
Lambda の Scheduled Handler と Python の組み合わせが地味に楽しいかっぱです。
tl;dr
ラムダこりゃシリーズ 5 回目になるので、何か役に立ちそうなことをしてみたいということで Lambda + Python + Datadog で簡易 HTTP モニターを作ってみた。
どんなものか?
構成と処理の流れ
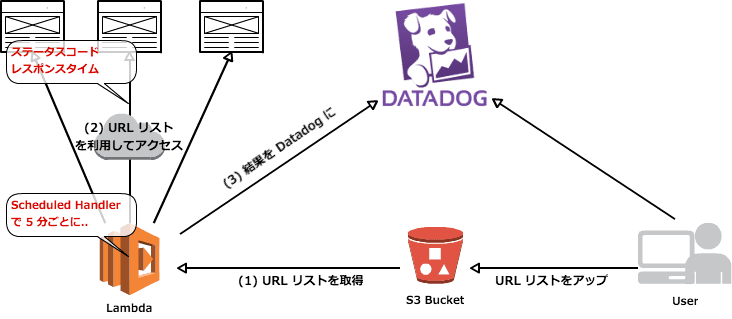
ザックリ
- Lambda + Scheduled Handler でサーバー要らず
- 監視対象の URL は S3 のバケットに置く
- レスポンスコードをチェックして 200 以外が返ってきたら Datadog の Event に通知
- レスポンスタイムも計測、値は Datadog にて可視化
- レスポンスタイムのしきい値を超えたら Datadog の Event に通知
- 発生した Event に応じて通知を設定(手動で Slack に飛ばす等)
おソース
相変わらず雑。
ざっくり使い方
- config.ini を書く
[datadog] api_key = xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx title_prefix = http-monitoring. [s3] bucket_name = your-bucket urls_list = url_list
- URL リストを書く(# は除いて書く)
# flag(0=Active / 1=Inactive), title, url, レスポンスタイムしきい値 0,url1,http://pm25.test.inokara.com/kyusyu/2015-10-11.html,0.01 1,url2,http://pm25.test.inokara.com/kyusyu/2015-10-11.html,0.01
- URL リストを S3 バケットにアップロード(事前にバケットを作っておく)
% aws s3 cp url_list s3://your-bucket/url_list
- 必要なモジュールをインストールする
% cat > ~/.pydistutils.cfg [install] prefix= EOT % pip install requests ./ % pip install boto3 -t ./ % rm ~/.pydistutils.cfg
- ソースコードを zip で固める
# ソースコードを zip で固める % zip -r your_function.zip *
- Lambda ファンクションを作成
# Lambda ファンクションを作成 % aws lambda --region us-east-1 create-function --function-name http-monitor --runtime python2.7 --role arn:aws:iam::123456789012:role/lambda_basic_execution --handler http-monitor.lambda_handler --timeout 10 --zip-file fileb://your_function.zip
Lambda ファンクションに利用する IAM role には S3 の Read-Only ポリシーも付与しておくのをお忘れなく…。
スクショ
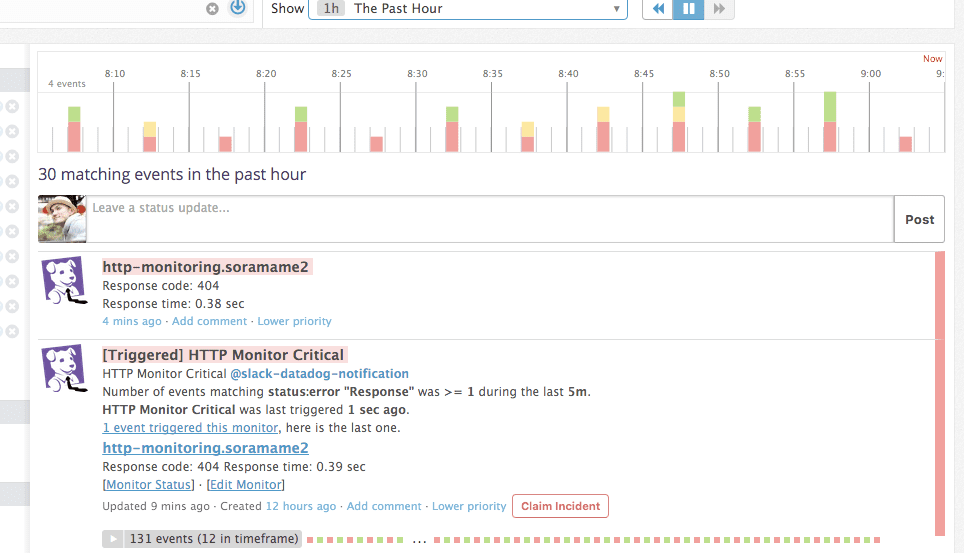
- Datadog の Events
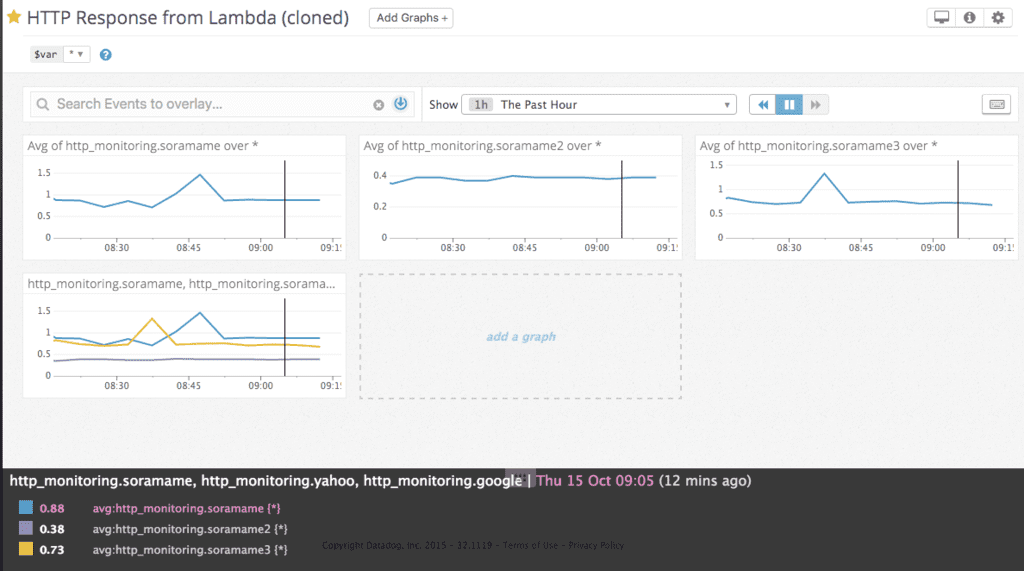
- Datadog の Metrics
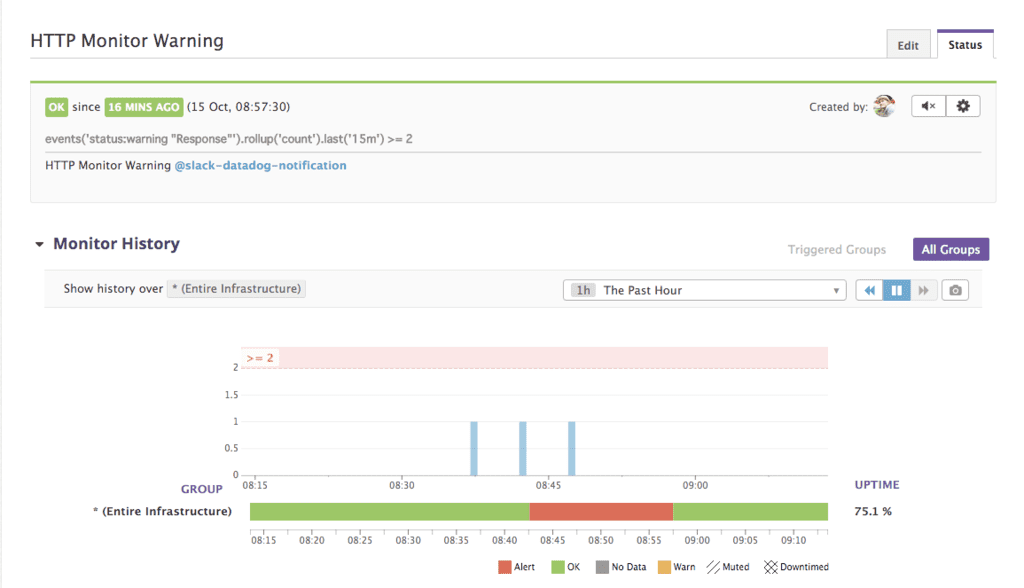
- Datadog の Monitor
得た知見
datadogpy を使ってない理由
今回は Datadog API の Python 版ライブラリである datadogpy を使いたかったが以下のエラーが出てしまったので使ってない。

Unable to import module 'http-monitor': No module named pkg_resources このエラーが出るのはなんでだろう…。未だに謎。
boto3 で S3 にアクセスする
# config.ini から設定ファイルの読み込み
c = ConfigParser.SafeConfigParser()
c.read("./config.ini")
# boto3 を利用して S3 上の URL リストを取得
def get_urls_list():
logging.info("=== boto3 を利用して S3 上の URL リストを取得")
s3 = Session().client('s3')
response = s3.get_object(Bucket=c.get('s3','bucket_name'), Key=c.get('s3','urls_list'))
body = response['Body'].read()
# 内容をバルクで返す
return body.strip()
上記の関数はバケット(c.get('s3','bucket_name'))に含まれるキー = オブジェクト(c.get('s3','urls_list'))の中身を以下のような結果を返す。
0,soramame,http://pm25.test.inokara.com/kyusyu/2015-10-11.html,1.0 1,yahoo,http://www.yahoo.co.jp/,1.0 1,google,https://www.google.co.jp/,1.0 0,soramame2,http://pm25.test.inokara.com/kyusyu/2015-09-18.html,1.0 0,soramame3,http://pm25.test.inokara.com/kyusyu/2015-10-01.html,1.0
受け取った値は以下のように展開した。
urls_list = get_urls_list()
for url_list in urls_list.split("n"):
access_list = url_list.rstrip().split(",")
if str(access_list[0]) == '0':
res_time, res_code = check_http_access(access_list[2])
if res_code != 200:
post2datadog_event(c.get('datadog','title_prefix') + access_list[1], res_code, res_time, 'error')
elif res_code == 200 and res_time > float(access_list[3]):
post2datadog_event(c.get('datadog','title_prefix') + access_list[1], res_code, res_time, 'warning')
post2datadog_metric(c.get('datadog','title_prefix') + access_list[1], currenttime, res_time)
レスポンスタイムとステータスコードを一緒に返す方法
関数からの戻り値に関して、同時に二つの戻り値を返したい場合には以下のように書いた。
# 指定した URL にアクセスしてレスポンスコードとレスポンスタイムを返す
def check_http_access(url):
logging.info("=== elapsed.total_seconds() を利用して http レスポンスを確認")
logging.info("=== %s にアクセス" % url)
start = time.time()
r = requests.request('GET', url)
r.content
roundtrip = time.time() - start
# print roundtrip
# return (round(r.elapsed.total_seconds(), 2), r.status_code)
"""
- 小数点以下 2 桁でレスポンスタイムを返す
- ステータスコードを返す
"""
return (round(roundtrip, 2), r.status_code)
ということで
次は
- HTTP アクセスを並列処理化して処理時間の短縮を目指す
- boto を使って色々な AWS リソースにアクセスしつつ Lambda との連携を模索していきたい
元記事はこちら
「ラムダこりゃ(Amazon Lambda チュートリアル 5)〜 Lambda と Python と Datadog で簡易 HTTP モニターを作る 〜」
