
EMRを実行する際メモリが足りないため、エラーになる場合があります。
その対応として、EMRではクラスタのJavaのメモリ指定ができるので試してみました。
EMRはジョブフローを起動するときに、Bootstrapアクションを指定できます。
また、AWSコンソールでジョブフローを起動する場合は、ジョブフロー作成のダイアログ中にBootstrapアクションを
設定できます。
「BOOTSTRAP ACTIONS」のフェーズで「Configure your Bootstrap Actions」を選択すると以下のような画面が
出てきます。
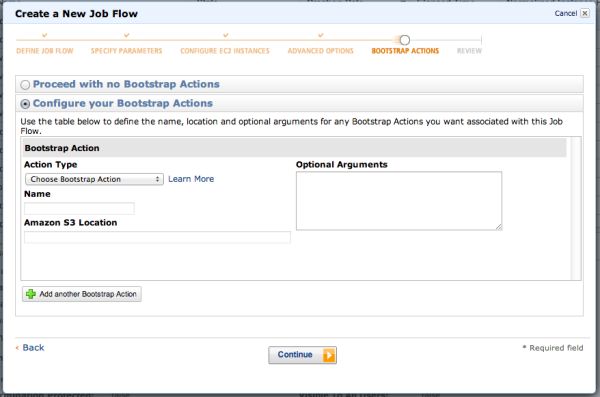
Action Typeにはいくつかあり、監視ツールの「Install Ganglia」や「Memory Intensive Configuration」などの
プリセットとカスタムアクションがあります。
「Amazon S3 Location」欄にS3上のアドレスを記載すると、そこに置かれたシェルスクリプトなどがジョブの
起動時に実行されるようです。
○Memory Intensive Configuration
ここでは、メモリ集中型設定というものを試してみます。
Action Typeから「Memory Intensive Configuration」という項目を選択すると「Amazon S3 Location」欄に
S3アドレスが表示されます。
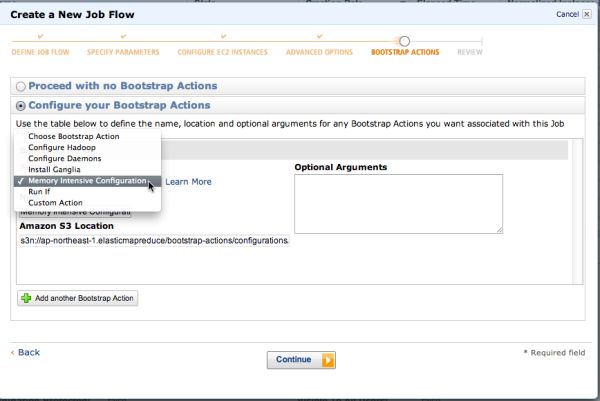
このアドレスに該当するスクリプトを取得すると以下のような内容になっています。
$ curl http://elasticmapreduce.s3.amazonaws.com/bootstrap-actions/configurations/latest/memory-intensive
#!/usr/bin/ruby
## Copyright 2010-2010 Amazon.com, Inc. or its affiliates. All Rights Reserved.
## Licensed under the Apache License, Version 2.0 (the "Liense"). You may not use this file except in compliance with the License.
## A copy of the License is located at http://aws.Amazon/apache2.0/
## or in the "license" file accompanying this file.
## This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
## See the License for the specific language governing permissions and limitations under the License.
require 'json'
require 'hpricot'
require 'tempfile'
CONFIG_HEADER = "n"
conf_fields = [
{ :field => "mapred.child.java.opts={VAR}", :roles => [:slave] },
{ :field => "mapred.tasktracker.map.tasks.maximum={VAR}", :roles => [:master, :slave] },
{ :field => "mapred.tasktracker.reduce.tasks.maximum={VAR}", :roles => [:master, :slave] }
]
configs = {
"m1.small" => ["-Xmx512m", "2", "1"],
"m1.large" => ["-Xmx1024m", "3", "1"],
"m1.xlarge" => ["-Xmx1024m", "8", "3"],
"c1.medium" => ["-Xmx512m", "2", "1"],
"c1.xlarge" => ["-Xmx512m", "7", "2"],
"m2.xlarge" => ["-Xmx3072m", "3", "1"],
"m2.2xlarge" => ["-Xmx4096m", "6", "2"],
"m2.4xlarge" => ["-Xmx4096m", "14", "4"]
}
heap_fields = [
{ :field => "HADOOP_NAMENODE_HEAPSIZE={VAR}", :roles => [:master, :slave] },
{ :field => "HADOOP_JOBTRACKER_HEAPSIZE={VAR}", :roles => [:master, :slave] },
{ :field => "HADOOP_TASKTRACKER_HEAPSIZE={VAR}", :roles => [:master, :slave] },
{ :field => "HADOOP_DATANODE_HEAPSIZE={VAR}", :roles => [:master, :slave] }
]
heaps = {
"m1.small" => ["512", "512", "256", "128"],
"m1.large" => ["1024", "3072", "512", "512"],
"m1.xlarge" => ["3072", "9216", "512", "512"],
"c1.medium" => ["512", "768", "256", "128"],
"c1.xlarge" => ["1024", "2048", "512", "512"],
"m2.xlarge" => ["2048", "4096", "512", "512"],
"m2.2xlarge" => ["2048", "8192", "1024", "1024"],
"m2.4xlarge" => ["8192", "8192", "1024", "1024"]
}
def parse_config_file(config_file_path)
ret = []
if File.exist?(config_file_path) then
doc = open(config_file_path) { |f| Hpricot(f) }
(doc/"configuration"/"property").each do |property|
val = {:name => (property/"name").inner_html, :value => (property/"value").inner_html }
if (property/"final").inner_html != "" then
val[:final] = (property/"final").inner_html
end
ret end
else
puts "#{config_file_path} does not exist, assuming empty configuration"
end
return ret
end
def dump_config_file(file_name, config)
open(file_name, 'w') do |f|
f.puts CONFIG_HEADER
f.puts '' '
for entry in config
f.print "' #{entry[:name]} #{entry[:value]} "
if entry[:final] then
f.print "#{entry[:final]} "
end
f.puts '
end
f.puts '
end
end
def merge_config(default, overwrite)
for entry in overwrite
cells = default.select { |x| x[:name] == entry[:name]}
if cells.size == 0 then
puts "'#{entry[:name]}': default does not have key, appending value '#{entry[:value]}'"
default elsif cells.size == 1 then
puts "'#{entry[:name]}': new value '#{entry[:value]}' overwriting '#{cells[0][:value]}'"
cells[0].replace(entry)
else
raise "'#{entry[:name]}': default has #{cells.size} keys"
end
end
end
def do_overwrites(conf_list, heap_list)
file = "/home/hadoop/conf/mapred-site.xml"
default = parse_config_file(file)
for arg in conf_list
puts "Processing default file #{file} with overwrite #{arg}"
key = arg.split('=', 2)[0]
value = arg.split('=', 2)[1]
overwrite = [{:name => key, :value => value }]
merge_config(default,overwrite)
end
dump_config_file(file + ".new", default)
if File.exist?(file) then
File.rename(file, file + ".old")
end
File.rename(file + ".new", file)
puts "Saved #{file} with overwrites. Original saved to #{file}.old"
file = "/home/hadoop/conf/hadoop-user-env.sh"
if File.exist?(file) then
File.delete(file)
end
open(file, 'w') do |f|
f.puts "#!/bin/bash"
for arg in heap_list
f.puts arg
end
end
end
class JsonInfoFile
INFO_DIR = "/mnt/var/lib/info/"
def initialize(file_type)
@json = JSON.parse(File.read(File.join(INFO_DIR, file_type + ".json")))
end
def [](json_path)
json = @json
begin
path = json_path.split('.')
visited = []
for item in path
if !json.kind_of? Hash then
raise "#{visited.join('.')} not of type object, got '#{json.inspect}' from #{@json.inspect}"
end
visited json = json[item]
end
if json == nil then
raise "#{visited.join('.')} does not exist"
end
return json
rescue
puts "Unable to process path '#{json_path}', #{$!}"
exit -1
end
end
end
def warn(msg)
STDERR.puts "#{Time.now.utc} WARN " + msg
end
def substitute_in(row, fields, instance_role)
if row.size != fields.size then
raise RuntimeError, "Incompatible row and field list row=#{row}, fields=#{fields}"
end
result = []
for index in 0 ... row.size do
if fields[index][:roles].include?(instance_role) then
result end
end
return result
end
HPC_INSTANCE_TYPES = [ "cc1.4xlarge", "cg1.4xlarge" ]
jobflow_info = JsonInfoFile.new("job-flow")
instance_info = JsonInfoFile.new("instance")
if instance_info['isMaster'].to_s == 'true' then
instance_type = jobflow_info["masterInstanceType"]
instance_role = :master
else
instance_group_id = instance_info['instanceGroupId']
instance_groups = jobflow_info['instanceGroups']
index = instance_groups.index { |g| g['instanceGroupId'] == instance_group_id }
instance_group = instance_groups[index]
instance_type = instance_group['instanceType']
instance_role = :slave
end
if HPC_INSTANCE_TYPES.include?(instance_type) then
warn "This bootstrap action is not supported for the HPC instances (cc1.4xlarge and cg1.4xlarge)"
else
conf_list = substitute_in(configs[instance_type], conf_fields, instance_role)
heap_list = substitute_in(heaps[instance_type], heap_fields, instance_role)
do_overwrites(conf_list, heap_list)
end
上記は、RUBYスクリプトのようです。
このスクリプトではインスタンスサイズに応じてネームノード、JobTracker、TaskTracker、データノードに対して、
メモリ集中型のヒープサイズをそれぞれの環境変数に設定するように下記を上書きしています。
/home/hadoop/conf/hadoop-user-env.sh
/home/hadoop/conf/hadoop-env.sh
そして、hadoop-user-env.shは上記から以下のように読み込まれ、ジョブ実行時に実行される仕組みのようです。
#!/bin/bash
export HADOOP_DATANODE_HEAPSIZE="96"
export HADOOP_NAMENODE_HEAPSIZE="192"
export HADOOP_JOBTRACKER_HEAPSIZE="576"
export HADOOP_TASKTRACKER_HEAPSIZE="192"
export HADOOP_OPTS="$HADOOP_OPTS -server"
if [ -e /home/hadoop/conf/hadoop-user-env.sh ] ; then
. /home/hadoop/conf/hadoop-user-env.sh
fi
これがメモリ集中型の場合、下記のようになるようです。
- HADOOP_JOBTRACKER_HEAPSIZE:512
- HADOOP_NAMENODE_HEAPSIZE:512
- HADOOP_TASKTRACKER_HEAPSIZE:256
- HADOOP_DATANODE_HEAPSIZE:128
ネームノードにより多くのメモリが割り当てられるようです。
これで実行すると、新しいメモリ割り当ての設定でジョブが実行されます。
○Custom Action
プリセット以外にも、「Custom Action」という自由にスクリプトなどをアップできるオプションもあります。
「Amazon S3 Location」欄に自分でアップしたスクリプトファイルのS3アドレスを入力します。
ここでは、例としてs3://memorycraft-emr/script/heap.sh として以下のファイルアップしておきます。
前述のMemory Intensive Configurationではインスタンスごとに決め打ちのヒープサイズが自動で適用されましたが、
このように自分で各ヒープサイズを指定するように hadoop-user-env.shを作るようなスクリプトを書くことも
できます。
#!/bin/bash
echo "export HADOOP_JOBTRACKER_HEAPSIZE=512" > /home/hadoop/conf/hadoop-user-env.sh
echo "export HADOOP_NAMENODE_HEAPSIZE=768" >> /home/hadoop/conf/hadoop-user-env.sh
echo "export HADOOP_TASKTRACKER_HEAPSIZE=256" >> /home/hadoop/conf/hadoop-user-env.sh
echo "export HADOOP_DATANODE_HEAPSIZE=128" >> /home/hadoop/conf/hadoop-user-env.sh
そして、以下のようにS3アドレスを入力します。
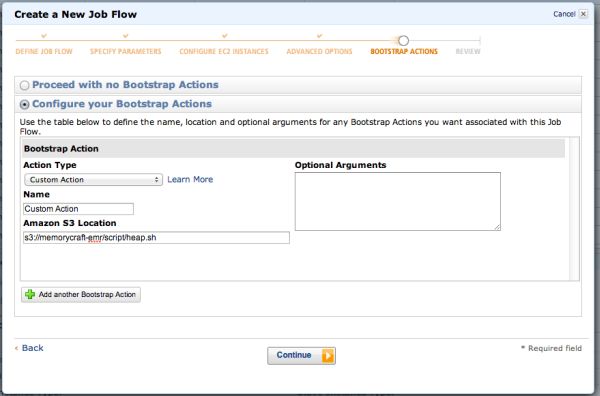
あとは、通常通り実行します。
インスタンスサイズは上げたくないがOutOfMemoryを回避したいという場合には、
まずこのようにBootstrapActionで調整してみるといいと思います。
また、Bootstrap設定はSDKなどのAPI経由のジョブフロー起動時にも行うことが可能です。
.... 略 .....
'AmiVersion' => 'latest',
'LogUri' => "$LOG_BUCKET_LOCATION",
'BootstrapActions' => array(
array(
'Name' => 'Custom Action',
'ScriptBootstrapAction' => array(
'Path' => 's3://memorycraft-emr/script/heap.sh',
),
),
),
'Steps' => array(
new CFStepConfig(array(
.... 略 .....
メモリ設定以外にも処理前に自由に処理を挿入できるので、カスタム処理を行ったり、実行環境を最適化できるので、
いろいろと便利そうです。
こちらの記事はなかの人(memorycraft)監修のもと掲載しています。
元記事は、こちら