
Amazon AuroraにLocustを使用した負荷テストを行い、性能検証を行いました。
その際の経緯と共に、詰まった点とポイントをまとめていきます。
ポイントまとめ
- Locustでリクエスト数を上げたい時は、Master/Worker構成にしSpawn rateは100以下にする
- Locustでユーザー数を増やしたい時は、「psycopg3」を使用する
- LocustでRPSを上げたい時は、「wait_time=0」に設定する
経緯
1, Master/Worker複数構成でLocustを起動
当初、AWSでLocustを起動しDBに接続しクエリを流すというテストで
・ECS on Fargate→Aurora
という構成の負荷テストを想定していました。
とりあえずの数値目標が「RPS:320」というのがあったので、
まずはLocustをMaster1台で「Number of users:320/Spawn rate:320」で1分間流してみました。
上記は、リクエストを投げるUser数の上限が320で、1秒毎に320ユーザーずつ増えていく
という意味で、理論上はテスト開始一秒後には320ユーザーからのリクエストが投げられる、という想定だったためです。
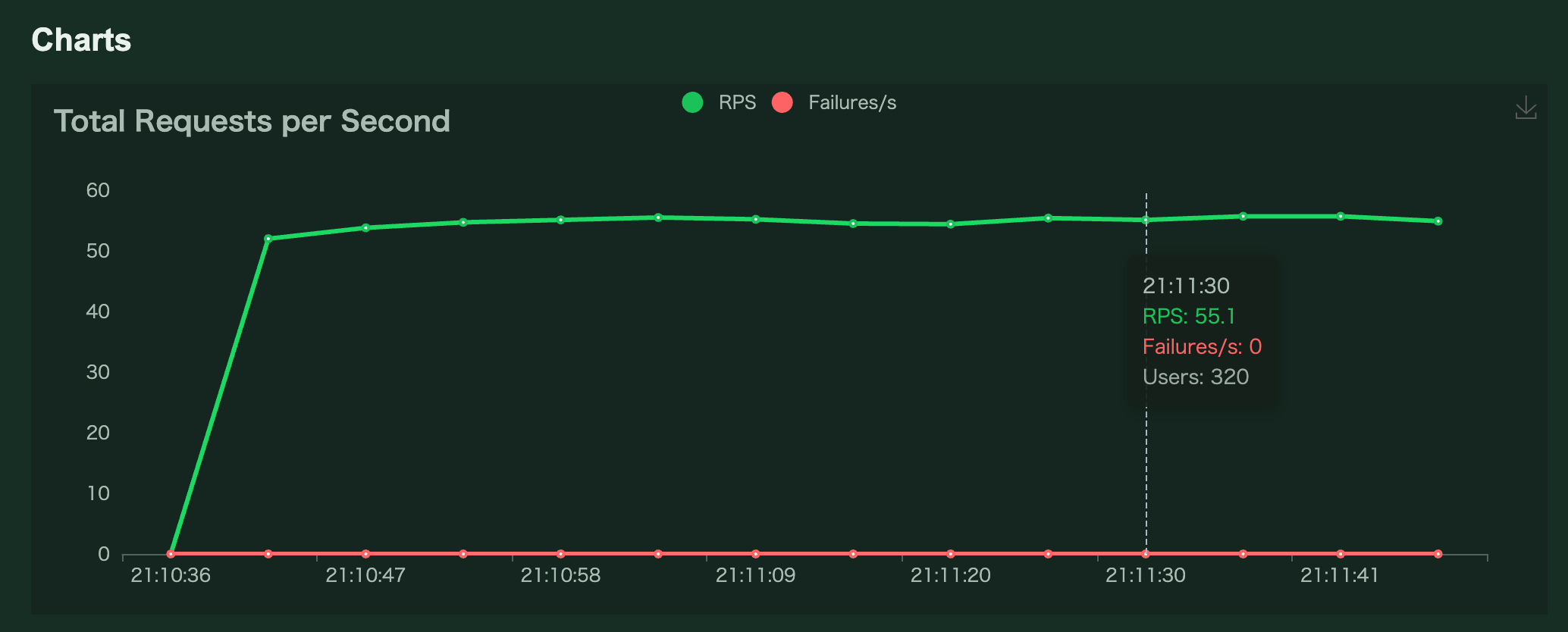
しかし、User数が320に達するもRPSは50が最大で推移
サーバーもDBもCPUは上限には全然達していない、という状況になりました。
…
全文はこちら:Locust負荷テスト 詰まった点と解決策など
著者:@am0800

