すれば、以下のように完成します。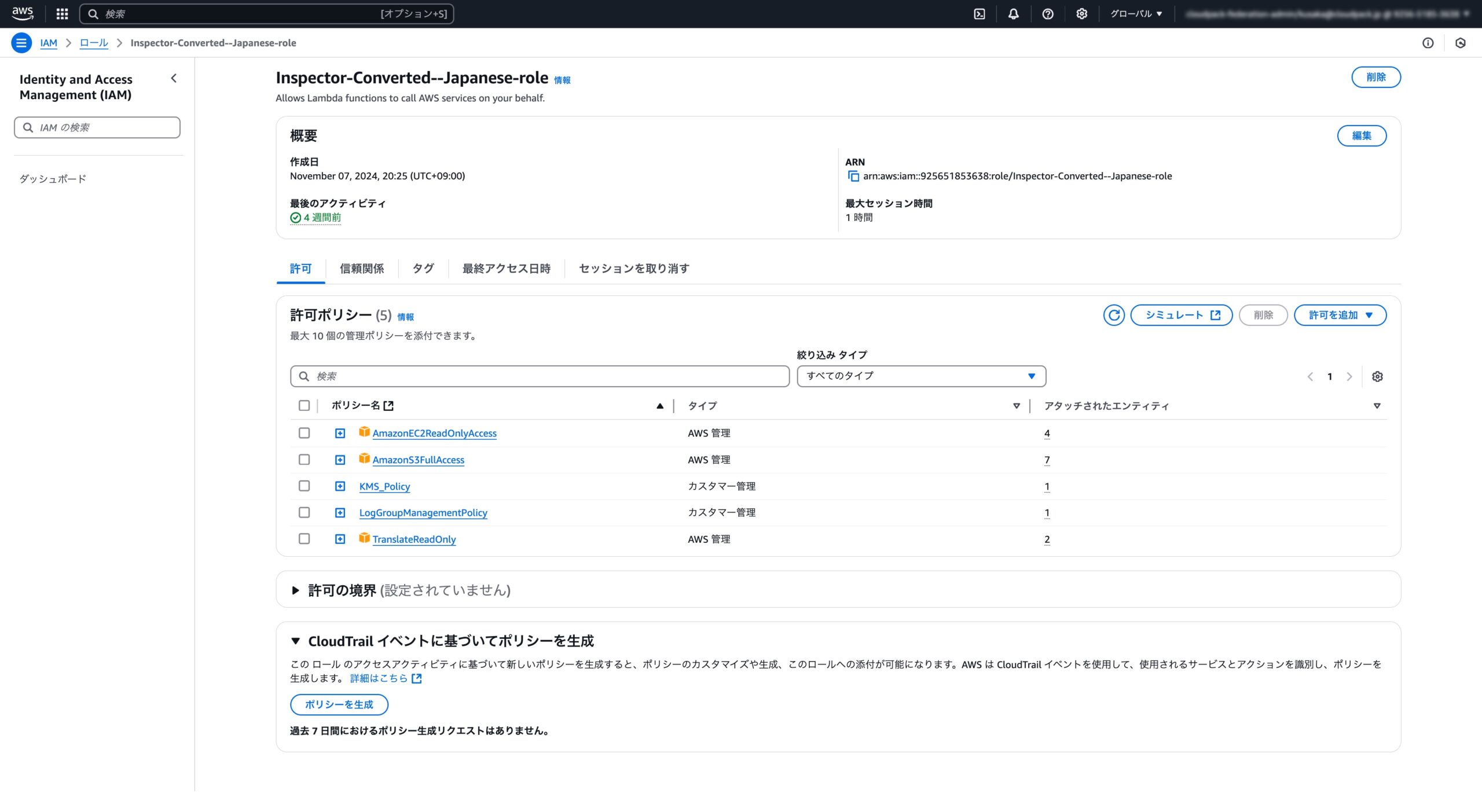 それぞれのポリシーを割り当てた理由は次のようになります。
それぞれのポリシーを割り当てた理由は次のようになります。
- AmazonEC2ReadOnlyAccess:Lambda関数を使ってインスタンス情報の取得を行うため
- AmazonS3FullAccess:AWS管理:Inspector経由でS3に出力されたバケットを取得し、カスタムしたファイルをアップするため
- TranslateReadOnly:AWS管理:Amazon Translateという翻訳サービスを使って、日本語翻訳を行うため
- KMSPolicy:カスタマー管理:ファイルを取得し、アップロードする際に対象ファイルをKMSで作成したキーを使って暗号化、復号化、データ暗号化用の一時的なキーを生成するため
実際の作成したポリシーは以下です。
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: [
“kms:Encrypt”,
“kms:Decrypt”,
“kms:GenerateDataKey”
],
“Resource”: “※※※※(Inspectorからファイルを出力する際のKMSキーのarnを指定)”
}
]
}
- LogGroupManagementPolicy:カスタマー管理:作成したLambda関数用のロググループの作成とログを送信をするため
実際の作成したポリシーは以下です。
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: “logs:CreateLogGroup”,
“Resource”: “*”
},
{
“Effect”: “Allow”,
“Action”: [
“logs:CreateLogStream”,
“logs:PutLogEvents”
],
“Resource”: [
“arn:aws:logs:※(リージョン):※(AWSアカウントID):log-group:/aws/lambda/※(作成するLambda関数名):*”
]
}
]
}
2.KMSキーとバケットのポリシーを変更
次にInspectorからファイルを出力する際に使用するKMSキーとバケットのポリシーに作成するLambda関数用の権限を追加します。
実際のポリシーの内容と追加箇所は以下になります。
※追加箇所は太字で記載しています。
キーポリシー
{
“Version”: “2012-10-17”,
“Id”: “key-consolepolicy-3”,
“Statement”: [
{
“Sid”: “Enable IAM User Permissions”,
“Effect”: “Allow”,
“Principal”: {
“AWS”: “※※※※※※※※※(AWSアカウント)”
},
“Action”: “kms:*”,
“Resource”: “*”
},
{
“Effect”: “Allow”,
“Principal”: {
“Service”: “inspector2.amazonaws.com”#Amazon Inspector用のポリシー
},
“Action”: [
“kms:Encrypt”,
“kms:Decrypt”,
“kms:GenerateDataKey”
],
“Resource”: “*”
},
{
“Sid”: “AllowLambdaRoleDecrypt”,#Lambda関数用のポリシー
“Effect”: “Allow”,
“Principal”: {
“AWS”: “arn:aws:iam::※※(AWSアカウントID):role/※※(作成するLambda関数名)”
},
“Action”: [
“kms:Encrypt”,
“kms:Decrypt”,
“kms:GenerateDataKey”
],
“Resource”: “*”
}
]
}
バケットポリシー
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Sid”: “allow-inspector”,#Amazon Inspector用のポリシー
“Effect”: “Allow”,
“Principal”: {
“Service”: “inspector2.amazonaws.com”
},
“Action”: [
“s3:PutObject”,
“s3:PutObjectAcl”,
“s3:AbortMultipartUpload”
],
“Resource”: “arn:aws:s3:::※アップ先のバケット名/*”,
“Condition”: {
“StringEquals”: {
“aws:SourceAccount”: “※※”
}
}
},
{
“Sid”: “allow-lambda-access”,#Lambda関数用のポリシー
“Effect”: “Allow”,
“Principal”: {
“AWS”: “arn:aws:iam::※※(AWSアカウントID):role/※※(作成するLambda関数名)”
},
“Action”: “s3:*”,
“Resource”: “arn:aws:s3:::※アップ先のバケット名/*”
}
]
}
3.Lambda関数の作成
まずは、Lambda → 関数の作成より 関数名、ランタイム、作成したロールの適用を行い、関数を作成します。
※ランタイムとは、Lambda と関数の間の呼び出しイベント、コンテキスト情報、レスポンスを中継する言語固有の環境のことです。
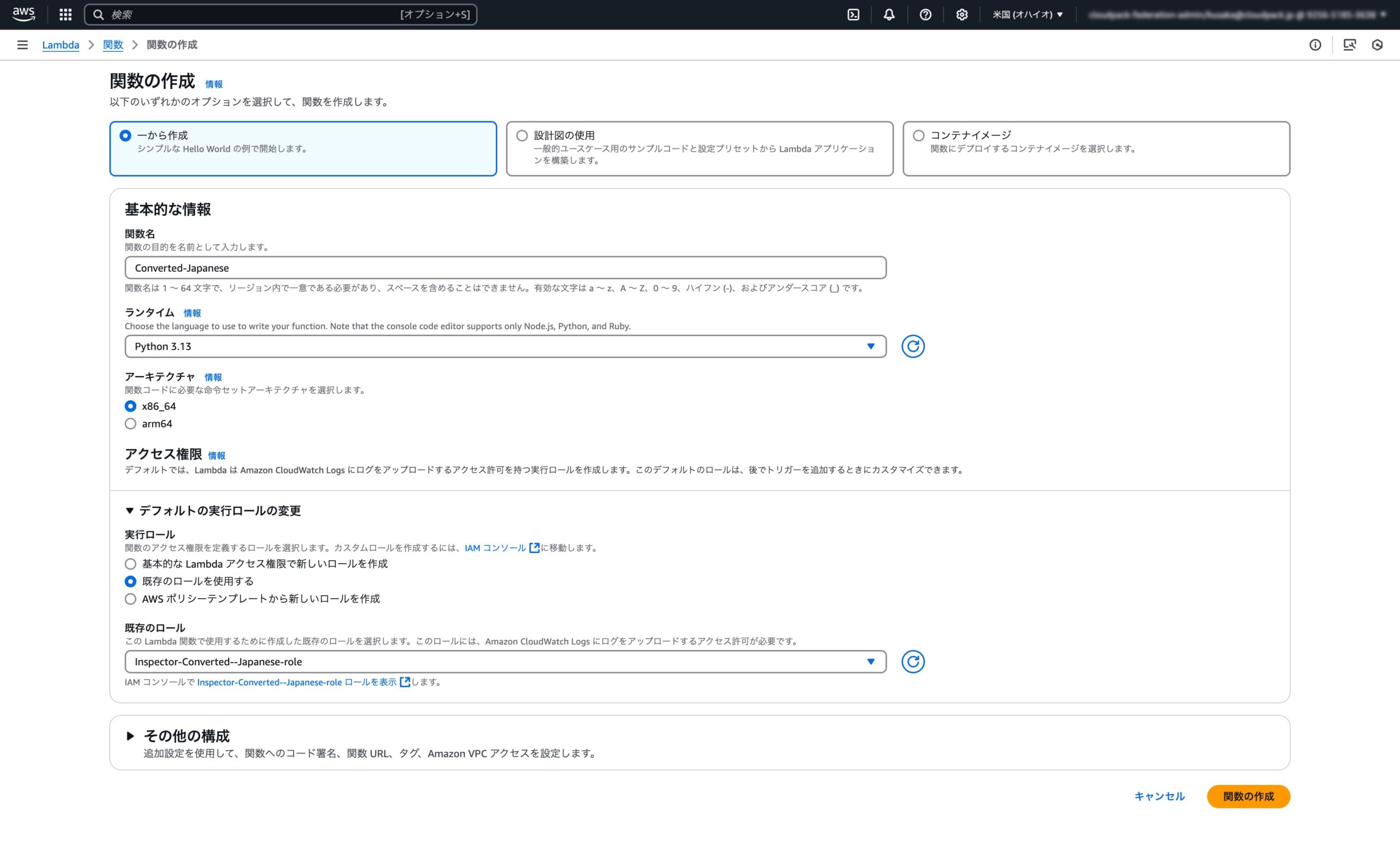 作成したLambda関数に対して、デフォルトの設定から下記部分を変更します。
作成したLambda関数に対して、デフォルトの設定から下記部分を変更します。
- 一般設定:タイムアウト0分3秒→5分0秒にする。※ファイルの編集時間にゆとりをもたせるため、5分で設定します。
- タグ:この関数をAmazon Inspector のスキャン対象外にする場合は、キーに「InspectorExclusion」値に「LambdaStandardScanning」を入力します。
- トリガーの設定:Amazon Inspector で出力されたファイルがS3バケットにアップロードされたことをトリガーにLambda関数を実行するようにします。
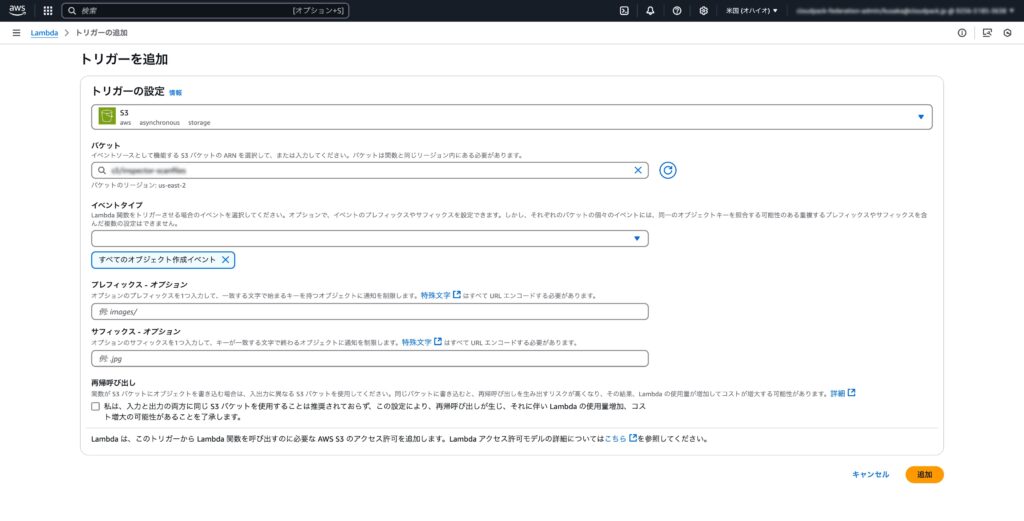
そして実際のコードは下記になります。
コード全体
import json
import boto3
import csv
import io
from datetime import datetime, timedeltadef lambda_handler(event, context):
s3 = boto3.client(‘s3’)
ec2 = boto3.client(‘ec2’)
translate = boto3.client(‘translate’)# S3イベントからバケット名とファイル名を取得
bucket_name = event[‘Records’][0][‘s3’][‘bucket’][‘name’]
file_name = event[‘Records’][0][‘s3’][‘object’][‘key’]# S3からCSVファイルを読み込む
response = s3.get_object(Bucket=bucket_name, Key=file_name)
csv_content = response[‘Body’].read().decode(‘utf-8’)# CSVを読み込む
csv_reader = csv.reader(io.StringIO(csv_content))# 新しいデータを保存するためのリスト
translated_data = []# ヘッダーを取得
header = next(csv_reader)# ヘッダーで翻訳をスキップする列を指定
skip_translation_headers = [
#翻訳不要な項目名を追加する
]# 削除したい列のリスト
columns_to_remove = [
# 割愛したい項目名を追加する
]columns_to_remove_indices = [header.index(col) for col in columns_to_remove if col in header]
# ヘッダーから削除する列を除外
filtered_header = [item for index, item in enumerate(header) if index not in columns_to_remove_indices]# ヘッダーを翻訳
translated_header = []
for item in filtered_header:
if item in skip_translation_headers:
translated_header.append(item) # スキップするヘッダーはそのまま追加
else:
translated_header.append(translate_to_japanese(item, translate)) # 翻訳するヘッダーは翻訳translated_header.insert(0, “インスタンス名”) # 「インスタンス名」を最初に追加
translated_data.append(translated_header) # 翻訳されたヘッダーを新しいデータに追加# 時刻を変換したい列を指定
time_columns_to_convert = [
“First Seen”,
“Last Seen”,
“Last Updated”,
“Vendor Advisory Published”,
“Last Exploited At”
]# 各行を翻訳
for row in csv_reader:
translated_row = []
instance_id = row[header.index(“Resource ID”)]instance_name = get_instance_name(ec2, instance_id) # インスタンス名を取得
translated_row.append(instance_name)for index, item in enumerate(row):
if index in columns_to_remove_indices: # 削除したい列のインデックスの場合
continue # この列はスキップ# 時刻を変換する列かどうかをチェック
if header[index] in time_columns_to_convert:
if item: # itemが空でないかを確認
item = convert_to_japan_time(item) # 時刻を変換
else:
item = ” # 空の場合はそのまま空を設定translated_row.append(item) # 残りの項目をそのまま追加
translated_data.append(translated_row) # インスタンス名を最初に追加した行を保存
# 新しいCSVファイルを生成
output_csv_buffer = io.StringIO()
csv_writer = csv.writer(output_csv_buffer)
csv_writer.writerows(translated_data)# 現在の日時を日本時間で取得
japan_time = datetime.utcnow() + timedelta(hours=9) # UTCに9時間を加算
timestamp = japan_time.strftime(“%Y%m%d_%H%M%S”) # フォーマット例: 20241024_123456# アップロード先のバケット名
output_bucket_name = ‘※※’ # バケット名を指定# S3に翻訳されたデータをアップロード
output_file_name = f’inspector-japanese/translated_{timestamp}.csv’ # 日時をファイル名に追加
s3.put_object(Bucket=output_bucket_name, Key=output_file_name, Body=output_csv_buffer.getvalue(), ContentType=’text/csv’)return {
‘statusCode’: 200,
‘body’: json.dumps(f”{output_file_name} が保存されました。”)
}def translate_to_japanese(text, translate_client):
response = translate_client.translate_text(
Text=text,
SourceLanguageCode=’en’,
TargetLanguageCode=’ja’
)
return response[‘TranslatedText’]def get_instance_name(ec2_client, instance_id):
try:
response = ec2_client.describe_instances(InstanceIds=[instance_id])
instances = response[‘Reservations’][0][‘Instances’]
if instances:
for instance in instances:
for tag in instance.get(‘Tags’, []):
if tag[‘Key’] == ‘Name’:
return tag[‘Value’]
except Exception as e:
print(f”インスタンス名の取得に失敗しました: {str(e)}”)
return ‘Unknown’def convert_to_japan_time(iso_time):
# ISO 8601形式の文字列を解析して日本時間に変換
utc_time = datetime.fromisoformat(iso_time.replace(“Z”, “+00:00”)) # ZをUTCに変換
japan_time = utc_time + timedelta(hours=9) # UTCから日本時間に変換
return japan_time.strftime(“%Y 年 %m 月 %d 日 %H 時 %M 分”) # フォーマット変更
そして、各設定は以下になります。
変数一覧
- bucket_name: Amazon Inspectorから出力されたcsvファイルの格納先のバケット名。
- file_name: Amazon Inspectorから出力されたcsvファイル名。
- csv_content: S3から読み込んだcsvファイルの内容。
- header: csvファイルのヘッダー情報(項目が記載されている行)。
- skip_translation_headers: 翻訳をスキップしたい項目名を指定。
- columns_to_remove: 出力時に割愛する項目のリスト。
- columns_to_remove_indices: columns_to_removeで指定した項目がheaderの中でどの位置にあるかを示すリスト。
- filtered_header: 削除する列を除いたヘッダーのリスト。
- translated_header: 翻訳されたヘッダーを格納するリスト。
- time_columns_to_convert: 日本時間に変換したい列名を格納するリスト。
- translated_row: 翻訳後のデータ行。
- instance_name: EC2インスタンス名。get_instance_name関数で取得します。
- output_csv_buffer: 出力用のcsvデータを格納するバッファ。
- timestamp: 作成時の日本時間を基に生成されるタイムスタンプ。ファイル名に利用します。
- output_file_name: 出力するcsvファイルの名前。タイムスタンプを含んでいます。
- output_bucket_name: 出力先のS3バケット名。
関数一覧
translate_to_japanese 関数
def translate_to_japanese(text, translate_client):
response = translate_client.translate_text(
Text=text,
SourceLanguageCode=’en’,
TargetLanguageCode=’ja’
)
return response[‘TranslatedText’]
- 目的: AWS Translateサービスを利用し、英語で記載された箇所 (text) を日本語に翻訳する処理を行います。
- 引数
- text: 翻訳したい英語のテキスト。
- translate_client: AWSの翻訳サービスを利用するためのクライアント(boto3.client(‘translate’)で生成)。
- 処理の流れ
- translate_client.translate_text メソッドを呼び出して、text を翻訳します。SourceLanguageCode=’en’ と TargetLanguageCode=’ja’ を指定して、英語から日本語への翻訳を行っています。
- レスポンスの中から翻訳されたテキスト (TranslatedText) を取り出して返します。
- 戻り値: 翻訳された日本語のテキスト。
get_instance_name 関数
def get_instance_name(ec2_client, instance_id):
try:
response = ec2_client.describe_instances(InstanceIds=[instance_id])
instances = response[‘Reservations’][0][‘Instances’]
if instances:
for instance in instances:
for tag in instance.get(‘Tags’, []):
if tag[‘Key’] == ‘Name’:
return tag[‘Value’]
except Exception as e:
print(f”インスタンス名の取得に失敗しました: {str(e)}”)
return ‘Unknown’
- 目的: スキャン対象のEC2インスタンスIDから、インスタンス名を取得する処理を行います。
- 引数
- ec2_client: EC2の操作を行うためのクライアント(boto3.client(‘ec2’)で生成)。
- instance_id: EC2インスタンスID。
- 処理の流れ
- ec2_client.describe_instances メソッドを使って、指定した instance_id に対応するインスタンス情報を取得します。
- 取得したインスタンス情報の中から、インスタンスに関連するタグ (Tags) をチェックします。
- タグの中で Key が Name (インスタンス名)となっているものを見つけ、Value を返します。
- インスタンス名が見つからなかった場合やエラーが発生した場合は Unknown を返します。
- 戻り値:インスタンス名(タグのNameキーに基づく)、もしくは Unknown(インスタンス名が見つからなかった場合)。
convert_to_japan_time 関数
def convert_to_japan_time(iso_time):
# ISO 8601形式の文字列を解析して日本時間に変換
utc_time = datetime.fromisoformat(iso_time.replace(“Z”, “+00:00”)) # ZをUTCに変換
japan_time = utc_time + timedelta(hours=9) # UTCから日本時間に変換
return japan_time.strftime(“%Y 年 %m 月 %d 日 %H 時 %M 分”) # フォーマット変更
- 目的: ISO 8601形式の日時を日本時間に変換する処理を行います。
- 引数:iso_time: UTCで表現されたISO 8601形式の日時文字列(例:2025-02-26T10:00:00Z)。
- 処理の流れ
- iso_time.replace(“Z”, “+00:00”) で、ISO 8601形式の日付文字列に含まれる Z(UTCの指定)を +00:00 に置き換えます。
- datetime.fromisoformat メソッドで、文字列をdatetime型に変換します。
- timedelta(hours=9) を使って、日本時間変換します。UTCに9時間を足すことで日本時間に変換しています。
- strftime(“%Y年%m月%d日%H時%M分”) を使って 指定された形式(例:2025年01月01日19時00分)に置き換えます。
- 戻り値:日本時間に変換された日時
実際の処理と出力結果について
まず、Amazon Inspectorからスキャンされたファイルがアップロードされてから
編集が完了しアップロードまでにかかった時間は1分未満でした!
※脆弱性の数によって処理時間は変動します。
・Amazon Inspectorから出力したファイル(出力日時:2024/01/24 17:56:37)
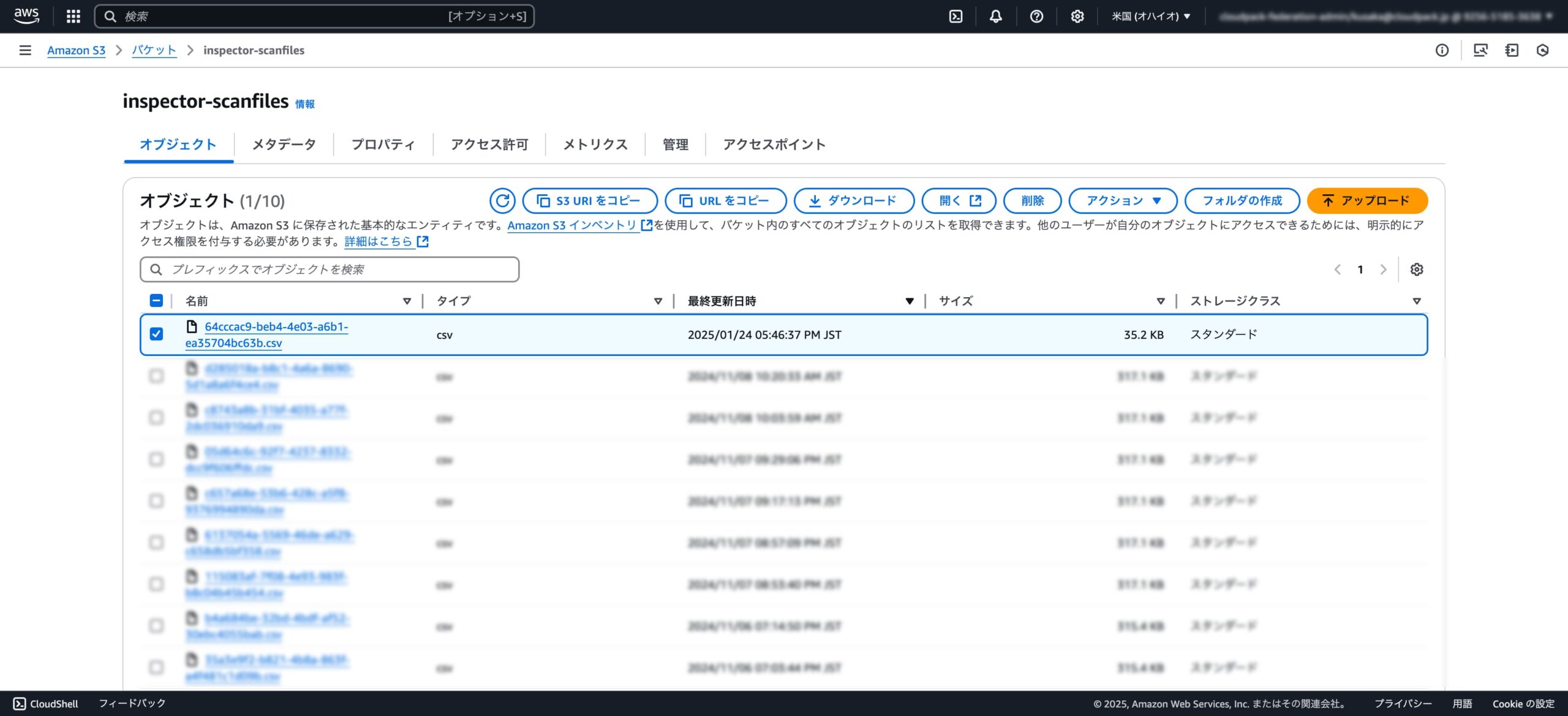
・修正ファイル(出力日時:2024/01/24 17:56:49)
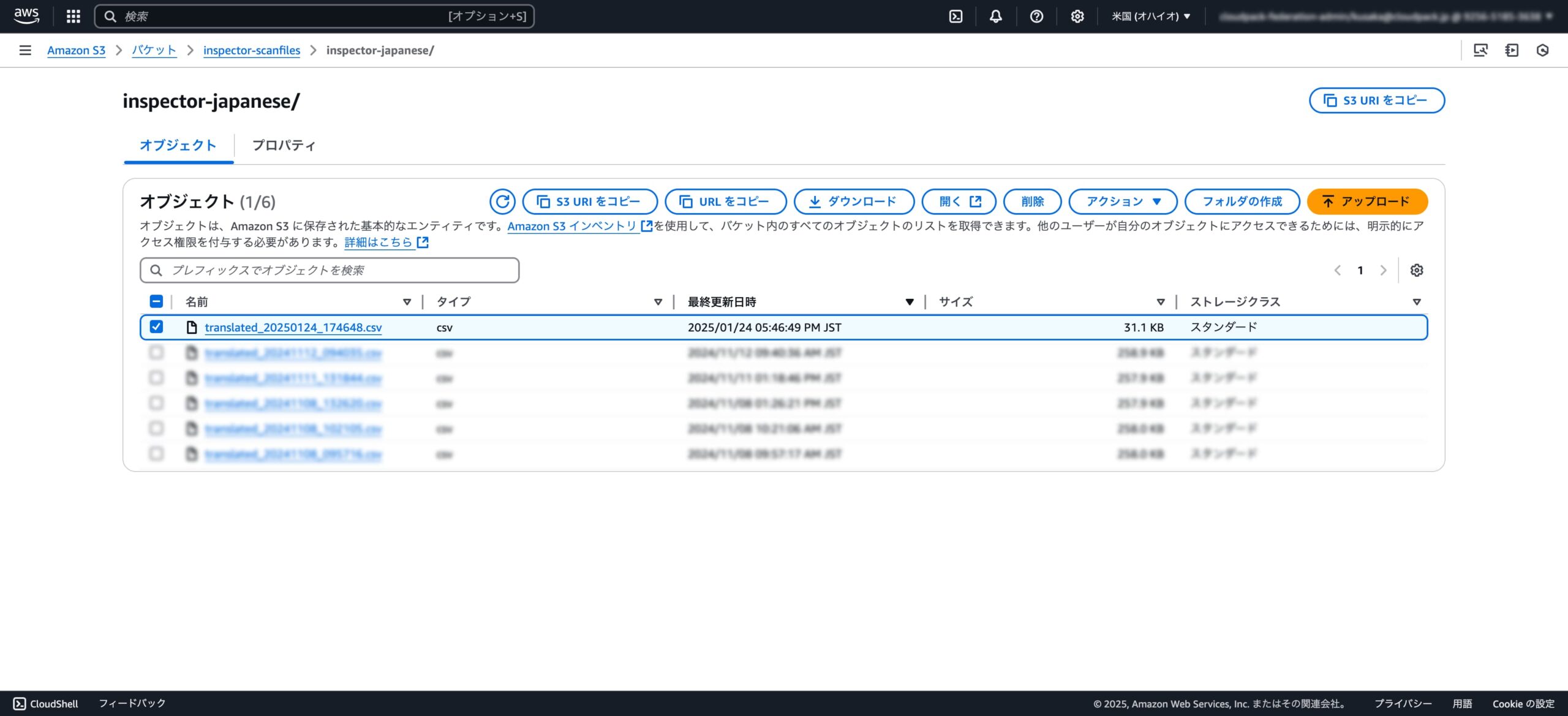
そして気になるファイルの中身ですが、項目名を日本語に変換することと、
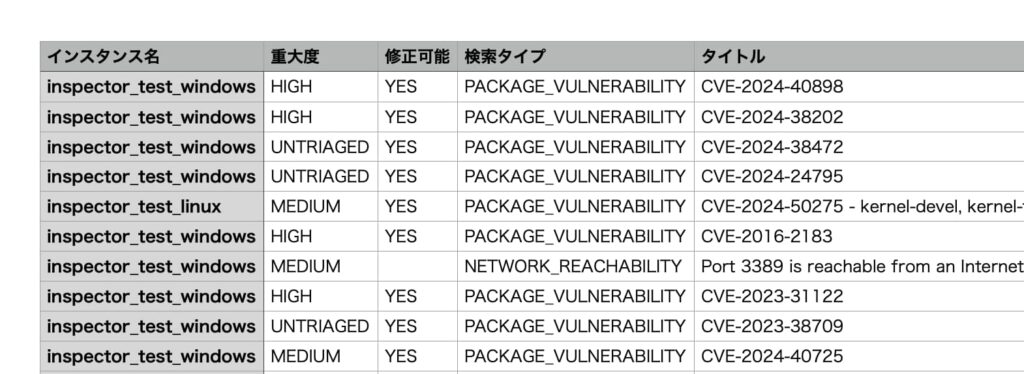
インスタンス名を1番左の列に挿入することができました!
また私の場合、アカウントIDは不要でしたので、こちらの項目を割愛することもできました!
・Amazon Inspectorから出力したファイル
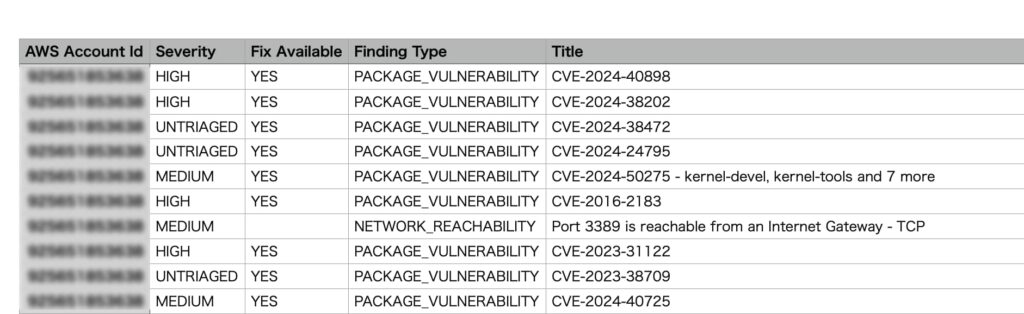
・変更ファイル
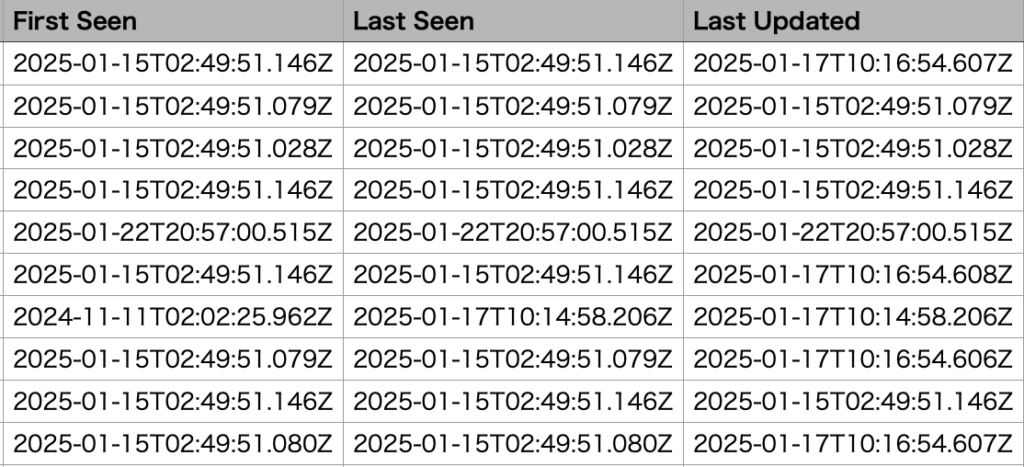
さらに、下記項目も日本時間に変換することができました!
First Seen: 初めて検出された日時
Last Seen: 最後に検出された日時
Last Updated: 最後に更新された日時
・Amazon Inspectorから出力したファイル
・変更ファイル
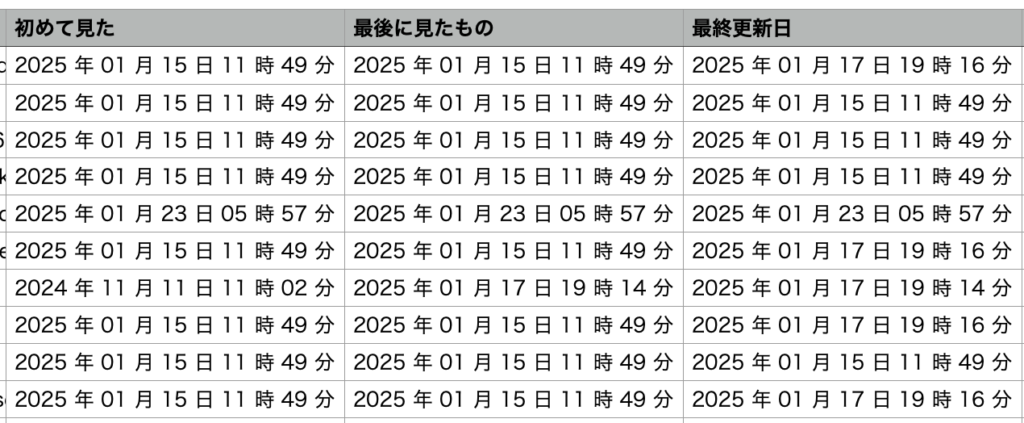
こうして問題なく自分好みに変更することができました!
まとめ
今回はAmazon Inspectorで検出されたファイルを自分好みに修正してみましたが
やはり自分好みのファイルだと管理も確認も楽になるなーと思いました!
今後もこのようなブログを沢山書いていけるように頑張っていきます!

