
はじめに
こんにちわ、Mitsuoです。
早速ですが、Amazon Athena(以降Athena) 便利ですよね!?
お手軽にログ分析を始めることが出来る素晴らしいサービスです。
AthenaはAWSサービスのログ分析を行うためのDDLクエリやDMLクエリのサンプルが公式ドキュメントにて用意されており、ほぼSQLの知識が不要で利用が出来ます。
今回はOpenCSVSerDeを用いる際のTIPS、ハマりそうなポイントをご紹介します。

対象読者
Athena初心者の方
OpenCSVSerDeを用いる予定の方、またはOpenCSVSerDeをなんとなくで使っている方
なお、Athenaの基礎基本をまとめたブログを別で書いています。
澤田先輩と優しく学ぶAmazon Athenaです。
良ければ見ていってください。
SerDe、OpenCSVSerDeの概要については、[初学者向け]Amazon AthenaのSerDeを整理してみた(LazySimpleSerDeと OpenCSVSerDe編)を参考にしてください。
TIPS
DDLテーブルで定義出来るデータ型に制限がある
以下データ型に対応しています。
- STRING
- BOOLEAN
- BIGINT
- INT
- DOUBLE
- timestamp
- DATE
timestamp型はUNIXのみ対応
タイムスタンプは1579059880000の様なミリ秒単位の UNIX 数値のみ対応しています。
“YYYY-MM-DD HH:MM:SS.fffffffff” の様なJDBC 準拠の java.sql.Timestampに対応していません。
実際に再現してみる
まずはjava.sql.Timestampのタイムスタンプ型を含むテストデータを用います。
各列項目をダブルクォーテーションでくくっています。
id,name,reservetime "1","澤田","2024-07-01 00:30:00.000" "2","ハヤブサ","2024-07-02 03:00:00.000" "3","みつお","2024-07-05 05:00:00.000" "4","スズケン","2024-07-05 10:00:00.000" "5","りゅうじ","2024-07-05 11:00:00.000" "6","はたはた","2024-07-15 15:00:00.000" "7","大柴","2024-07-15 20:00:00.000" "8,"じゅんた","2024-07-20 16:30:00.000"
DDLクエリを実行します。
WITH SERDEPROPERTIESで引用符を指定していないので、デフォルトで引用符がダブルクォーテーションになっています。
CREATE EXTERNAL TABLE error1_time_csv (
id INT,
name STRING,
reservetime TIMESTAMP
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"escapeChar" = "\\"
)
LOCATION 's3のURI'
TBLPROPERTIES ("skip.header.line.count"="1");
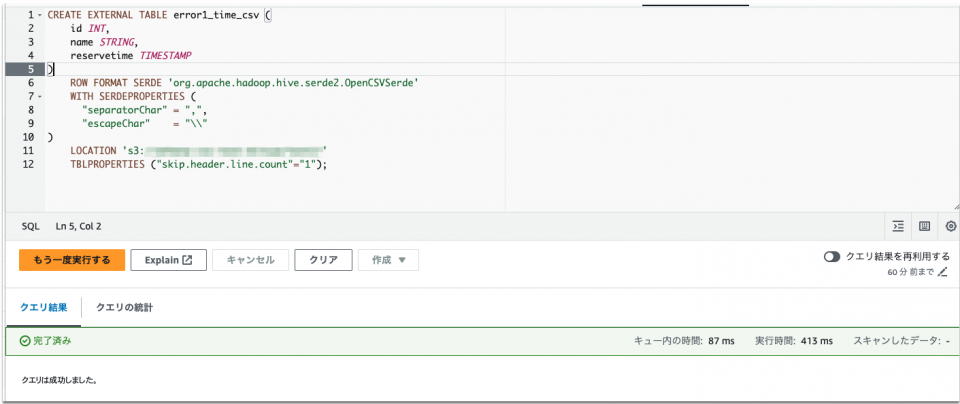
テーブル作成後、DMLクエリを実行します。
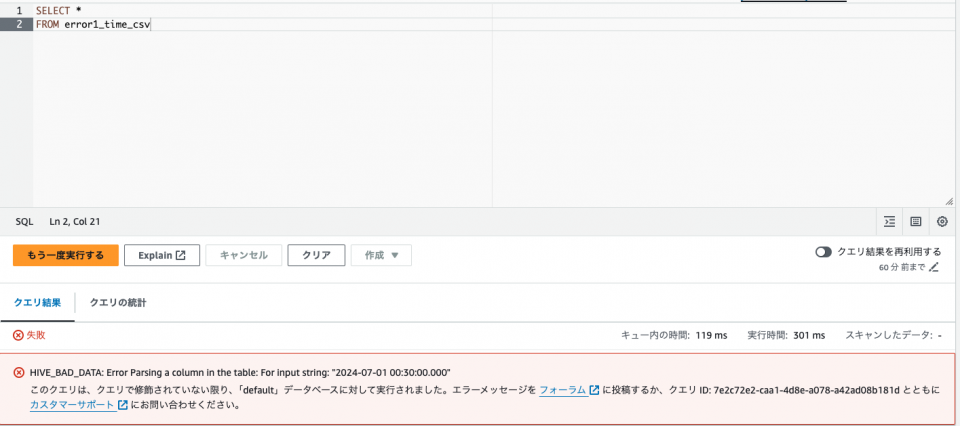
SELECT * FROM error1_time_csv
HIVE_BAD_DATA: Error Parsing a column in the table: For input string: “2024-07-01 00:30:00.000” と言うエラーが表示されます。
エラー分の通り、YYYY-MM-DD HH:MM:SS.fffffffff の形式のログをパースする事が出来ない様です。
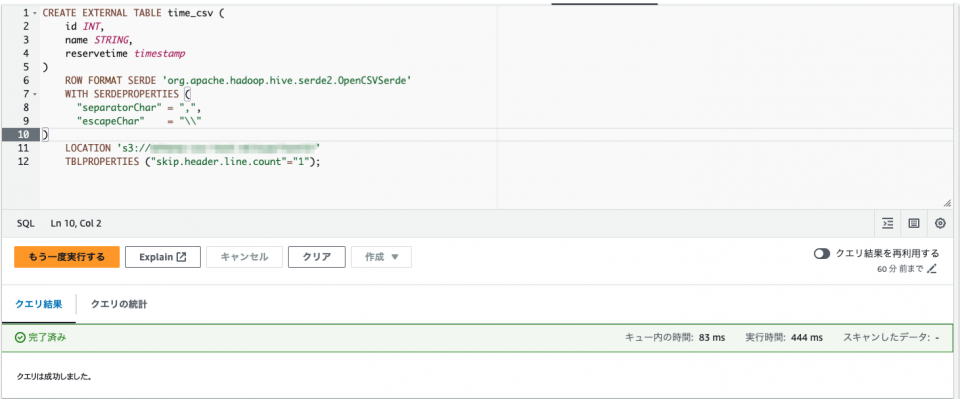
次にUNIX形式のタイムスタンプを含むテストデータを用意します。
id,name,reservetime "1","澤田","1721194209599752" "2","ハヤブサ","1721194209599915" "3","みつお","1721194211600532" "4","スズケン","1721194211600715" "5","りゅうじ","1721194211754593" "6","はたはた","1721194211754833" "7","大柴","1721194211754833" "8","じゅんた","1721194212099678"
テストデータを置き直してクエリを実行します。
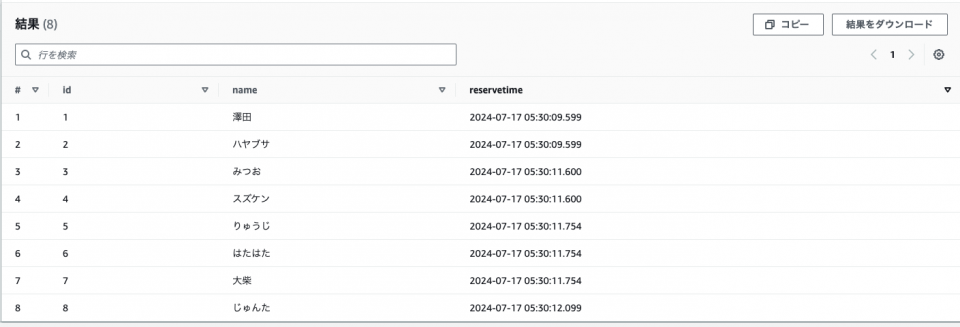
上述のとおり、reservetime(UNIXTIME)の項目が自動的に YYYY-MM-DD HH:MM:SS.fff の形式に変換されている事を確認しました。
Date型はyyyy/mm/ddの形式で直接指定が出来ない
1970 年 1 月 1 日からの経過日数で指定する必要があります。
例えば2022年7月1日が19174になり、そこから1日ずつインクリメントしたテストデータを用意します。
id,name,date "1","澤田","19174" "2","ハヤブサ","19175" "3","みつお","19176" "4","スズケン","19177" "5","りゅうじ","19178" "6","はたはた","19179" "7","大柴","19180" "8","じゅんた","19181"
DDLクエリを実行します。
CREATE EXTERNAL TABLE date_csv (
id INT,
name STRING,
date DATE
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"escapeChar" = "\\"
)
LOCATION 's3のURI'
TBLPROPERTIES ("skip.header.line.count"="1");
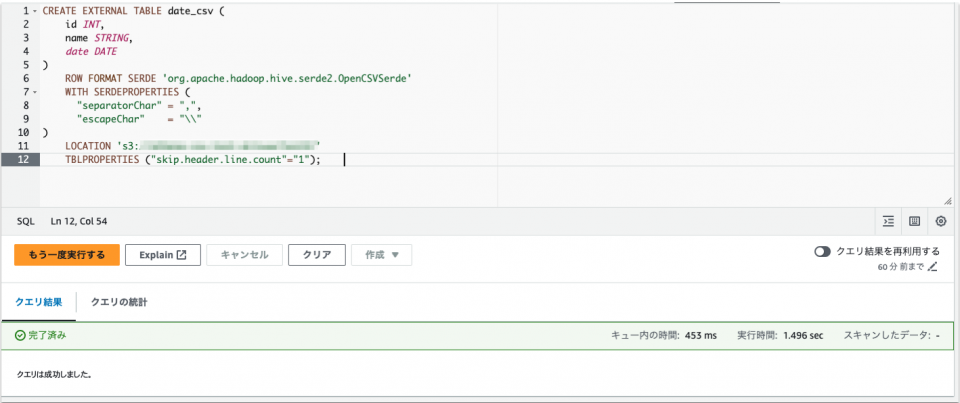
次にDMLクエリを実行します。
SELECT * FROM date_csv
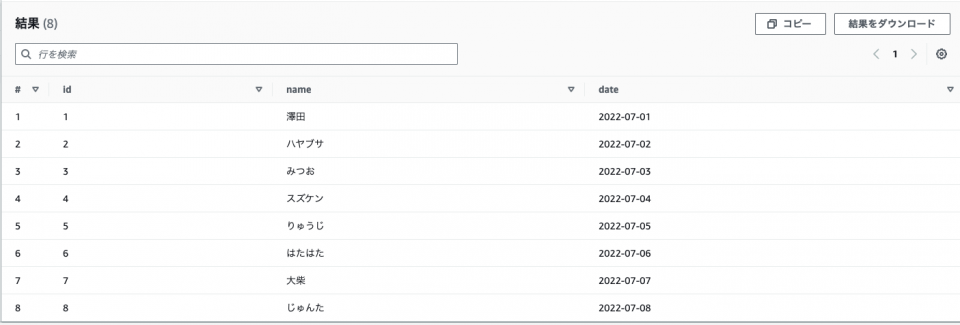
yyyy/mm/dd形式のテストデータに差し替えた場合はどうでしょうか、確認してみます。
id,name,date "1","澤田","2022-07-01" "2","ハヤブサ","2022-07-02" "3","みつお","2022-07-03" "4","スズケン","2022-07-04" "5","りゅうじ","2022-07-05" "6","はたはた","2022-07-06" "7","大柴","2022-07-07" "8","じゅんた","2022-07-08"
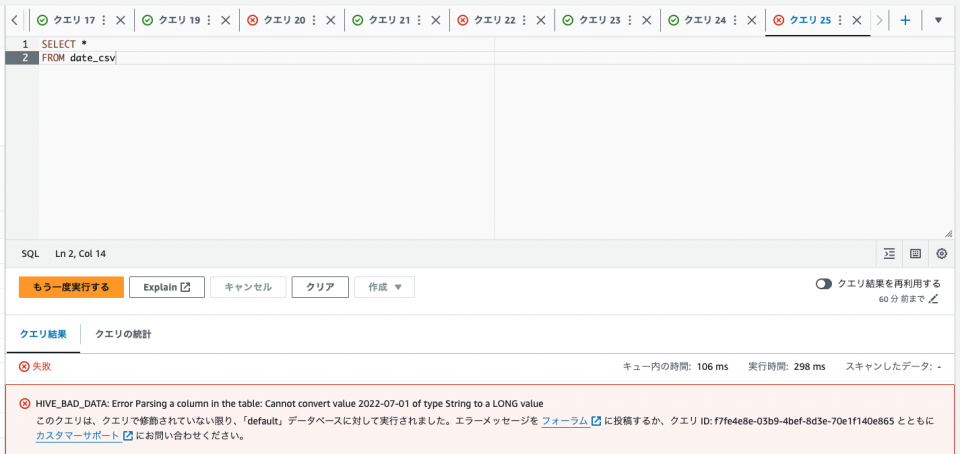
HIVE_BAD_DATA: Error Parsing a column in the table: Cannot convert value 2022-07-01 of type String to a LONG valueと言うエラーを確認しました。パース処理が失敗していることがわかります。
代替手段
出力ログ側の制約で1970 年 1 月 1 日からの経過日数で指定できない場合があるかと思いますが、
その時はSTRING形式で定義した上でSELECT句でDate型に変換する方法があります。
テストデータは同様にyyyy/mm/dd形式の日付を持ったものにします。
id,name,date "1","澤田","2022-07-01" "2","ハヤブサ","2022-07-02" "3","みつお","2022-07-03" "4","スズケン","2022-07-04" "5","りゅうじ","2022-07-05" "6","はたはた","2022-07-06" "7","大柴","2022-07-07" "8","じゅんた","2022-07-08"
DDLクエリを実行します。
dateがDATE型からSTRING型に変わっています。
CREATE EXTERNAL TABLE date_csv (
id INT,
name STRING,
date STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"escapeChar" = "\\"
)
LOCATION 's3のURL'
TBLPROPERTIES ("skip.header.line.count"="1");
次にDMLクエリを実行します。
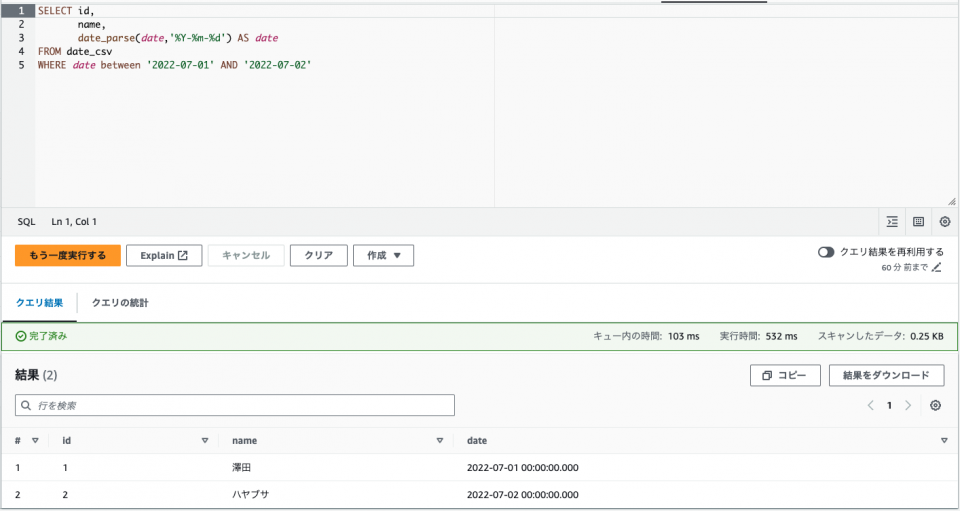
SELECT id,
name,
date_parse(date,'%Y-%m-%d') AS date
FROM date_csv
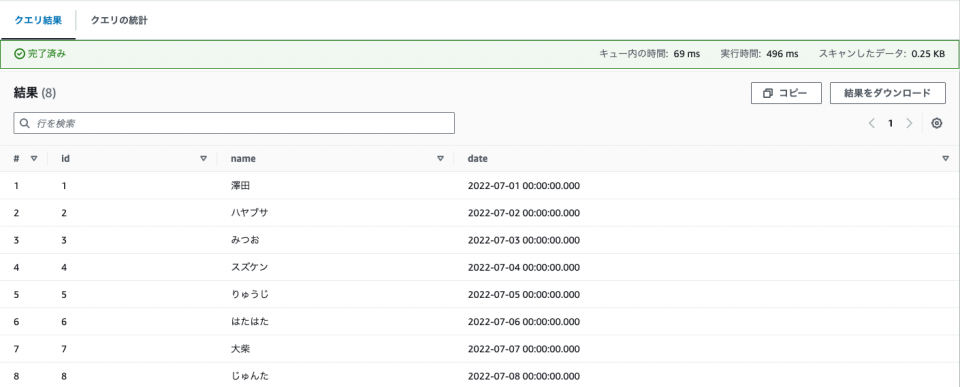
WHERE句でBETWEENが適用されていることがわかります。
まとめ
STRINGのみのCSVファイルであれば気にしなくて良いのですが、DateやTimestamp型を含む場合は考慮が必要になります。
エラー文だけだと理由が分かりにくいとも思うのでTIPSとして持ち帰っていただければ嬉しいです。
また、解説は出来てないのですが数値データ型として定義された列の空値または null 値はSTRING として残すような仕様もあります。
STRINGで定義しておいてSELECT時にCASTで型変換するなどの対処が必要になります。
以上です、Mitsuoでした。
参考資料
AWS公式ドキュメント
OpenCSVSerDe for processing CSV
Why is the TIMESTAMP result empty when I query a table in Amazon Athena?



