下記記事を参考にほぼほぼやりたいことはできたのですが、ハマったのでメモ。
[jq] JSONデータの特定階層にあるキー名のユニーク値を取得 – Qiita
https://qiita.com/withelmo/items/b0e1ffba639dd3ae18c0
JSONファイル
行ごとにキーが同じだったり、違ったり、数も違うちょっと困ったJSONファイルがあるときに使えます。
hoge.json
{"hoge1": "hoge", "hoge2": 2, "hoge3": false}
{"hoge2": "hoge", "hoge3": 2, "hoge4": false, "hoge5": "FOO"}
{"hoge1": "hoge", "hoge2": 2, "hoge6": false}
いい感じのコマンド
> cat hoge.json | jq -s -r '[ .[] | keys ] | flatten | unique | .[]' hoge1 hoge2 hoge3 hoge4 hoge5 hoge6
jq の-sオプションで配列にする
ファイル中に{...}{...}{...} と[]括りされず、,区切りもないため、jqの--slurp (-s)オプションで配列に放り込みます。
jq Manual (development version)
https://stedolan.github.io/jq/manual/
--slurp/-s:
Instead of running the filter for each JSON object in the input, read the entire input stream into a large array and run the filter just once.
(Google翻訳)入力内の各JSONオブジェクトに対してフィルターを実行する代わりに、入力ストリーム全体を大きな配列に読み取り、フィルターを1回だけ実行します。
# -s オプションなし
> cat hoge.json | jq
{
"hoge1": "hoge",
"hoge2": 2,
"hoge3": false
}
{
"hoge2": "hoge",
"hoge3": 2,
"hoge4": false,
"hoge5": "FOO"
}
{
"hoge1": "hoge",
"hoge2": 2,
"hoge6": false
}
# -s オプションあり
> cat hoge.json | jq -s
[
{
"hoge1": "hoge",
"hoge2": 2,
"hoge3": false
},
{
"hoge2": "hoge",
"hoge3": 2,
"hoge4": false,
"hoge5": "FOO"
},
{
"hoge1": "hoge",
"hoge2": 2,
"hoge6": false
}
]
キー名だけ出力する
あとは上記記事と同じく[ .[] | keys ] | flatten | uniqueでキー名を取得、平坦化して重複を取り除きます。
ちなみに平坦化しないとこんな感じになります。uniqueが効きません。
> cat hoge.json | jq -s -r '[ .[] | keys ] | unique'
[
[
"hoge1",
"hoge2",
"hoge3"
],
[
"hoge1",
"hoge2",
"hoge6"
],
[
"hoge2",
"hoge3",
"hoge4",
"hoge5"
]
]
最後に.[]で出力し、jqコマンドの--raw-output(-r)オプションでダブルクォーテーションを取り除きます。
jq Manual (development version)
https://stedolan.github.io/jq/manual/
--raw-output / -r:
With this option, if the filter’s result is a string then it will be written directly to standard output rather than being formatted as a JSON string with quotes. This can be useful for making jq filters talk to non-JSON-based systems.
(Google翻訳)このオプションを使用すると、フィルターの結果が文字列の場合、引用符付きのJSON文字列としてフォーマットされるのではなく、標準出力に直接書き込まれます。 これは、jqフィルターが非JSONベースのシステムと通信するのに役立ちます。
最後を.[]としないと以下のようになり、-rオプションは働きません。
> cat hoge.json | jq -s -r '[ .[] | keys ] | flatten | unique' [ "hoge1", "hoge2", "hoge3", "hoge4", "hoge5", "hoge6" ]
jqコマンドは奥が深いなぁ。
おまけ
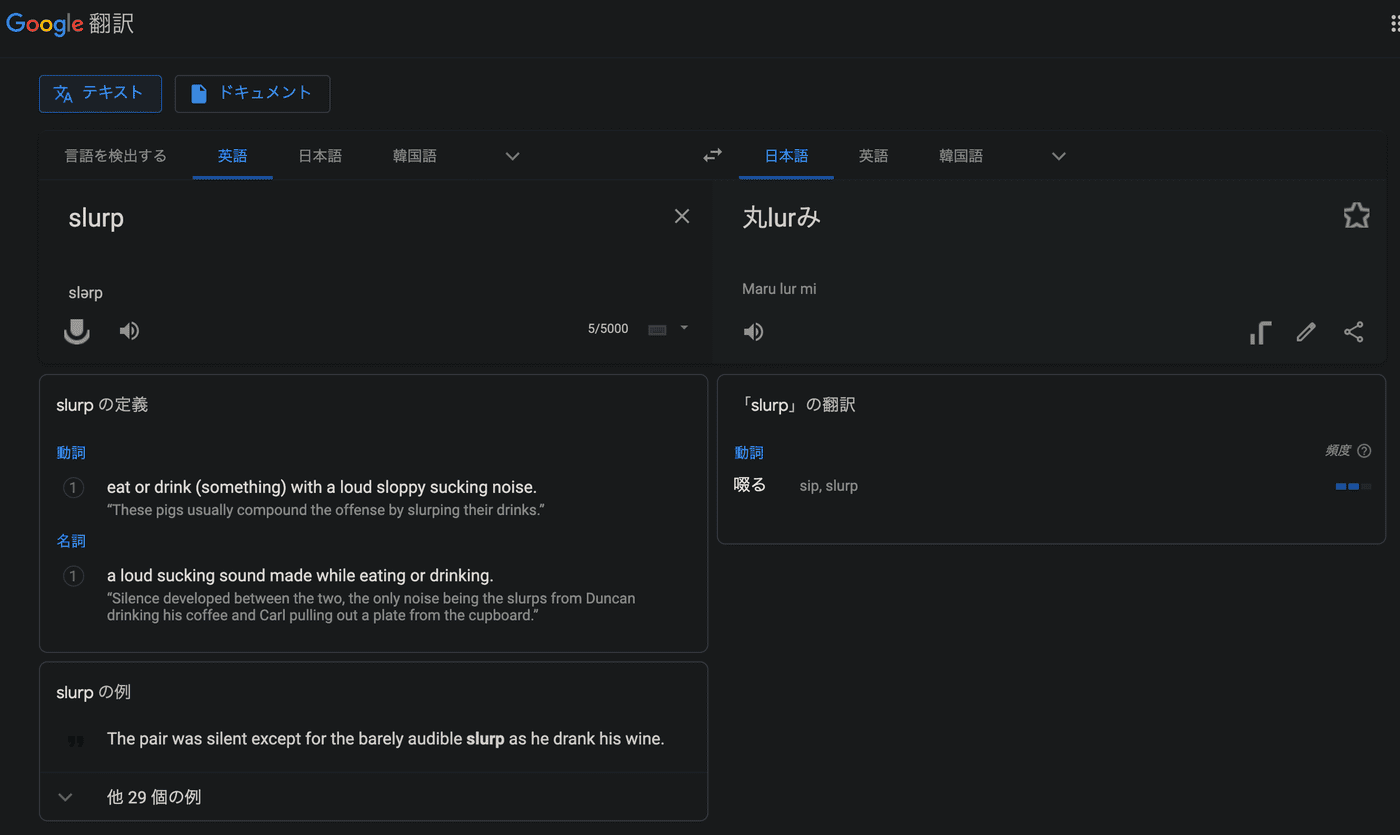
Google翻訳さんによるとslurpは丸lurみだそうですw
ヌードルハラスメント的ななにかが働いているのでしょうか???
参考
[jq] JSONデータの特定階層にあるキー名のユニーク値を取得 – Qiita
https://qiita.com/withelmo/items/b0e1ffba639dd3ae18c0
jq Manual (development version)
https://stedolan.github.io/jq/manual/



