
はじめに
Mitsuoです、初めましての方はこんにちわ。
この記事は「もくもく会ブログリレー」24日目の記事です。
タイトルの通り、今回は初学者向けに優しくAthenaを学べる記事とさせていただきます。
ブログ前半ではAthenaの概要や関連する機能について解説します。ブログ後半では実際の操作を含めて弊社メンバーと「優しく学ぶ」内容となっております。
身内芸となり恐縮ですが、よろしくお願いいたします。
登場人物、鳥は以下の4名、1羽です。詳細は追って。

もくもく会について
一般的には「主にITに関する学習をする目的で、複数人が集まり各自「黙々」と作業をするイベントのことを指します。
弊社でも事業部横断でこのもくもく会を実施しております。当ブログリレーはもくもく会から企画されたイベントです。
ブログリレーが始まった事を知り、開催者の一人である檜山 準さんにお話した所、私も参加出来ることになったので微力ながら頑張ります。
なお、弊社メンバーにて、もくもく会に関する記事を書いておりますので良ければご覧になってください。

では本題に入っていきます。
当ブログで学べること
- Amazon Athenaの基礎
- Athenaを用いたALBアクセスログの分析
- ワークグループの設定変更
- Athenaを用いたCloudTrailログの分析
Amazon Athenaについて

Amazon Athena(以降 Athena)は、サーバレスなクエリサービスです。
一般的なSQL構文を使ってS3内にあるデータを分析する事が出来ます。 ※1
直接分析が出来るため、データソースから別途取り込むようなアクションは不要です。
なお、上述した通り、Athenaの実行エンジンはサーバーレスであるためインフラ環境のセットアップは不要です。
そのため、利用者はクエリ実行時にインフラ基盤を意識する必要がありません。
バックグラウンドでは自動的にインフラ基盤がスケーリングされ、クエリが並列で実行されるため、大規模なデータセットに対しても素早く実行結果が返ってきます。
そして、コストについてですがスキャンしたデータ量に応じてのみ課金され、1TBあたり5USDが発生します。※2
Athenaは他の分析サービスと比べて比較的安価な導入コストで分析が可能です。
一般的に分析サービスというと作り込みがどうしても必要になってしまうのですが、Athenaはその辺りの面倒さを取っ払ってくれるので、最低限のSQLクエリに関する知識があれば簡単に分析を始めることが出来ます。とても便利です。
※1 厳密に言うと、データソースにはS3以外を指定することが出来ます。RDS、RedShiftなどのリレーショナルデータベースやDynamoDBやDocumentDBのようなNoSQLデータベースのデータソースに対してFederated Queryを言う機能を使って実現可能です。
詳細は公式ドキュメント(Using Athena Federated Query)を参考にしてください。
※2 Athenaのコストの話をしています。細かく言うとクエリの実行結果をS3に保管するのでS3に関するコストも僅かながら発生します。
また、Athenaにはオンデマンド(使った分だけ)と、プロビジョンドキャパシティと呼ばれる事前にスペック(DPU)を決めて使うタイプの2種類があります。プロビジョンドキャパシティの場合は、DPUに応じた固定のコストが発生しますが、オンデマンド前提の説明をしています。
クエリエディタについて
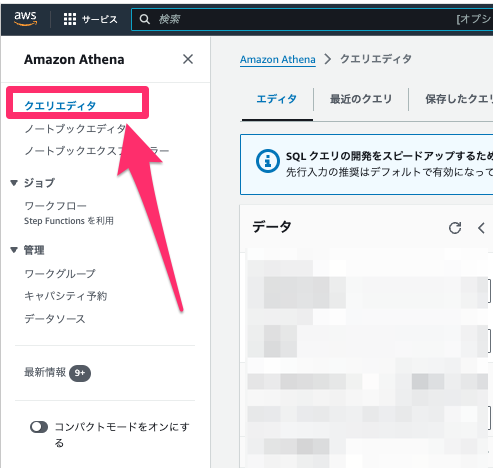
ではどのようにクエリを実行するかですが、AthenaではクエリエディタというWEB画面が用意されています。
サービス画面から左ペインにあるクエリエディタをクリックすると遷移出来ます。
クエリエディタの画面について簡単に解説します。
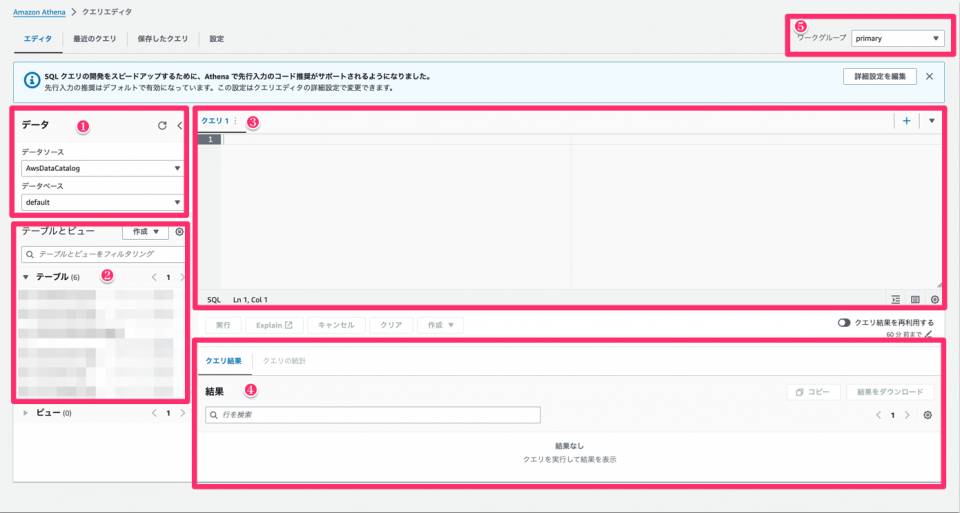
| No. | 内容 | 詳細 | 参考リンク |
|---|---|---|---|
| 1 | データ | Athenaクエリエディタが参照するカタログ情報とスキーマとテーブル情報を管理するデータベースを含む | Connecting to data sources Understanding tables, databases, and data catalogs |
| 2 | テーブル | テーブル名、テーブルの列項目(列名)、データ型を持つ | Understanding tables, databases, and data catalogs |
| 3 | 記入場所 | 実際にクエリを入力する箇所 | |
| 4 | 結果欄 | クエリの実行結果が表示される箇所、実行ステータス(完了など)、実行時間、スキャンした量を確認可能 | |
| 5 | ワークグループ | クエリの作業グループ | How workgroups work |
データベースとテーブルについて
イメージ図を用意しました。
Athenaでデータベースやテーブルを作成すると意識しないのですが、実態はGlueのリソースになります。
データソースがデータベースのグループを管理し、データベースがテーブルを管理しています。
データソースはカタログと、データベースはスキーマとも呼ばれます。
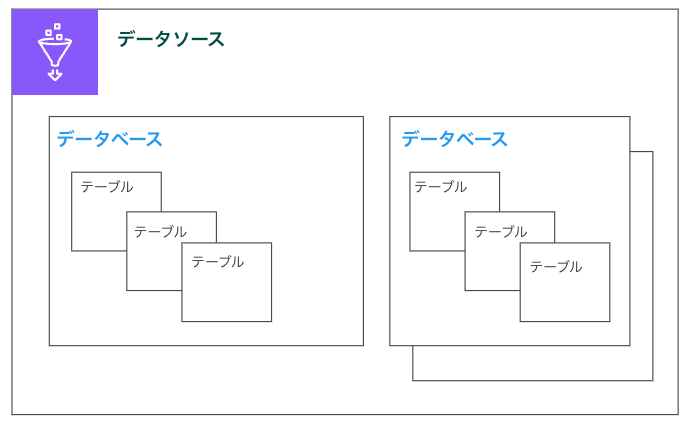
データベースは、テーブルを論理的なグループにまとめたもので、データセット(データソースにある実際のデータ)のメタ情報およびスキーマ情報を保持します。
テーブルはAmazon S3のどこにデータが格納されているかをAthenaに連携する役割を担っています。
また、上述した通り、データの列項目、各列項目のデータ型など実際のデータの構造を指定します。
抽象的ではあるので「Athenaの後ろでGlueのリソースが動いており、クエリを実行するためのデータ構造を作っている」程度で覚えてもらえれば良いと思います。
余談ですが、Athenaのデータソースは、awsdatacatalog という名前のリソースを利用します。
データベースは、指定しなければ default という名前のリソースを利用します。
ワークグループについて
Athenaにおける論理的なグループになります。
ワークグループ単位で作成したクエリを実行したり、クエリの実行履歴を分離することが出来ます。
デフォルトでPrimaryワークグループが作成されており、削除する事が出来ません。
ワークグループ単位でIAMを用いたアクセス管理が可能となります。
また、Athenaの実行エンジンであったり、クエリの実行結果の指定、暗号化設定など実行環境に関する諸設定もワークグループに対して行います。
実際に操作感を味わってみる
今までの説明でAthenaの何となくのイメージは持てたかと思いますので・・・
ブログ後半には業務の例を挙げ弊社メンバーと楽しく学ぶ内容となっています。
と書いたように、おふざけもありつつ、実機に触れていきますね。
メンバー紹介
この二人は同じ事業部のエンジニアで、筆者が作成する資料にたまに登場する人と鳥です。知る人ぞ知ると言う奴です。
以下の記事からも様子が伺えるので良ければ見ていってください。
[参加レポート]初めて雲勉に登壇したので振り返ってみる(Amazon EKSとコンポーネントの基礎を理解する)
LT登壇しました「独自ドメインをRoute 53に移管してみた」 #r53_osarai
YOUTUBEにも動画が上がっています。
第105回 雲勉 Amazon EKSとコンポーネントの基礎を理解する
Amazon Route 53をやさしくおさらいする会
今回はさわだ、ハヤブサに加えて以下3名もゲストで登場いただきます。

皆様、私の執筆にご協力いただきありがとうございます。
今回の要件
もうしばらくおふざけにお付き合いください。
株式会社さわD健ちゃんは「リモートワークは甘えであり、出社する方向に回帰すべきである」をコンセプトにBtoB向けの器具販売を行っており全国に20店舗ほど展開している。また、WEBサイト(ECシステム)をAWS上に所有している。
WEBサイトでの売上が調子がいい一方で「アクセス時にエラーが出る」であったり「アクセス速度が悪い」のような問い合わせが増えてきた。
代表取締役のさわだは早期に発見し対策を講じるべきだと考え、CTOであるハヤブサにログを分析出来るシステムを導入してほしいと要望した。
ハヤブサは分析サービスとして、Athenaの提案をする。
なお、さわだは過去にAthenaを使った事があり良いサービスである事を知っているため、提案を快諾したが、過去に従業員のスズケンが大量のログスキャンしたことを受けて過度なスキャンを抑止したり、一定期間で一定のスキャン量を超えた場合に通知するような仕組みを導入してほしいと要望する。
また、さわだは年度末に外部監査法人のつとむにAWSアカウントの操作履歴を提出する監査の懸念もしていた。
かねてより、監査情報を提出する際に、必要な情報を集めることが難しいと監査担当のえみこより相談を受けていた。 ※3
さわだはスズケンにAthenaのクエリで実現するように依頼した。
※3 色々とふざけすぎてごめんなさい。
株式会社さわD健ちゃんは架空の企業であり、実際に存在しません。
各メンバーの役割は実務とは関係なく、あくまで設定として配役しているものになります。
後は・・・CloudTrailでAPIログが取れるので、必要な情報が集めにくいとかもないんですが、Athenaに話を持ってきたかっただけなんです!すみません。
ただ、証跡はCloudTrail側で90日までしか持てないので、90日以降のログ分析ならAthenaでやるでしょう!!
前説
さわだ> と言う訳でハヤブサさん、よろしくお願いしますよ。
ハヤブサ> 了解です、うちのシステムのアーキはどんなのでしたっけ?
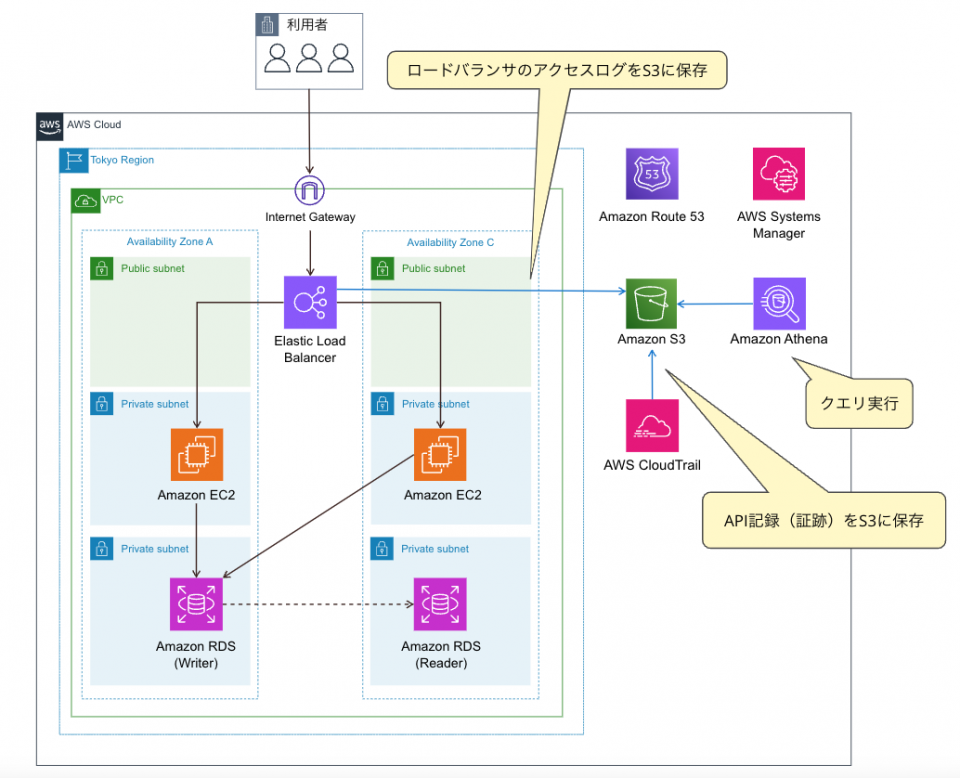
さわだ> こんな感じです。AZを3つにしてない等突っ込みどころはあるかもしれませんが気にしないでください。そこは本筋ではないですから。
ハヤブサ> 今回はAthenaの話ですもんね。
さわだ> そうそう、とにかくスモールスタートでログ分析出来ればいいです。あ、でもスキャン量は抑止したり、通知の仕組みは入れてください。コストは把握しておきたいので。
スズケン> うっす! 使いすぎないように注意しますw
ハヤブサ> ではまずALB(Elastic Load Balancing)のアクセスログの分析を始めてみますね。
スズケン> お願いします!
さわだ> 今回は上記のアーキテクチャでAthena以外の実装は完了している前提で進めますね。
スズケン> 今誰に向けて話したんすか?
さわだ> 細かいことは良いんですよ。ブログでやろうとすると少し難しいんです。
Athenaを用いたALBアクセスログの分析
以下のような流れで進めていきます。
- 事前準備
- データベースを作成する
- テーブルを作成する
- 分析クエリを実行する
事前準備
Athenaのクエリ実行結果を保存するためのS3バケットを事前に作成しておきます。
まずはAthenaにアクセスしクエリエディタを開きます。
クエリエディタの上部にある「設定」をクリックします。
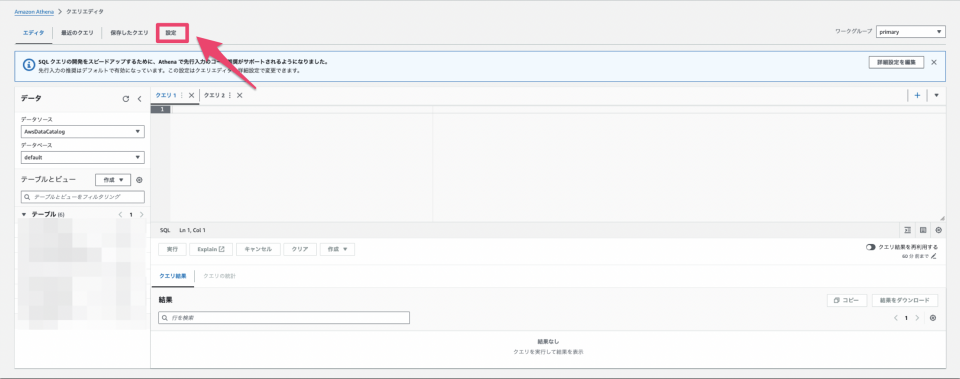
クエリの結果と暗号化の設定の画面が開くので、画面右上にある「管理」をクリックします。

格納場所に事前準備で作成したS3バケットを指定します。
「Browse S3」をクリックすると検索画面が出ます。
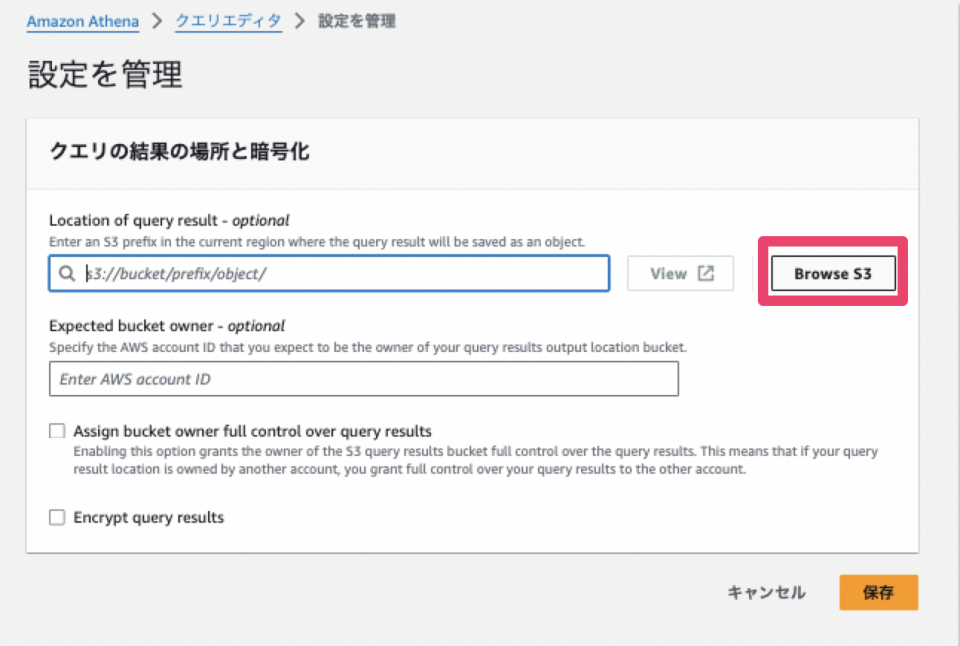
S3バケットを選択した後、「保存」をクリックして設定を完了させます。
今回は暗号化設定は特に行いません。
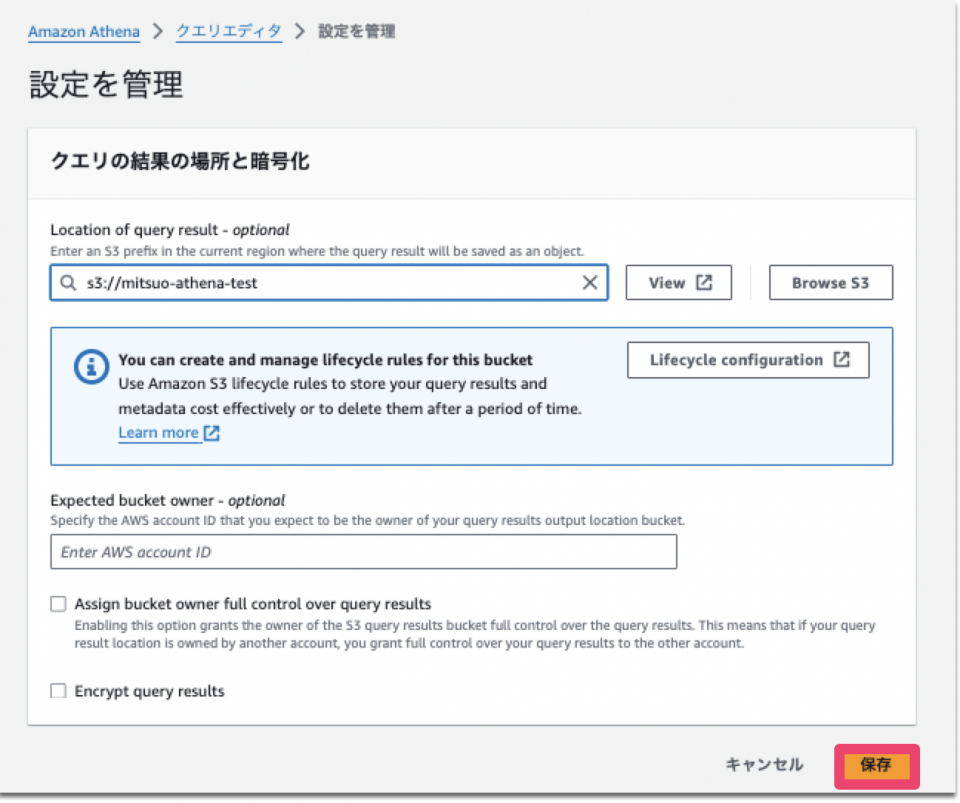
ここまでが事前準備になります。
次から実際にクエリを実行していきます。
データベースを作成する
Athenaのクエリエディタに戻り、記入場所で以下の文字を入力し「実行」をクリックします。
クエリ実行後、結果欄のステータスが「完了済み」になっていることを確認します。
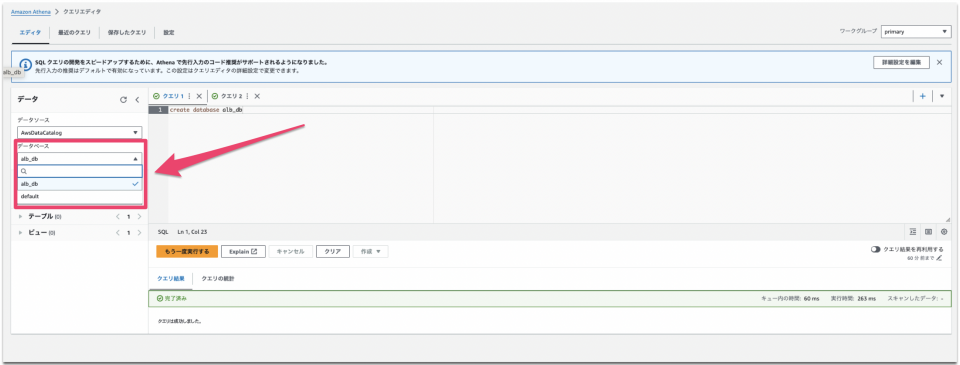
create database alb_db
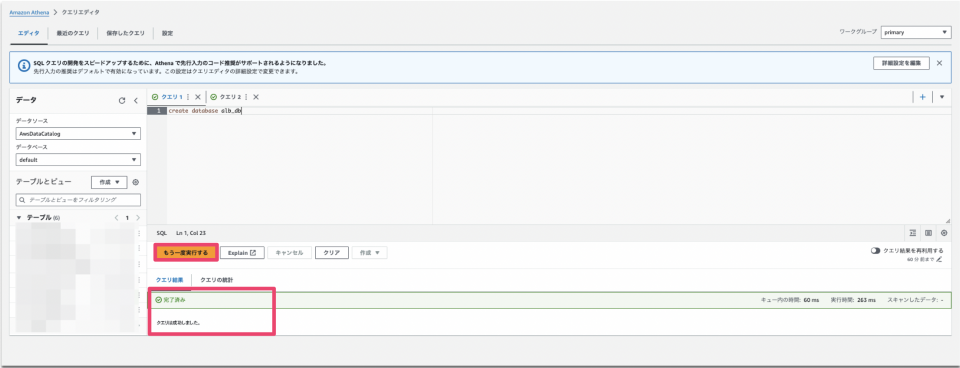
クエリ実行後に「alb_db」と言うデータベースが作成されます。
クエリエディタの左部にあるデータベースからプルダウンで切り替えます。
テーブルを作成する
次に作成したデータベース上でテーブルを作成するためのクエリを実行します。
今回は公式ドキュメントQuerying Application Load Balancer logsに記載されているクエリをそのまま利用します。
ドキュメントを見るとわかるのですが、DDLクエリ(テーブルの定義情報を設定するもの)がAWSから提供されており、データベースやSQLの知識が乏しくても分析が出来る様になっています。
説明すると長くなってしまうので、詳細は別記事に出来ればと思いますが、一言で言うと、ALBのアクセスログのフォーマットに沿って列項目をテーブルに読み込ませています。
なお、公式ドキュメントAccess logs for your Application Load Balancerにアクセスログのフォーマットが載っており、以下のDDLクエリで定義している列項目と同一であることが分かります。
また、Athenaが様々なデータ形式で分析をするための処理が必要です。処理の事をシリアライズと言い、シリアライズの方法をDDLクエリ内の ROW FORMAT SERDE で定義しています。
ALBアクセスログの場合は'org.apache.hadoop.hive.serde2.RegexSerDe'というのが正規表現(input.regex)によるシリアライズになります。
余談ですが、RegexSerDeのシリアライズは実際のログと正規表現の数が一致しない場合にクエリの実行結果がNULLになる場合があります。
詳細について興味がある方は、別記事のAthenaでALBアクセスログ分析が出来ない?特定日付以降の実行結果がNULLになった時の話にまとめてますのでご覧ください。
さて、前置きが長くなりましたが、手順を進めていきます。
記入場所で以下のクエリをコピーして貼り付けます。
クエリ内のLOCATIONは、実際にアクセスログが格納されているフォルダのS3 URIに置き換えてください。
URIを入力後、クエリ「実行」をクリックします。
CREATE EXTERNAL TABLE IF NOT EXISTS alb_access_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code int,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
classification string,
classification_reason string,
conn_trace_id string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) (.*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-_]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\\s]+?)\" \"([^\\s]+)\" \"([^ ]*)\" \"([^ ]*)\" ?([^ ]*)?( .*)?'
)
LOCATION 'S3のURI'

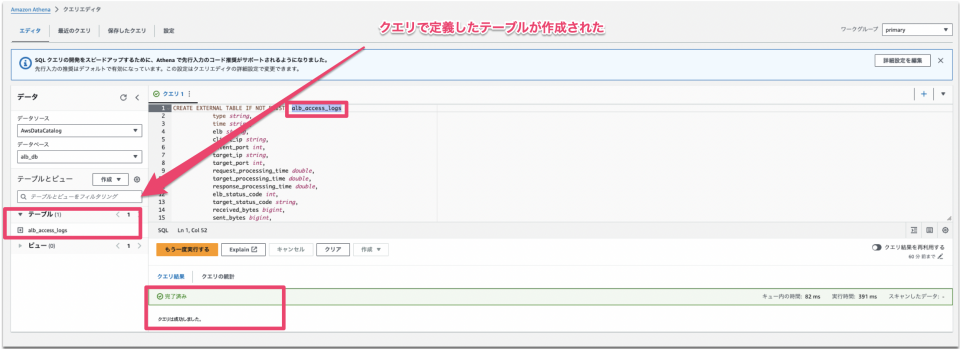
クエリの実行後、テーブルが作成された事を確認します。
分析クエリを実行する
ここまで来れば後は色々とクエリを叩いてみてください。
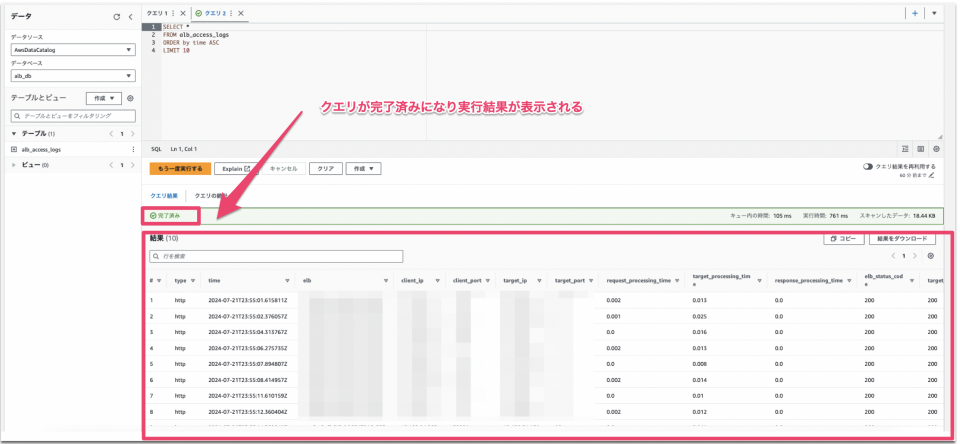
例1: ALBからクライアントに対してのレスポンスの時刻(Time)を昇順に100件のログを出力する。
SELECT * FROM alb_access_logs ORDER by time ASC LIMIT 100
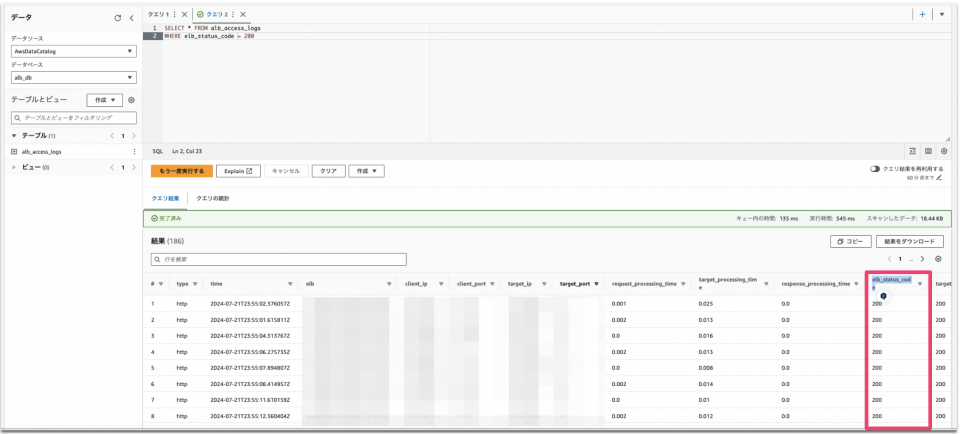
例2: ELBがレスポンスするHTTPのステータスコード(200は正常)を出力する。
SELECT * FROM alb_access_logs WHERE elb_status_code = 200
例3: ELBが受け取ったHTTPのGETリクエストをクライアントのIPアドレス別に出力する。
SELECT COUNT(request_verb) AS count, request_verb, client_ip FROM alb_access_logs GROUP BY request_verb, client_ip LIMIT 100;
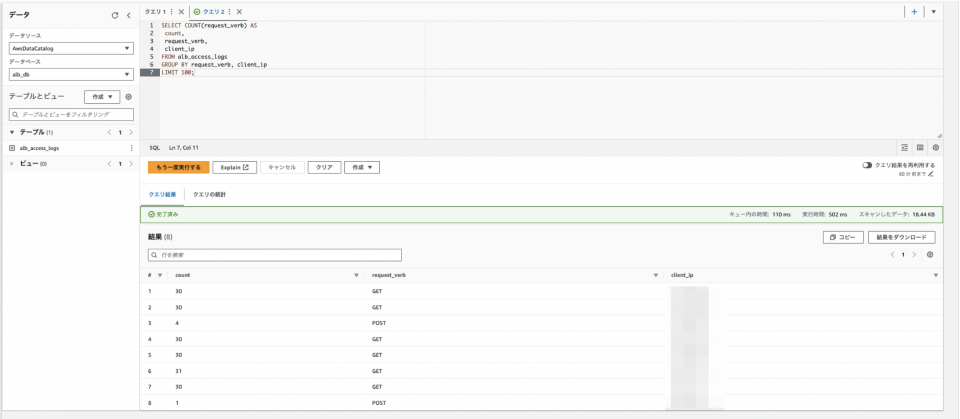
その他にも公式ドキュメントにサンプルが用意されているので試してみてください。
次節
さわだ> ハヤブサさん、早速のご対応ありがとうございます。
ハヤブサ> Athenaは公式ドキュメントも充実しているのでありがたいですよね
さわだ> そうですよね、ではスキャン量の抑止と通知設定だけ、スズケンくんお願いしていい?
スズケン> うっす、こっちもすぐ出来るんでやっておきます!
ワークグループの設定変更
以下のような流れで進めていきます。
- 事前作業
- データ制限設定
- 利用料のアラート設定
今回はワークグループは新規作成せずに、デフォルトで生成されている「default」に対して設定変更を行います。
データ制限設定は、スキャン毎に指定した容量を超えた場合、クエリ実行がキャンセルされるようにする機能です。
一方で利用料のアラート設定は、指定した期間でスキャンされたデータ量に対してアラートを発報する機能です。
事前作業
「利用料のアラート設定」の通知を行うためにSNSトピックを事前に作成しておきます。
データ制限設定
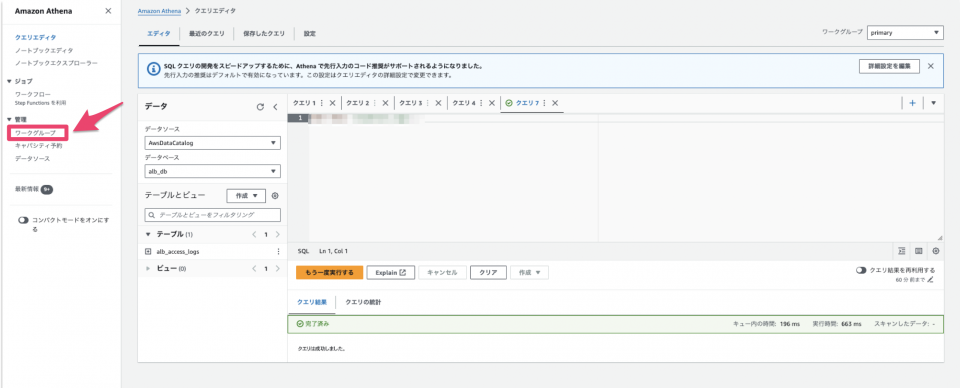
まずはAthenaにアクセスしクエリエディタを開きます。
画面左上のメニューボタンをクリックし、左ペインが展開されるのでそこからワークグループをクリックします。
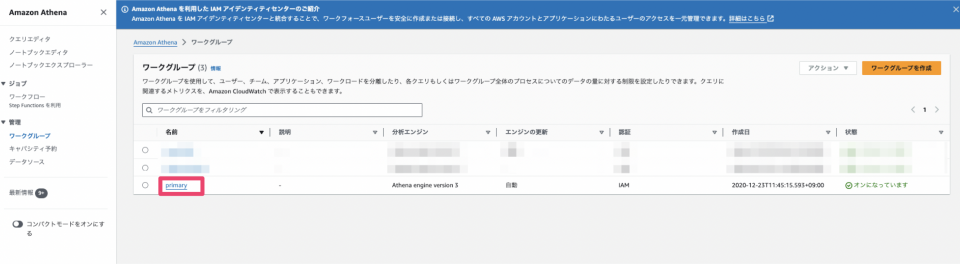
ワークグループ一覧が表示されるので、primaryのリンクをクリックします。
画面右上の「編集」をクリックします。
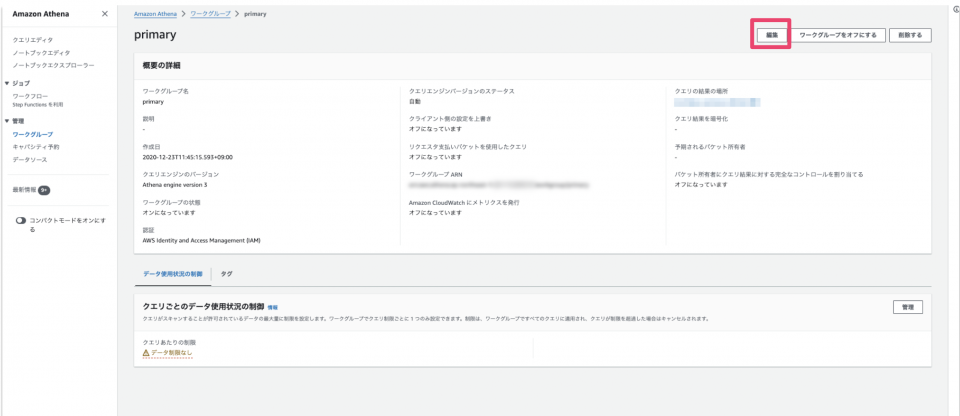
下にスクロールし、「クエリデータ使用状況コントロールごとに管理」をクリックし展開します。
ここで希望する容量を指定し、変更を保存をクリックします。
最小制限は10MBからになります。
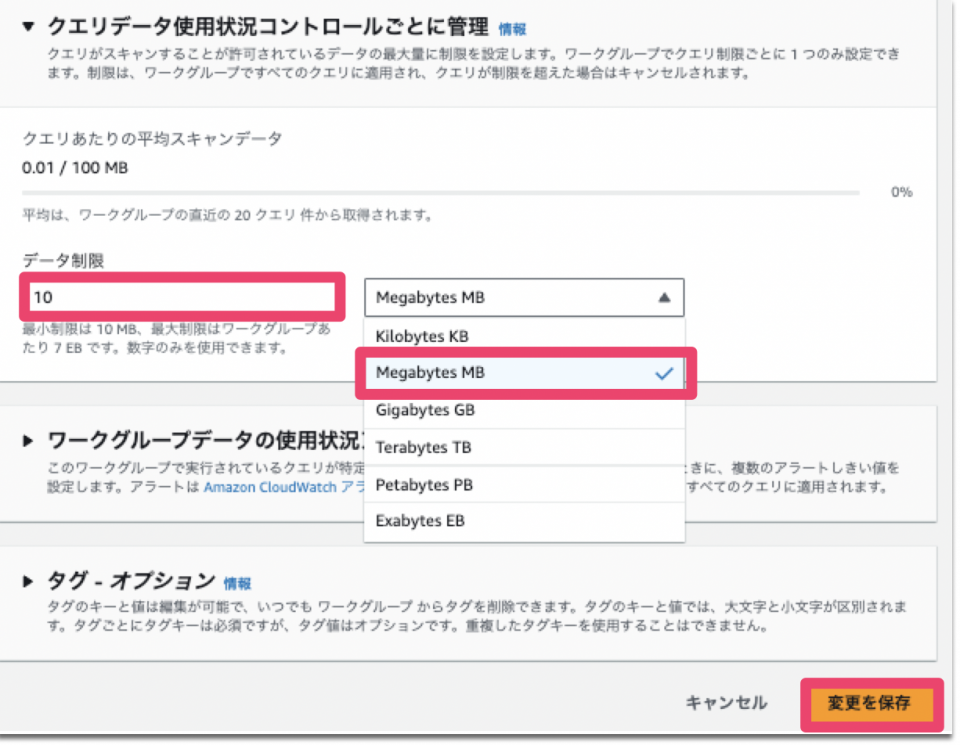
変更が反映されたことを確認します。
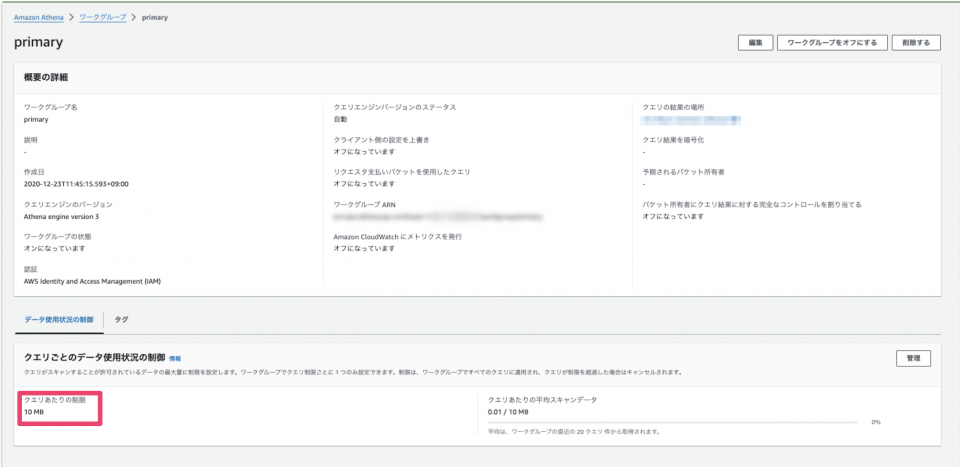
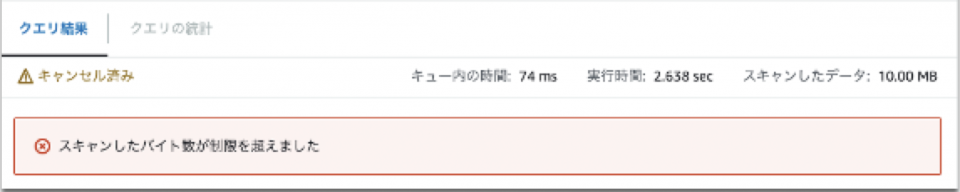
設定後、指定したスキャン量を超えた場合、以下のメッセージが表示されクエリがキャンセルされます。
利用料のアラート設定
ワークグループの編集画面から下にスクロールし、「ワークグループデータの使用状況アラート – オプション」をクリックし展開します。
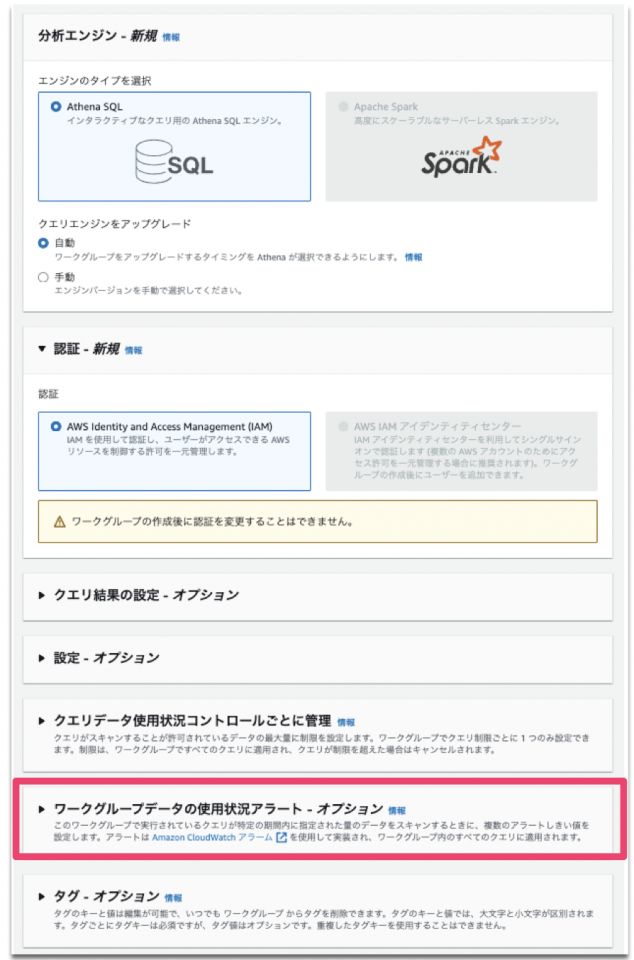
アラートの詳細設定でスクリーンショットを参考に設定を行い「変更を保存」をクリックする。
ここでは通知のテストを行うためすぐに閾値超過する設定にしています。
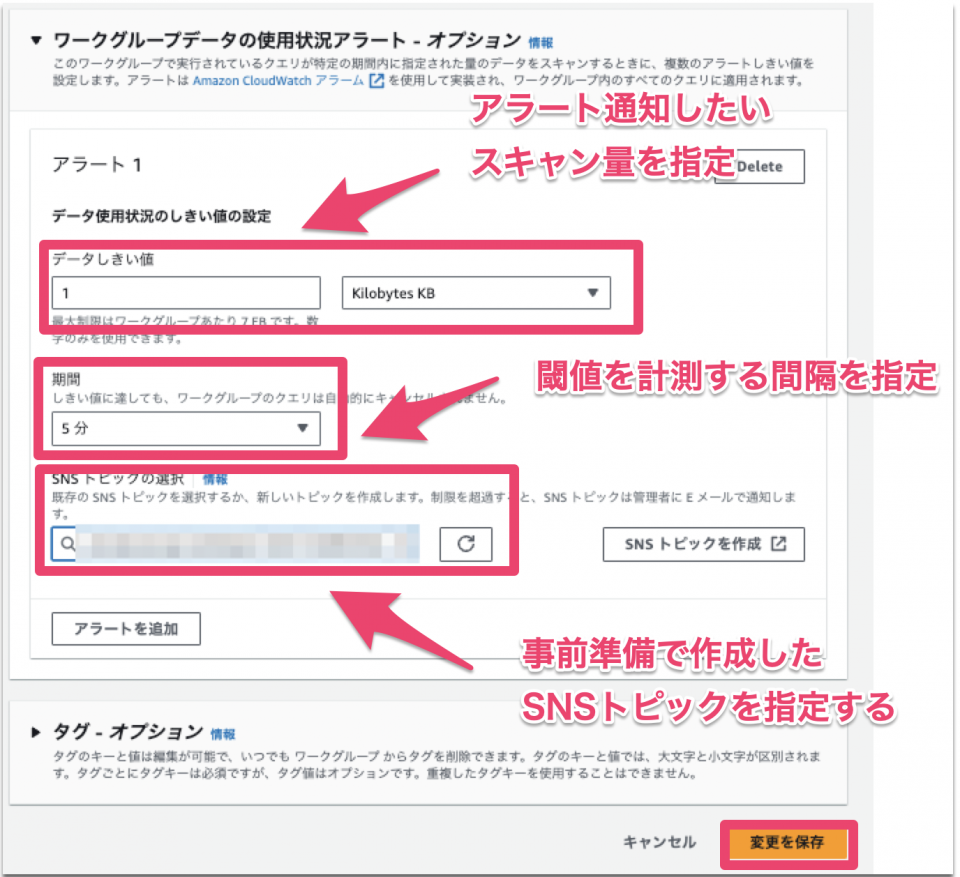
と思ったら最小の閾値は1024KBのようですね。勉強になります〜。
保存後に勝手に置き換わりました。
これによって実際に閾値以上の容量のデータをスキャンした際に、SNSから通知がされます。
監査のお話
つとむ > 今年もこの時期がやってきましたね。
えみこ > 監査大変なんですよね・・・どういったご要件で?
つとむ > AWSアカウントでどのような操作が行われたかを提出してほしいですね、はい。
えみこ > 了解しました!ちなみにどういったフォーマットで提出する必要があります?
つとむ > 特に指定はないのですが、構造化データになっていれば良いですよ。例えばCSV形式ですかね。
えみこ > というわけで、さわD、操作記録取りたいんだけどどうしたらいいかな?
さわだ > CloudTrailというサービスが操作記録(API単位)を持っているのでそこから落としてもらう感じですね。でもイベント履歴から取るのも面倒ではありますね・・・
ハヤブサ > CloudTrailのログもAthenaで抽出するのがいいんじゃないですか?
さわだ > そうですね!クエリの準備お願いしていい? じゃあスズケン!!
スズケン > ういっす!やります!
つとむ > ちなみに操作記録は、CloudTrailに限定する形で大丈夫です。監査の内容によってOSやDBのログも含まれてるくるので、ここで言ってる要件はあくまで仮の物として理解してください。
スズケン > つとむさん、それってどなたに向けた話ですか?
つとむ > ブログの読者ですね、はい。
Athenaを用いたCloudTrailログ(証跡)の分析
以下の流れで進めていきます。
- 事前準備
- データベースを作成する
- テーブルを作成する
- 分析クエリを実行する
事前準備
CloudTrailの証跡(API記録)設定が完了している必要があります。
すでに作成されている方はその証跡で設定されているS3バケットを指定しても構いません。
証跡の作成方法については、公式ドキュメントCreating a trail with the CloudTrail consoleを参考にしてください。
ここまでが事前準備になります。
次から実際にクエリを実行していきます。
データベースを作成する
後の流れはALBアクセスログと似ています。
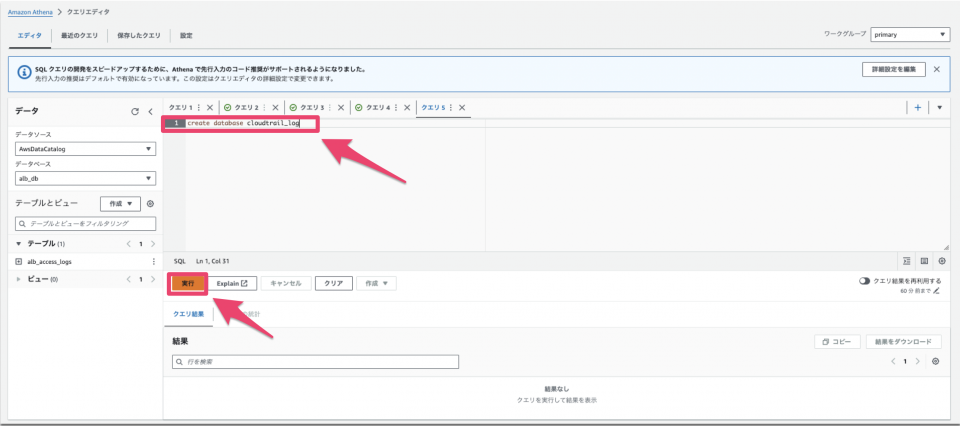
Athenaのクエリエディタに戻り、記入場所で以下の文字を入力し「実行」をクリックします。
クエリ実行後、結果欄のステータスが「完了済み」になっていることを確認します。
create database cloudtrail_log
テーブルを作成する
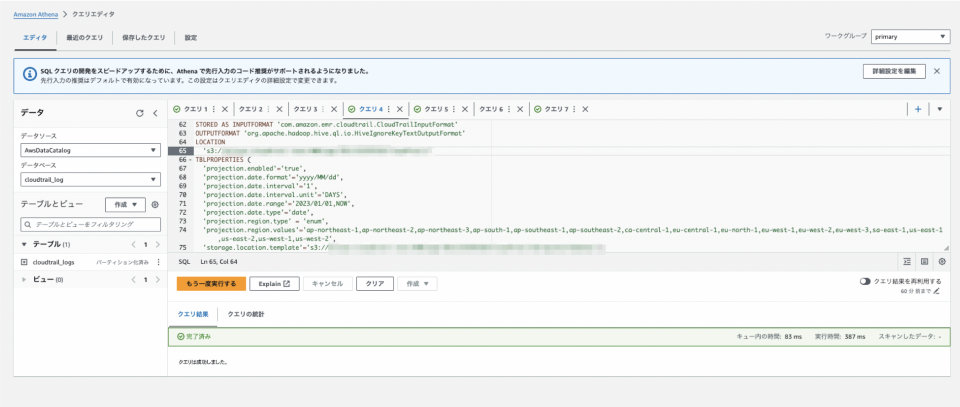
次に作成したデータベース上でテーブルを作成するためのクエリを実行します。
このクエリのポイントを簡単ですが解説します。
PARTITIONED BYによってテーブルの中リージョン、日付単位で論理的に分割(パーティション化)しています。
厳密にいうとPartition projectionを用いているのですが、説明が複雑になるため、このブログでは割愛します。
Athenaで検索をかける場合、この設定がないと、例えば特定日付のデータだけ抽出したい場合でも全てのデータに対してスキャンを行ってしまうため、スキャン料金が高くなる可能性があります。
CloudTrailのような大容量になりやすいデータにはこの設定は必須と考えてください。
そして、CloudTrailの証跡は半構造化データのJSON形式で保存されるのですが、JSON形式のデータをAthenaで分析するためには、ROW FORMAT SERDEでorg.apache.hive.hcatalog.data.JsonSerDeを指定する必要があります。
CREATE EXTERNAL TABLE cloudtrail_logs(
eventVersion STRING,
userIdentity STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
invokedBy: STRING,
accessKeyId: STRING,
userName: STRING,
sessionContext: STRUCT<
attributes: STRUCT,
sessionIssuer: STRUCT,
ec2RoleDelivery:string,
webIdFederationData: STRUCT<
federatedProvider: STRING,
attributes: map
>
>
>,
eventTime STRING,
eventSource STRING,
eventName STRING,
awsRegion STRING,
sourceIpAddress STRING,
userAgent STRING,
errorCode STRING,
errorMessage STRING,
requestparameters STRING,
responseelements STRING,
additionaleventdata STRING,
requestId STRING,
eventId STRING,
readOnly STRING,
resources ARRAY<STRUCT>,
eventType STRING,
apiVersion STRING,
recipientAccountId STRING,
serviceEventDetails STRING,
sharedEventID STRING,
vpcendpointid STRING,
eventCategory STRING,
tlsDetails struct
)
PARTITIONED BY (
region string,
`date` string)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'S3のURI'
TBLPROPERTIES (
'projection.enabled'='true',
'projection.date.format'='yyyy/MM/dd',
'projection.date.interval'='1',
'projection.date.interval.unit'='DAYS',
'projection.date.range'='2023/01/01,NOW',
'projection.date.type'='date',
'projection.region.type' = 'enum',
'projection.region.values'='ap-northeast-1,ap-northeast-2,ap-northeast-3,ap-south-1,ap-southeast-1,ap-southeast-2,ca-central-1,eu-central-1,eu-north-1,eu-west-1,eu-west-2,eu-west-3,sa-east-1,us-east-1,us-east-2,us-west-1,us-west-2',
'storage.location.template'='S3のURI/${region}/${date}');
分析クエリを実行する
ここまで来れば後は色々とクエリを叩いてみてください。
注意点として、最低限、WHERE句でパーティション化したdateを指定することを忘れないようにしてください。これによって指定された期間のみをスキャン対象にします。
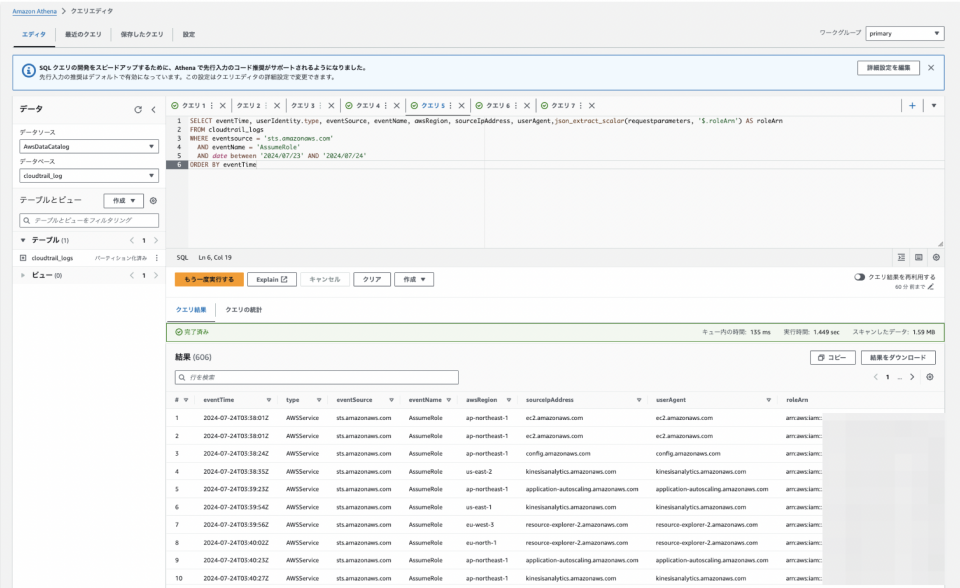
例: AssumeRoleのAPI記録を出力する
SELECT eventTime, userIdentity.type, eventSource, eventName, awsRegion, sourceIpAddress, userAgent,json_extract_scalar(requestparameters, '$.roleArn') AS roleArn FROM cloudtrail_logs WHERE eventsource = 'sts.amazonaws.com' AND eventName = 'AssumeRole' AND date between '2024/07/23' AND '2024/07/24' ORDER BY eventTime
公式ドキュメントにサンプルがありますので、色々と試してクエリ力を高めてください。
最後に
いかがだったでしょうか。
今回は初学者向けにAthenaを楽しみながら学んでいただくことを目標に記事を書いてみました。
実務でもAthenaを使うことがあるのですが、セットアップが簡単かつクエリ力次第で色んな事が出来てしまうのが本当に魅力的だなと感じています。
今後もAthenaに関してはアウトプット出来ればと思っています。
また、対話形式で弊社メンバーに登場いただきましたがブログだと表現がとても難しいです笑
勉強になりました。今後、登壇する際にでもこのメンバーは出てくるかもしれないですね、乞うご期待という事でまとめとさせていただきます。
名前とアイコンをお借りした澤田さん、ハヤブサさん、鈴木くん、武川さん、橋本さん、ありがとうございました。
明日の記事は、kawamataさんの「オブジェクト指向UX(OOUX)とは?メリットや手順を紹介!」です。
kawamataさんの記事、楽しみにしています。
Mitsuoでした!!



