
- フルマラソンは 30 キロからが難しい
- 解析結果
— 5KM ラップタイムの遷移で見る 3 時間を切る人と切れない人
—– 平均
—– 上位 10 人
—– ギリギリサブスリーの 10 人
—– サブスリーまでもうひと頑張りの 10 人
—– 見解
— フルマラソンは 30 キロからが難しい
—– 最初 の 5 キロ
—– 10キロ
—– 15キロ
—– 20キロ
—– 25キロ
—– 30キロ
—– 35キロ
—– 40キロ
—– 後半15 キロのラップタイムの落ち込み
—– 見解 - 5000人分の結果を csv ファイルに
— 結果の取得
— Pandas ライブラリ
— 5000 人分の結果を csv ファイルに - ということで
— サブスリーに向けて
— Python + Pandas
フルマラソンは 30 キロからが難しい
と言われていますが、本当なのか、そして、俺は何がダメで 3 時間を切れなかったかをランナーズアップデートで公開されている選手 5000 人の結果を利用して分析してみました。
p.kyoto-marathon.com
先日、走ってきた京都マラソン 2017 の結果を利用させて頂きます。
解析結果
5KM ラップタイムの遷移で見る 3 時間を切る人と切れない人
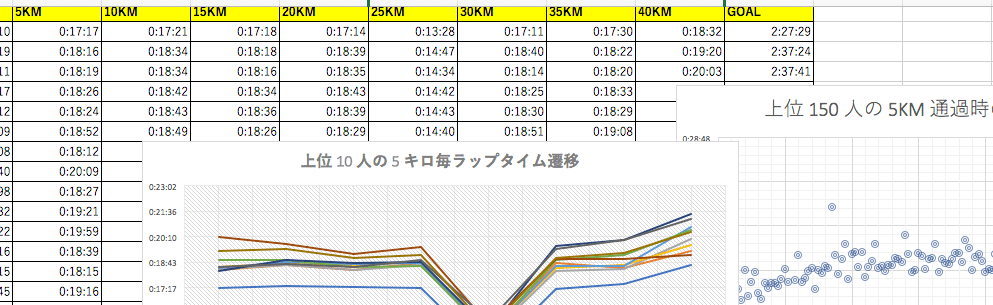
平均
まずは 5 KM ラップタイムを上位 10 人、ギリギリサブスリー 10 人、サブスリーまでもうひと頑張りの 10 人の各セグメントで平均を取って比較してみました。
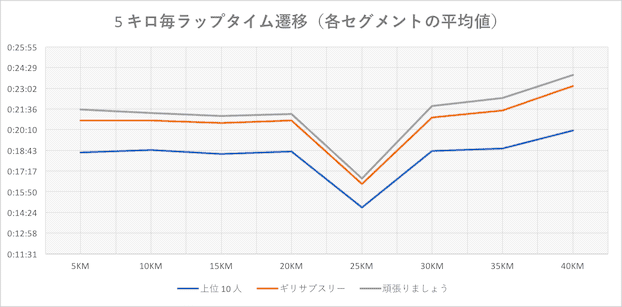
上位 10 人
ゴールタイムは 2 時間 27 分〜 2 時間 43 分までの上位選手 10 人分。(25 キロは距離が短いので時間が短くなっている)
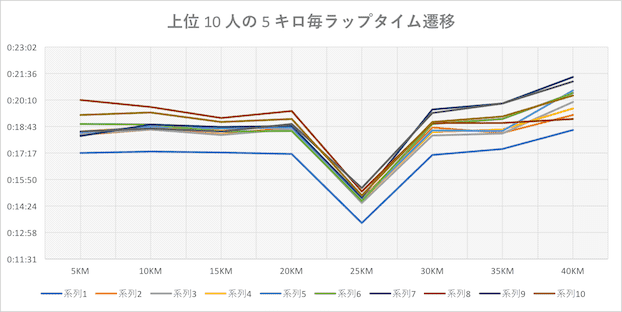
ギリギリサブスリーの 10 人
ゴールタイムは 2 時間 59 分台の選手 10 人分。(25 キロは距離が短いので時間が短くなっている)
サブスリーまでもうひと頑張りの 10 人
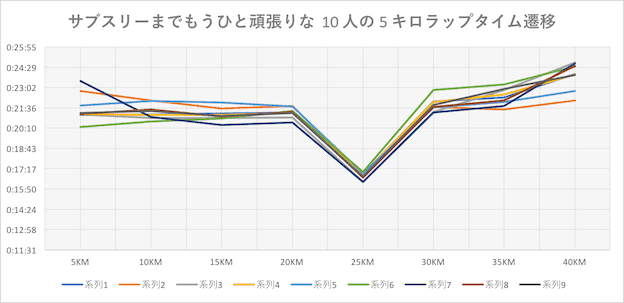
ゴールタイムは 3 時間 5 分台の選手 10 人分。(25 キロは距離が短いので時間が短くなっている)
見解
- 上位 10 人は最初の 5KM通過時 と 40KM 通過時のラップタイムの差が小さい
- サブスリーまでもうひと頑張り必要な人は最初の 5KM 通過時と後半の 5KM のラップタイムの差が大きい
- 3 時間切れない人は一定したペースで 40KM 走りきる為の走力が備わっていないことが考えられる
- 19 〜 21 分/5KMくらいの間でおさまるように走り切ることが出来ればサブスリー
フルマラソンは 30 キロからが難しい
最初の 5 キロ
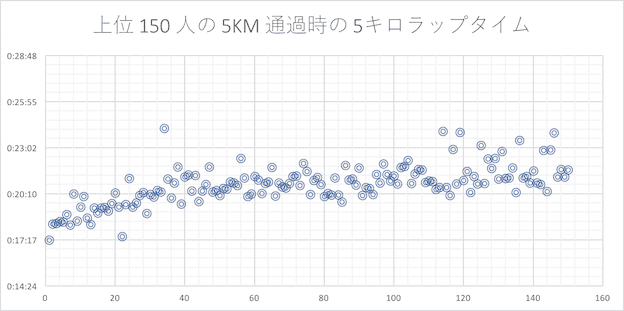
最初の 5 キロはバラつきが多い。スタート直後なので自分のペースを探りながら走っているランナーが多いと思われます。(左にいくほど記録が良いランナー)
10 キロ
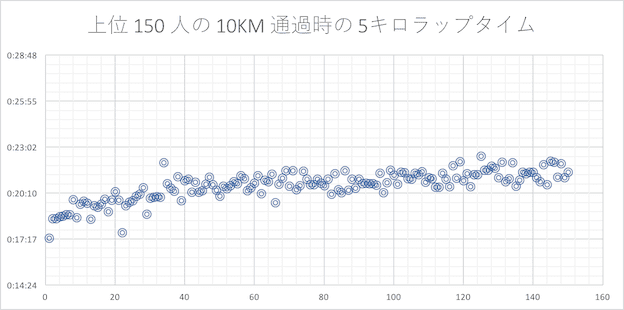
10 キロになるとペースが落ち着いてきています。(左にいくほど記録が良いランナー)
15 キロ
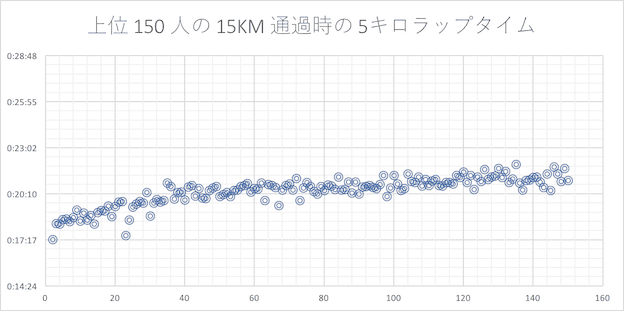
15 キロ以降は各ランナーは自分のペースを掴んで安定したペースで走り始めます。
20 キロ
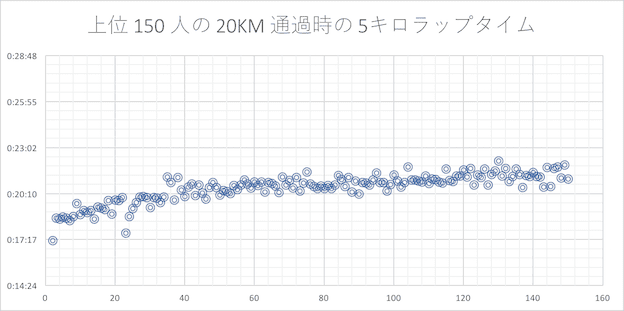
25 キロ
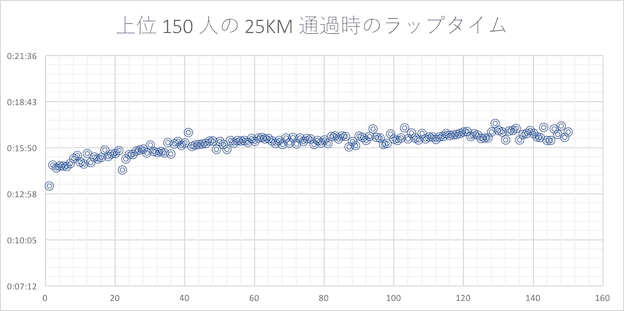
30 キロ
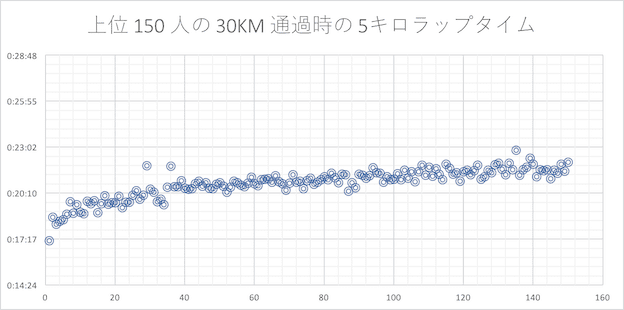
フルマラソンの鬼門、30 キロ以降、各ランナーのペースが少しずつ乱れはじめているのがわかります。
35 キロ
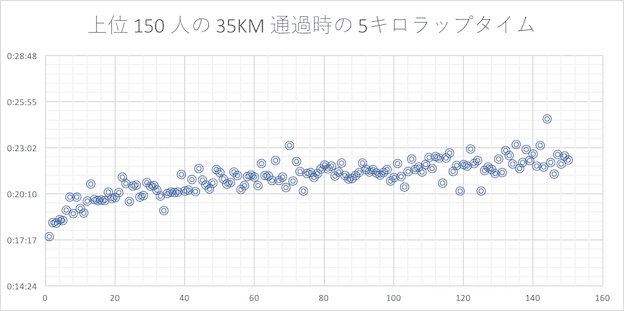
40 キロ
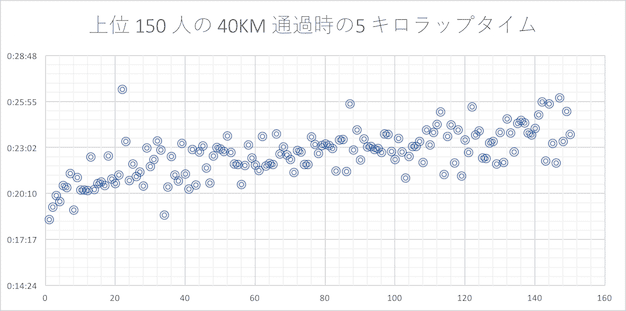
35 キロ以降、最後の 10 キロに走力の差が歴然と出て来るように見えます。走力のある選手もラップタイムが下がってきてはいますが、ゴールタイムが遅くなる選手ほど最後の 5 〜 10 キロのタイムがそれまでの 5 キロと比べると下振れが大きくなっている(遅くなっている)ようです。逆に走力のある選手はタイムが上がっている選手もチラホラ見られます。
後半 15 キロのラップタイムの落ち込み

5 KM ラップタイムを上位 10 人、ギリギリサブスリー 10 人、サブスリーまでもうひと頑張りの 10 人の各セグメントで平均の平均を取り、最初の 5KM 通過時のタイムと 30KM と 35KM 及び 40KM 通過時の 5KM ラップの差分を比較してみました。40KM までの 5KM ではトップ選手でもラップタイムが落ち込んでしまっていることがわかります。但し、トップ選手の落ち込みよりも走力の低い選手の落ち込みが大きいように見られます。
見解
- 通説通り、30 キロ以降は大体のランナーがラップタイムが下振れする(遅くなる)
- 記録が芳しくないランナー(走力が無いランナー)程 30 キロ以降のラップタイムが大きく下振れする傾向が見られる
5000 人分の結果を csv ファイルに
結果の取得
ランナーズアップデートは各選手のゼッケン番号毎のページが存在していて、以下のように curl や wget を使えばページの HTML を取得することが出来ました。
wget http://p.kyoto-marathon.com/numberfile/10265.html -O 10265.html
但し、頻度の高いアクセスは控えましょう。
実際の結果ページは以下のようなページです。
Pandas ライブラリ
Pandas というライブラリを使えば HTML ファイルを解析して、テーブルデータに以下のようにアクセス出来るようになります。
$ python
Python 3.6.0 (default, Dec 24 2016, 07:27:52)
[GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.38)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas
>>> url = 'http://p.kyoto-marathon.com/numberfile/10265.html'
>>> df = pandas.io.html.read_html(url)
>>> df[0]
0 1 2 3
0 地点名Point スプリット (ネットタイム)Split (Net Time) ラップLap 通過時刻Time
1 5km 00:23:45 (0:23:31) 0:23:31 09:23:45
2 10km 00:44:43 (0:44:29) 0:20:58 09:44:43
3 15km 01:05:07 (1:04:53) 0:20:24 10:05:07
4 20km 01:25:41 (1:25:27) 0:20:34 10:25:41
5 中間点 01:30:08 (1:29:54) 0:04:27 10:30:08
6 25km 01:46:28 (1:46:14) 0:16:20 10:46:28
7 30km 02:07:45 (2:07:31) 0:21:17 11:07:45
8 35km 02:29:29 (2:29:15) 0:21:44 11:29:29
9 40km 02:54:14 (2:54:00) 0:24:45 11:54:14
10 Finish 03:05:17 (3:05:03) 0:11:03 12:05:17
>>>
各要素へのアクセスは以下のように。
>>> df[0][1] 0 スプリット (ネットタイム)Split (Net Time) 1 00:23:45 (0:23:31) 2 00:44:43 (0:44:29) 3 01:05:07 (1:04:53) 4 01:25:41 (1:25:27) 5 01:30:08 (1:29:54) 6 01:46:28 (1:46:14) 7 02:07:45 (2:07:31) 8 02:29:29 (2:29:15) 9 02:54:14 (2:54:00) 10 03:05:17 (3:05:03) Name: 1, dtype: object
5000 人分の結果を csv ファイルに
wget で取得した 5000 人分のデータを以下のように csv ファイルに書き出しました。
import glob
import pandas
import csv
with open('output.csv', 'a') as c:
writer = csv.writer(c, lineterminator='\n')
file_list = glob.glob('./*.html')
for file in file_list:
bib_number = file.split('.')[-2].split('/')[-1]
# print(bib_number)
with open(file, 'r') as file:
table = pandas.io.html.read_html(file.read())
column = []
for value in table[0][2]:
column.append(value)
# 途中でリタイヤした人対応
if len(table[0][1]) == 11:
column.append(table[0][1][10].split('\u3000')[0])
column.insert(1, bib_number)
print(column[1:])
writer.writerow(column[1:])
ということで
サブスリーに向けて
現時点で走力が無い自分がどうするべきか。
- 20 〜 21 分/5KM で走りきるように頑張る
- 後半の落ち込みを考えると 19 分台で走れればなお良し
- 京都マラソンでは前半の 5 KM が 23 分掛かっているので、最初から 20 分台、21 分台で押せるように心がける(トイレ注意)
Python + Pandas
ちょー便利です。
元記事はこちら
「フルマラソンは 30 キロからが難しいということを Python + Pandas と Excel で理解する(京都マラソン 2017 の結果を利用して)」

