
GlusterFSとは?
GlusterFSはGluster Server上に存在するPhysical disk上にbrickと呼ばれる格納領域を作成(実態はdirectory)し
これをGluster Clientにてbrickを複数個束ねる事でLogical diskを構成しFUSEを通してNativeなVolume accessを提供する仕組み
以下に基本的なGlusterFSのVolume構成をしめす
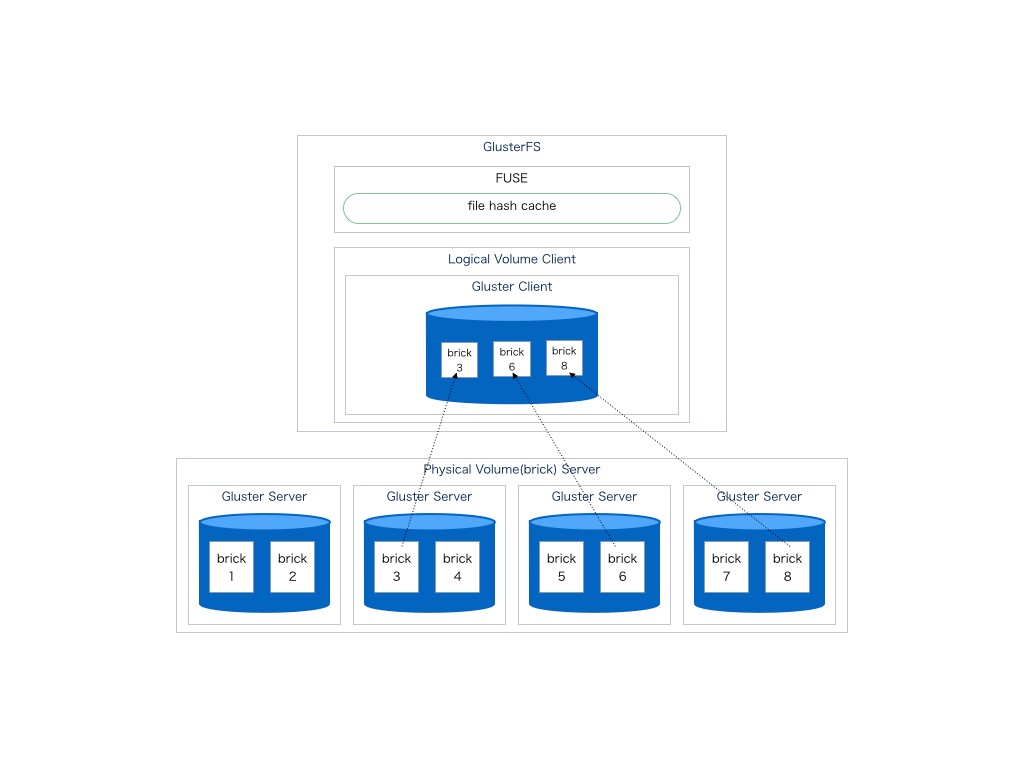
ここでは4つのサーバー上のストレージを各々brickに分けてbrick3,6,8をクライアントにて一つのストレージとして束ねている。
特徴
- Scalableである
- 冗長化が可能である
- 負荷分散機能は存在する
作成できる論理ボリュームの種類
- Distributed Volume(分散)
- Replicated Volume(冗長)
- Striped Volume(分割)
Distributed volume構成
Writing
ここではDistributed volumeの構成に関して図説し併せてGlusterFSに対しての一般的な書き込みの簡単な流れを図とともに記す。
図説にてわかるようにGlusterFSに対して行われた書き込みはFUSEにて作成されたファイルシステムを用いて行われる。
FUSEは最初にファイル名からhashを作成しこのhashと書き込み先のbrickを紐付ける事でbrickの場所を記憶して行く
この時、FUSEは生成されたhashをFileSystemのインデックスとしてキャシュしていく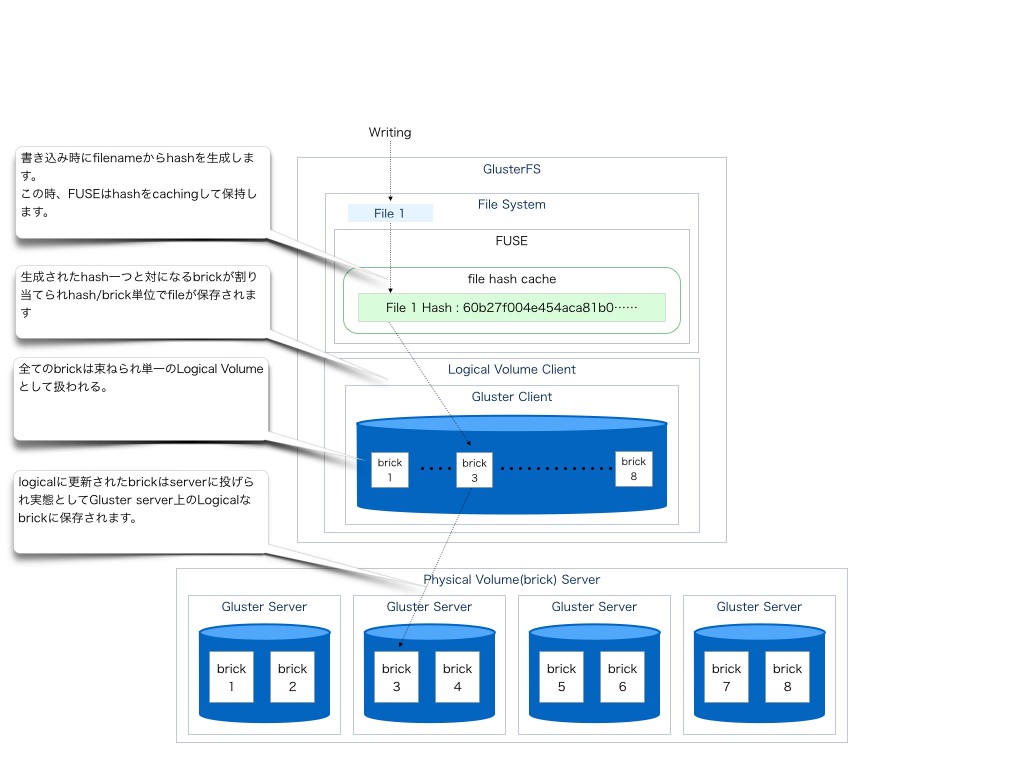
Reading
読み込み際はFUSEのキャッシュからファイルのhashを得てbrickの場所を割り出し迅速にアクセスに行く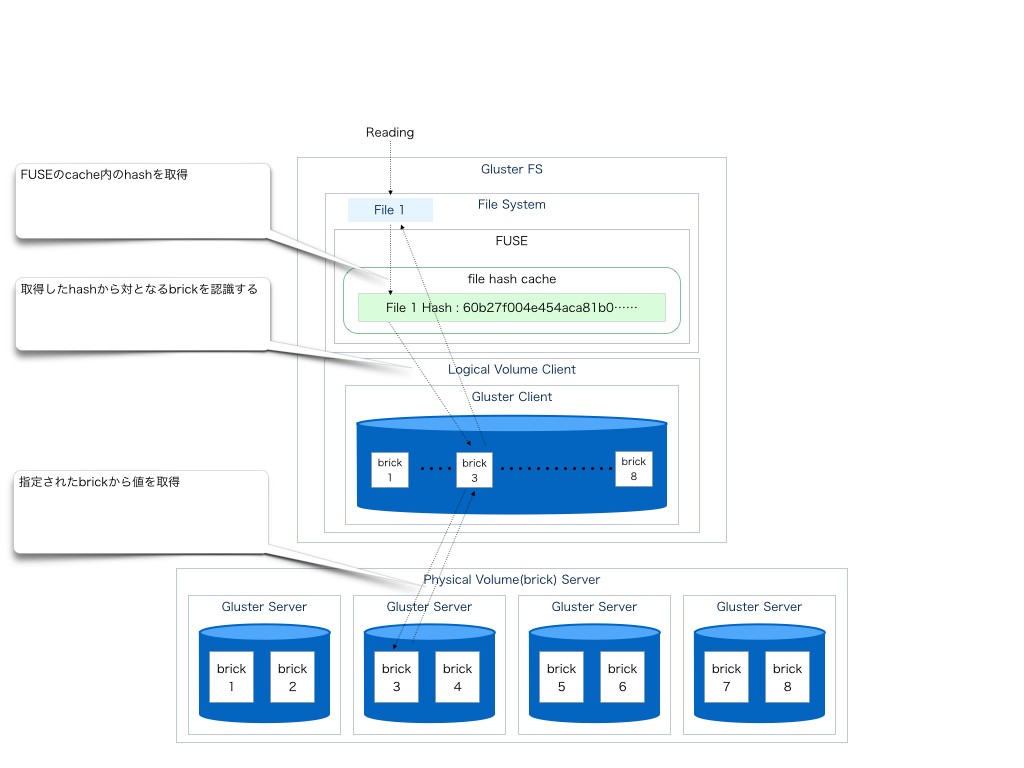
問題のある構成
以下の構成は分散されたbrickサーバーを2つのクライアントからアクセスを行うために
FUSEを含んだGlusterFSクライアントを2つ用意した上でそれぞれに同じbrick構成で論理ボリュームを作成してmountしたものである。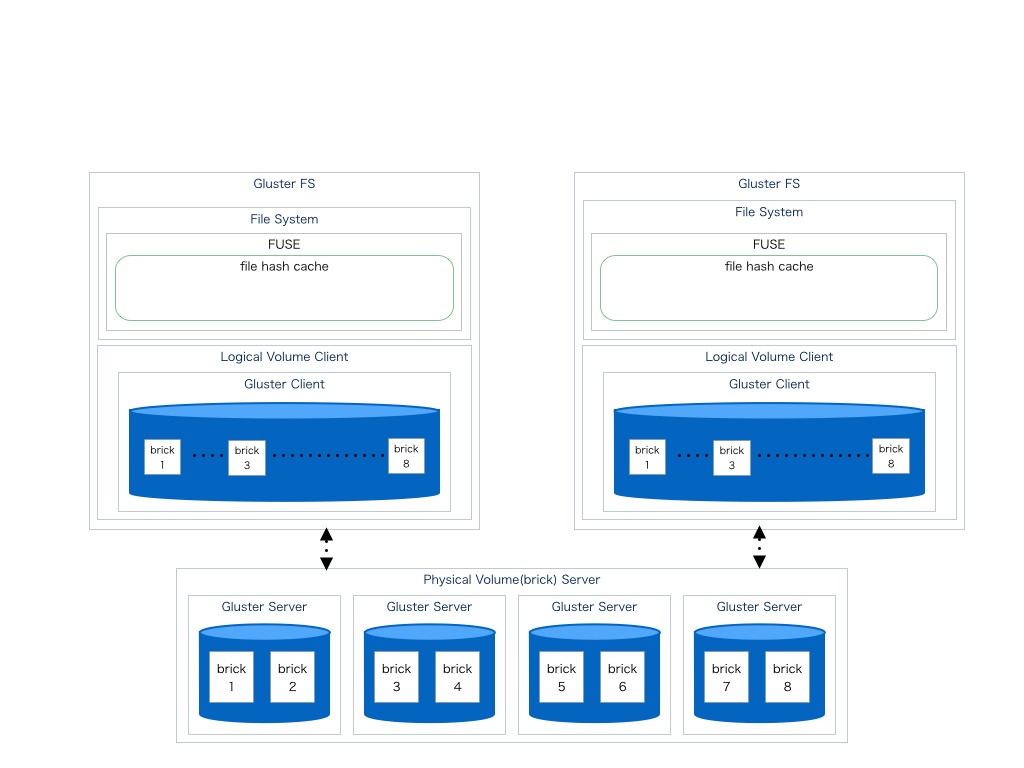
この構成は一見、問題なく動作するように思える。
Writing
まず、片方のクライアントから書き込みを行う。
前述と同じくファイル名をhashとしてキャッシュしbrickにファイルを書き込み保存される。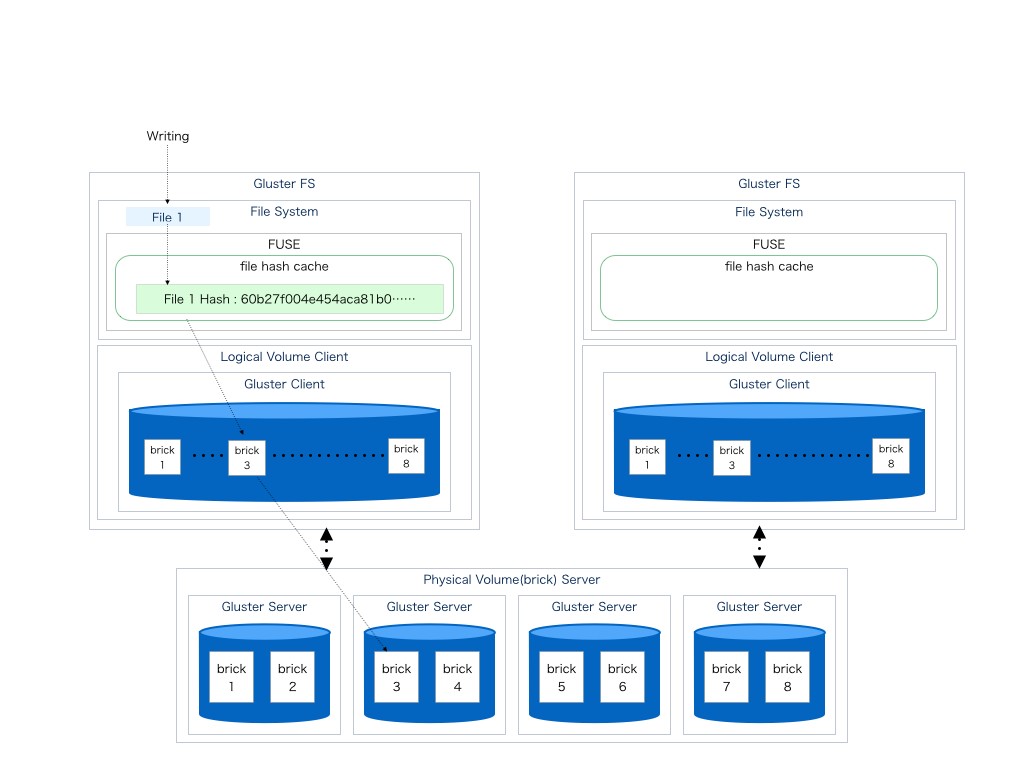
Reading
ここで、もう片方のクライアントから読み込みを行う
ここで問題が発生する。
この時、読み込みに利用するFUSEからは書き込みが行われていないため
FUSEはファイルシステムのキャッシュを保持していない。
当然、キャッシュが無いためFUSE上が提供するFileSystemはそこにファイルが存在しないと返す。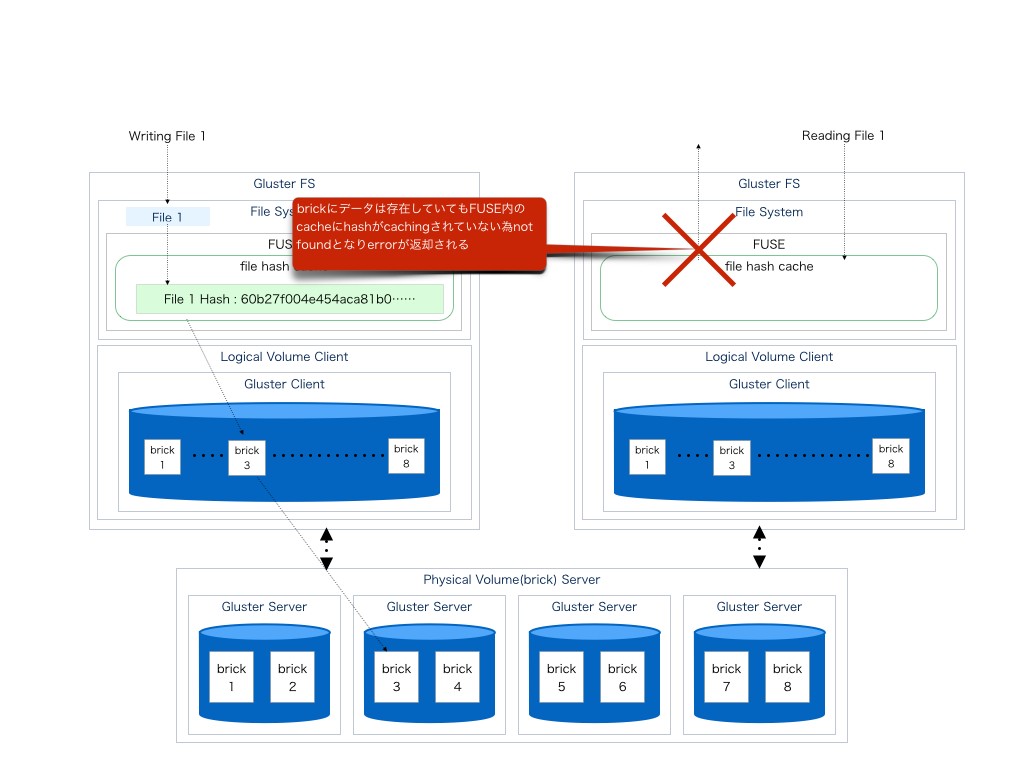
findにてhashを作る
では、FUSE内にhashを保持していないクライアントからアクセスを行う(hashをキャッシュする)にはどうするかというとfindをかければ良い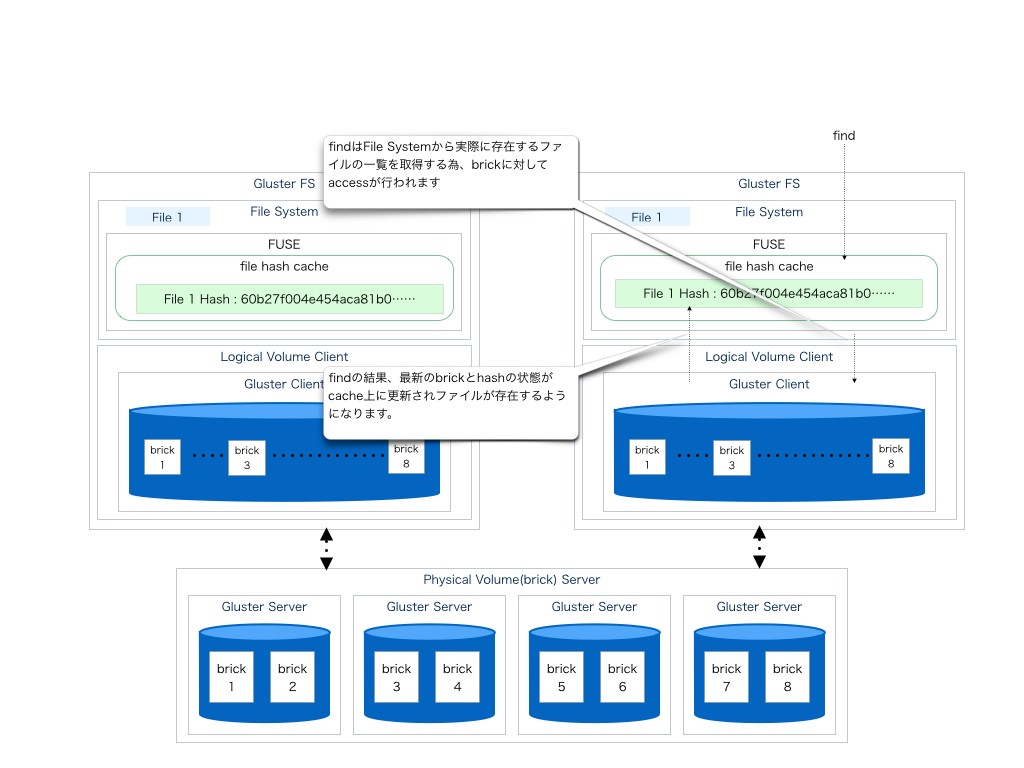
これは、findをかける事でFileSytemを嘗める為、FUSEは最新のファイル一覧をキャッシングする為、brick内に存在したファイルがキャッシュ内に追加される為である。
対応策
samba/nfs経由での対応策
あくまでFUSEを単体として管理を行いmulti user / multi clientに関してはsamba/ nfs等の共有システムに任せる事で問題を回避する方法論
そのためか、GlusterFSのcommunityもsamba等にplugin対応を行っている。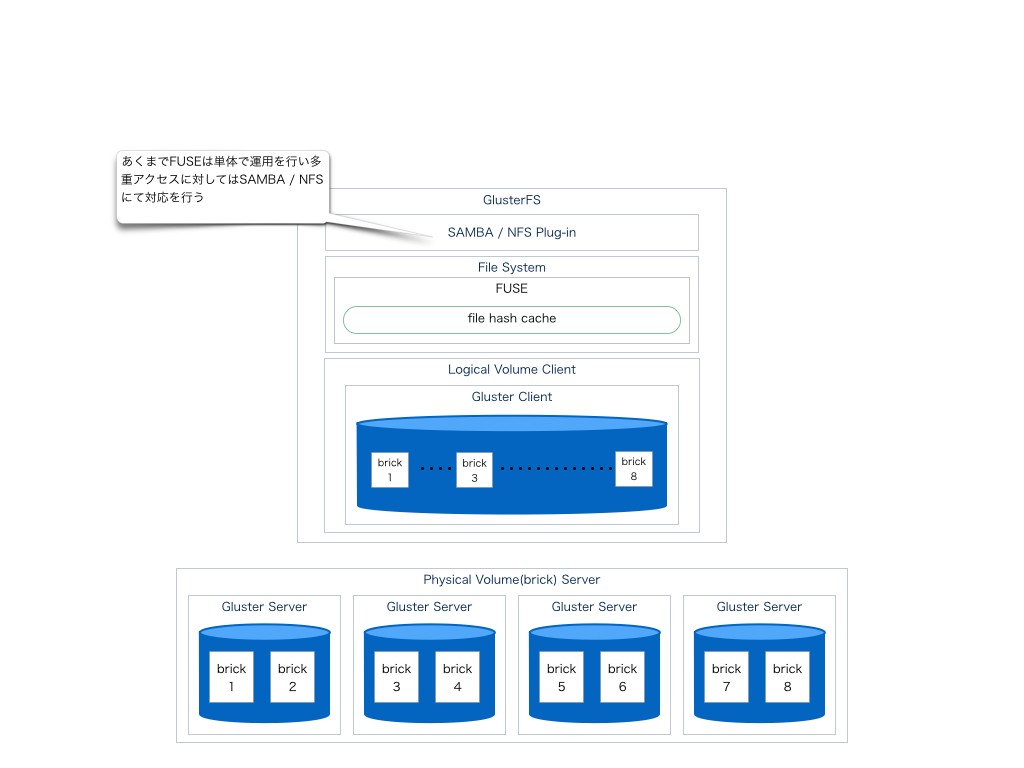
samba/nfs経由の問題
ここで新たに問題が発生する。
sambaに対してI/Oを担うclientが障害点になり得る事
更にI/OはFUSEをあくまで通して行われており、一度カーネル空間からユーザー空間を経由してアクセスが発生する為、オーバーヘッドが極めて大きい。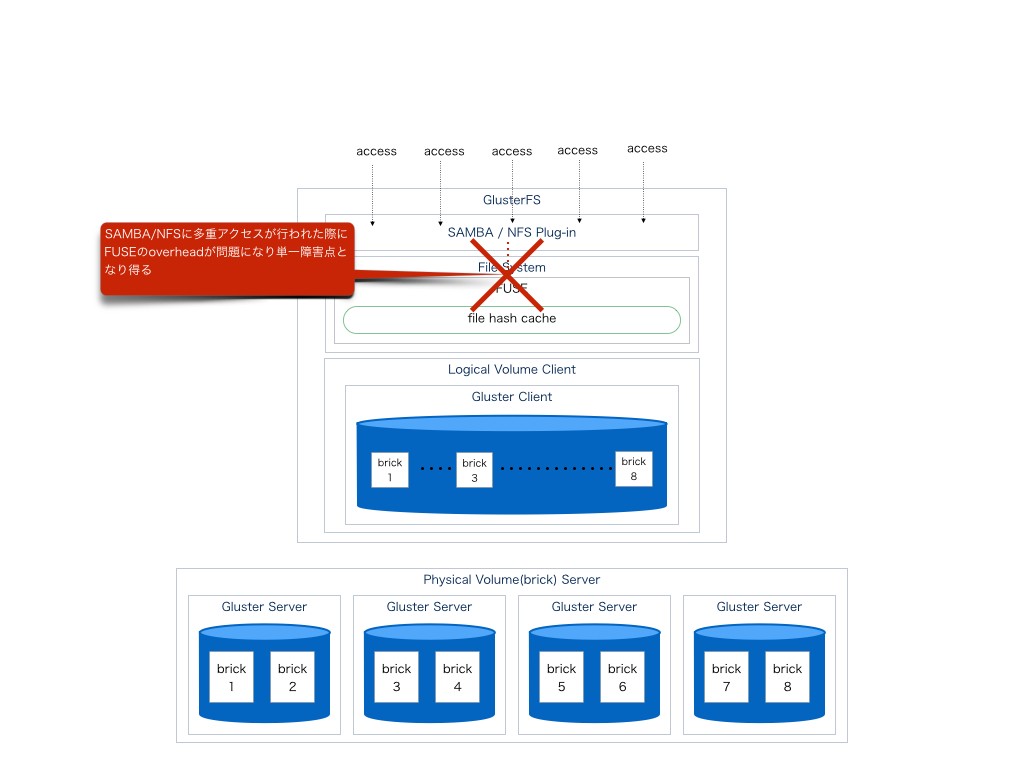
そもそもFUSEを経由しない
この方法であればFUSEを使用しないのでオーバーヘッドもなく、単一障害も発生せず
キャッシュによるブロッキング問題も発生しない。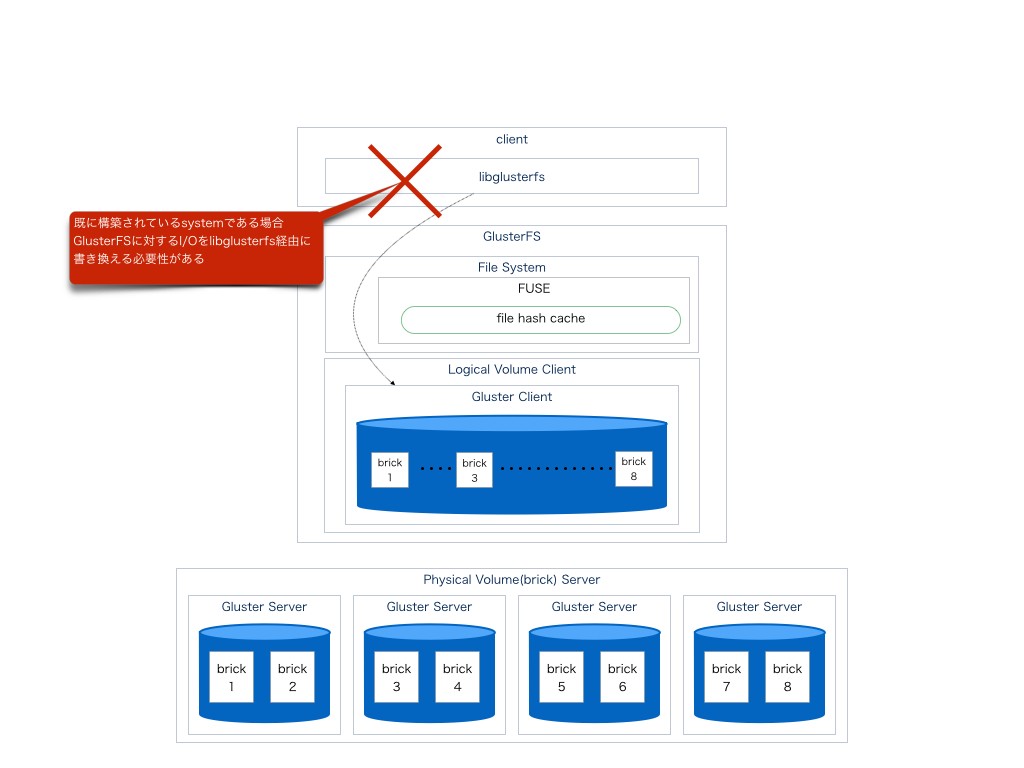
ただ、何もかも良いことがないように困った点もある。
GlusterFSにてFUSEを経由せずにアクセス行う際にはlibglusterfsを使用するように記載されている。
つまり、もし既にシステムを構成してアプリケーションを開発済みの場合はこれを書き換えて修正する必要性があると言うことになる。
総論
- FUSEを通す限り、fileの整合性、I/Oのoverheadに問題を内在し続ける。
- FUSEを通さない場合はclient開発時にlibglusterfsを通す必要性が生じる
- 上記の理由により敢えてGlusterFSを用いるより可能であればAmazon S3やXtreemFS等の代替のproductを用いる方がenterprise用途としては可用性が高い
元記事は、こちら