
NO OPSという言葉が嫌いで、サーバレスな時代がきたら、
インフラエンジニアが消えるのではなく
まず運用を意識できない開発者(※1)が消えると思いながら、
サーバレスをcloudpack大阪内で推進する比企です。
NO OPSの話しをしたいのではなく、今回の話しに出る運用を支えるバックエンドがPaaSやFaaSを使っているので少し記載させていただきました。
大阪のMSP開発ではPaaS(FaaS)・SaaSの利用を考えるところから始めます。
運用のコストももちろんですが、開発もコストであるところから、車輪の再発明はしないがキーワードなので、単純にプログラムをガリガリ描きたい方は向いてないかもしれません汗。
というところで今回はPagerDutyの運用からその先の話です。
通常の運用時のPagerDutyの課題として
【cloudpack 大阪 BLOG】pagerduty始めました・・・[イレギュラーな事態が発生した時の対応方法その①] – 雑なA型によるクラウドとモバイルと運営と
や
【cloudpack 大阪 BLOG】pagerduty始めました・・・[イレギュラーな事態が発生した時の対応方法その②] – 雑なA型によるクラウドとモバイルと運営と
などもあり使った所感は下記
PagerDuty始めました 導入から二ヶ月実際のところどうなのPD?【cloudpack 大阪 BLOG】 – 雑なA型によるクラウドとモバイルと運営と
の記載がありますが今回は記載してないお話。
PagerDutyの利用料の増加
PagerDutyは便利ですが、利用者数が多くなると、利用料金がどんどん高くなってきます。
https://www.pagerduty.com/pricing/
普段運用のメンバーはインシデントがエスカレーションされるのでもちろん必須ですが、
運用と構築のメンバーが分かれているケースだと、どんどん人数が増えていくので、
注意が必要です。
構築メンバーPagerDutyを必要とするケースは、
①PagerDutyの設定とテスト
②定期的に確認するインシデントの全体量と傾向
ですが、①は設定も難しくなく、PDの設定自体は10分もいらないので、やるメンバーを集約できますが
②に関しては見る人を減らすわけにはいけないので、
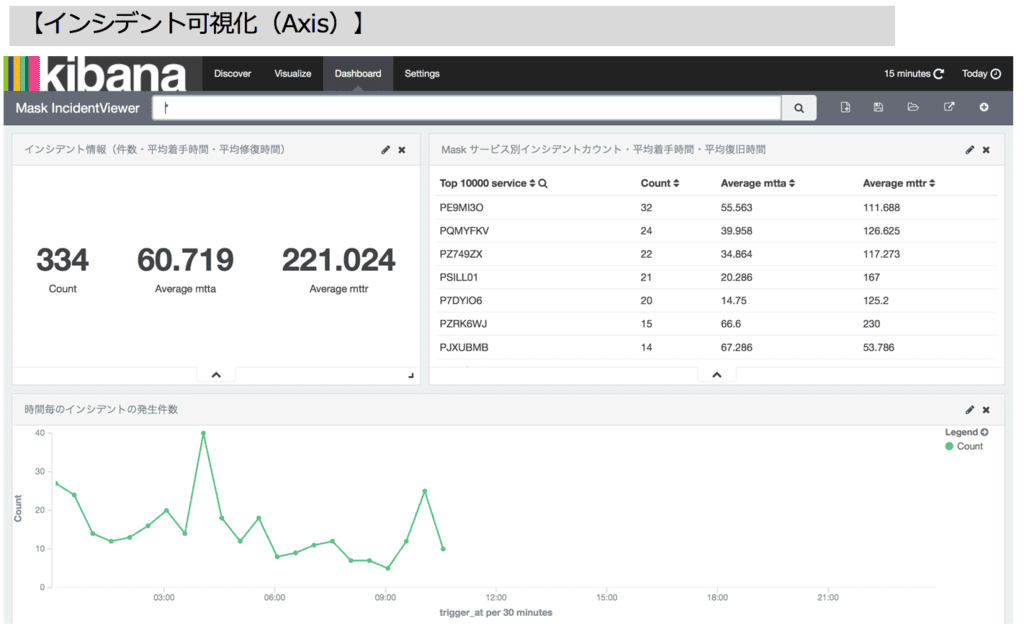
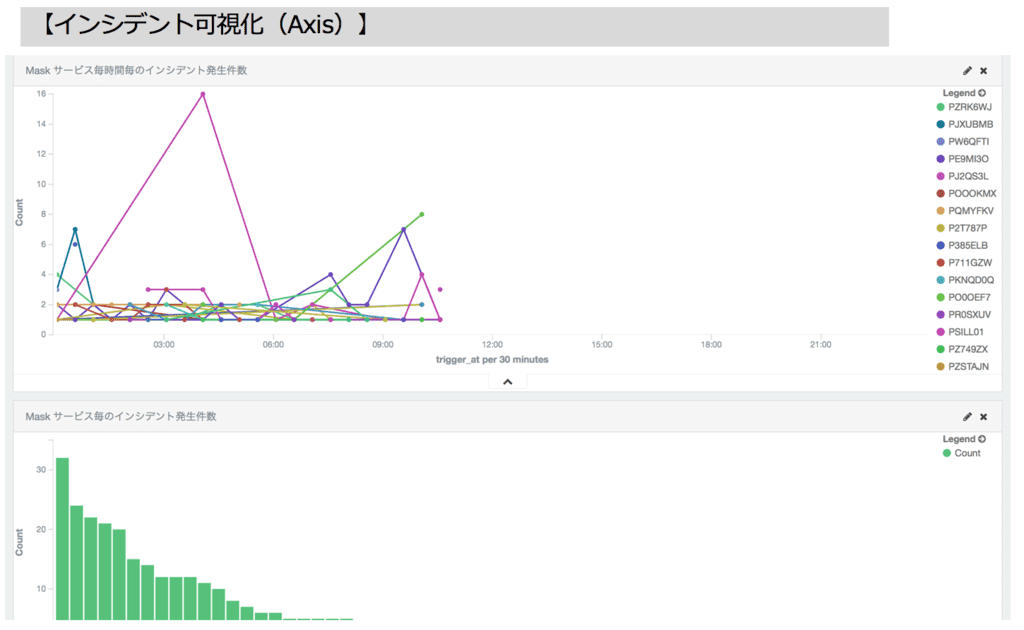
Amazon Elasticsearch Service + kibana にLambdaから定期的にデータを突っ込んで
可視化するようにして、見る為だけのユーザー数を減ら為と、
AWSのMSP資格取得時にも必要となるインシデントの負荷情報のトレース(
毎月のインシデントを出力し、MSPのリーダー達がそれを見て負荷情報を確認・対応する)
の為の情報もPagaerDutyから抜き出せるようにしました(pagerdutyでも分析するモードはあるのですが、エビデンスを残すのは無理なのでエビデンス用の情報にフォーマットを加工して出力する機能も搭載)。
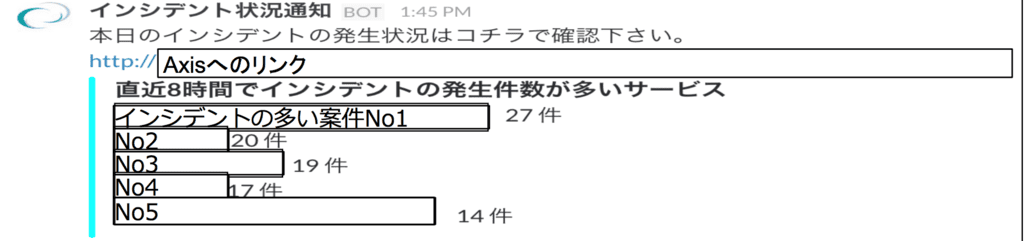
また上記のシステムにより引き継ぎ時の時間帯にslackへの投稿し、直近のインシデントの負荷状況も
次の担当者の引き継ぎを客観的な数字で連携することも可能としました。
PagerDutyの利用者による設定漏れとPagerDutyの瞬間的なサービス不通対応
PagerDutyは便利ですが、設定をミスっていたらもちろんインシデントは登録されません。
またPagerDutyは結構安定していますが、それでも100%のサービスを保証していないので
弊社側でシステムとして保管する必要があります。
そしてアラートメールは必ず飛ぶ設定をしますので、アラートメールをlambdaでhookし、
PagerDutyのインシデント状況をAPIで確認し、登録されてない場合はslackに投稿される&
未設定のインシデントということで、再度PagerDutyに登録してMSPのメンバーにエスカレーションされるように
システムを構築しました。
アラートメールの設定が漏れているとこの仕組みで検知はできませんが、それでも機械的にpagerdutyの設定漏れと
pagerdutyのサービスの漏れをある程度のタイミングで検知できるので、有効に機能しています。
- インシデント管理以外の活用
弊社は通常backlogでお客様とやりとりしていますが、24時間365日一人一人がつきっきりで見ることはできません。
また複数人で対応していますが担当者が未設定でお客様が登録すると漏れやすい状況となります。
なのでlambdaを利用し、担当者が時間外の場合(設定者のみ)、および担当者が未設定のものや担当がMSPグループに設定されたものは
slackとPDに登録されるようにシステムを作りました。
また運用に使っているGoogleカレンダーのイベント情報もPagerDutyへの登録とslackに投稿する(PagerDutyがクローズされた場合は
slackにも出力される&放置されるとslackにリマインド通知が届き、他の方や登録した人が気がつく)機能も実現しました。
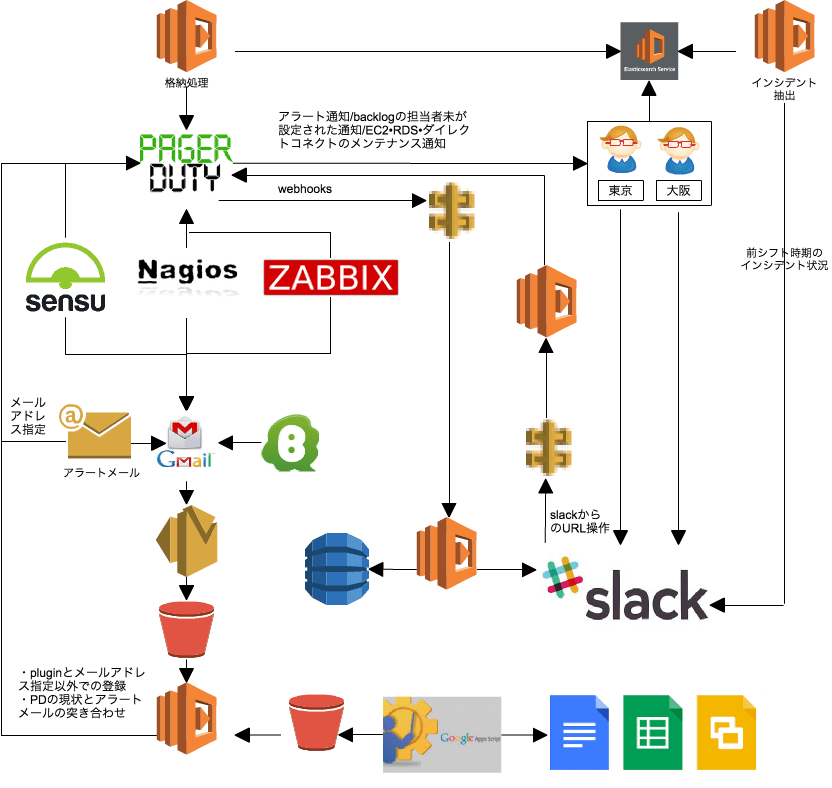
上記を踏まえた現在のシステム構成は下記となります
現在の取り組みとPagerDutyのwebhooksの課題
PagerDutyでの可視化が行われたことにより、自動化やシステムで補助する監視対象が客観的な数字で追えるようになりました。
完全な自動化は車の自動走行と同じく、なかなか心理的な面で厳しい部分もありますし、
自動化ありきのインフラは論理的にはできますが、実際のニーズと違うケースも多々あります。
なので、現在MSP開発チームではPagerDutyのwebhooksをAPI Gateway&Lambdaでhookして、踏み台サーバーを経由して
自動で問題のサーバーに入り、サーバー内部の情報を取得しエビデンスを残したり、コマンドを実行するARAYASHIKIのαテストを開始しています。
この仕組みを利用しいずれAWSのDevice Farm上のiOSやAndroid端末で自動で動作確認を行いそのエビデンスも自動で取得する事も可能となります。
ちなみにARAYASHIKIを実現する時になぜか最初webhooksから登録されていたけど途中から登録されなくなる謎の不具合の遭遇しました。
問題はPagerDutyのwebhooksが3秒以内に応答を返さないとblacklistに登録され、webhooksが無効化されてしまうとの事だったので
pagerdutyに近いと思われるリージョンにAPI GatewayとLambdaの配置をし、Lambdaの中の処理は受付のみで、SNSで再度lambdaを
callするようにしてlambdaの処理時間も最速で非同期で終了するように対応しています。
ちなみにwebhooksの課題は他にもあり下記は特に気をつけたほうがいいです。
さらばHubot さらばEC2。API GatewayとLambdaで始めるMSPのIT化フェイズ3(その1)【cloudpack 大阪 BLOG】 – 雑なA型によるクラウドとモバイルと運営と
こんな活動をtwiter上でつぶやいているのPagerDutyの中の人がわざわざ来てくれて、いろいろと意見交換できて非常に有意義な時間を
過ごしましたが、pagerdutyの世界の利用状況を聴いて、世の中にはまだまだスゲーやつがいるなと再認識させていただきました
(ちなみにプレゼン中に5回スゲーと言っていただきましたw)。
今後はPagerDutyで操作するUIでMSPの方がARAYASHIKIで取得したサーバー情報を見て、作業の対応や問題なければクローズするPDへの
操作とARAYASHIKIの情報をMLに学習させ、作業の半自動/全自動化ができるようになり、
本当に集中したい仕事にMSPのメンバーの方々ができるようになればなと思いながら、
あとはMSP開発のメンバー達に託し、自分は2014年8月からのlambdaの
開発/運用ノウハウをベースに9月からチームとしてサーバレスに取り組んでいきます。
※1 運用を意識できない開発者
NO OPSで言われるのは単純なオペレーションの廃止ですが、そのほとんどは
開発者が運用を意識せずにシステム開発を行い、その業を運用側が代わりに背負って
日々運用しています。
サーバーレスな時代で、”もし”インフラエンジニアが減れば、
運用を意識できない開発者の垂れ流していたアラートがそのまま壮大なブーメランとなって
帰ってきて、それに耐えきれない運用を意識できない開発者が消えていくと思います汗



