
はじめに
Amazon Athenaは、S3などに置かれたデータに対して手軽にクエリ実行できるサービスですが、
何も考えずに実行してしまうと思ったより時間がかかったり、
スキャンしたデータのサイズが大きくて想定よりも利用料金が膨らんでしまった、ということもあり得ます。
今回は、クエリ時間やスキャンデータのサイズ削減のために、
パフォーマンス最適化の方法について調べ、実際にどのくらいの効果があるのかを試してみました。
Amazon Athenaの概要
Amazon Athenaとは、標準的なSQLを使用してAmazon S3内のデータを直接分析できるサービスです。
(※ 実際にはAmazon S3以外でも使用できます。)
サーバーレスなので、インフラのセットアップなどは不要です。
実行したクエリに対してのみ課金されます。
パフォーマンスを上げるには?
パフォーマンスを上げるための方法としてはいくつか考えられますが、
今回は以下の3つの方法を試してみました。
- パーティション化する
- データを圧縮する
- データを列試行方式に変換する
それぞれについて、実行時間・スキャンデータ量を比較していきます。
使用したサンプルデータ
以下のようなサンプルを用意しました。
- ある店舗の、月ごとの来店情報のCSVファイル(2024年8月~10月)
- 項目は以下
- 来店日時:各月の中でランダムな日時(時間は10〜20時の範囲)
- 来店人数:1〜20名の中でランダムな数値
- 支払い金額:1000〜10000円の中でランダムな数値(10円単位)
- CSVファイルのイメージはこちら↓
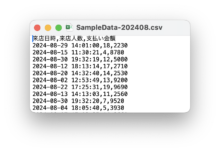
上記のファイルに対し、「9月の支払い金額が5000円以上のもの」を抽出してみたいと思います。
方法1 : パーティション化する
S3バケットに格納しているクエリ対象のデータをパーティション化することで、
不要なスキャンを無くしてパフォーマンスをあげることができます。
参考:データのパーティション化
以下の方法でパーティション化します。
- バケットの下に”year=[年]/month=[月]/各CSVファイル”という形で配置
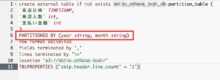
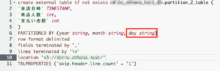
- Athenaでのテーブル作成時、PARTITIONED BY の設定を追加して実行する
※今回はyearとmonthの設定を追加して実行
- MSCK REPAIR TABLEコマンドを実行する

- yearとmonthを指定してクエリを実行する

結果
| 時間(※) | スキャンデータサイズ | |
| パーティションなし | 1.2076 sec | 7.88 MB |
| パーティションあり | 1.0474 sec | 2.63 MB |
※時間は5回分の平均を記載しています
- パーティションすると、時間・スキャンデータサイズともに小さくなりました。
- スキャンデータのサイズは単純に3ファイル見ている状態から1ファイルのみのスキャンになるので、1/3になりました。
追加検証
クエリの統計をみてみると、パーティション化すると「計画」の部分が3倍近くになっていることに気づきました。
パーティションなし:68 ms
パーティションあり:198 ms
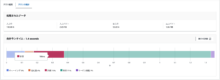
ここでAWS re:Post(公式のQ&A)を確認してみます。
テーブルを過剰にパーティション化すると、計画時間が長くなる可能性があります。テーブルに数百または数千のパーティションがあると、クエリの処理速度が遅くなる可能性があります。
どうやら、パーティションを増やすと「計画」の部分が増える可能性があるとのこと。
試しに、パーティションをさらに増やしてみました。
以下のように、monthの下にさらにday=[日]のフォルダを作成し、その中に各ファイルを分割して格納しました。
(通常は日付ごとにフォルダ(day=1〜31)を用意すると思いますが、ここでは2分割(day=1,2)で確認しています)
![]()
※パーティションの設定にもdayを追加してテーブルを作成します。
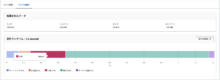
結果は以下のようになりました。
月別:204ms
日別:664ms
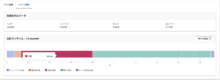
パーティションの数を増やすと、「計画」の時間が増えていました。
不要なスキャンが発生している場合は、パーティションしてスキャンデータを限定することで、
実行時間の短縮、スキャンデータサイズの縮小ができますが、
過剰なパーティションは「計画」の時間が増えて逆効果になりそうです。
クエリの統計を確認し、「計画」がネックになっていそうならパーティションの数を減らしてみるといいかなと思います。
方法2 : データを圧縮する
クエリ対象のファイルを圧縮することでスキャンデータのサイズが縮小され、パフォーマンスが向上します。
Athenaでサポートされている圧縮形式のうち、今回はgzipで試しました。
※サポートされている圧縮形式はこちらを参照
結果
| 時間(※) | スキャンデータサイズ | |
| 圧縮なし | 1.2076 sec | 7.88 MB |
| gzip圧縮 | 1.089 sec | 2.18 MB |
※時間は5回分の平均を記載しています
- 時間、スキャンデータサイズともに縮小しました。
- S3に置くデータを圧縮しているので、S3のストレージ容量の節約にもなります。
- 方法1(パーティション化する)より簡単なので、まずはこの方法から始めるのがいいかと思います。
方法3 : データを列指向形式に変換する
列指向ストレージ形式を使用することで、必要なブロックのみを取得することになり、
クエリのパフォーマンスが向上します。
参考:列指向ストレージ形式を使用する
列指向ストレージ形式としては、ParquetとORCの2つの形式を選択できます。
※各形式の詳細は以下公式サイト参照
Parquet
Apache ORC • Hadoop 向け高性能列指向ストレージ
以下でテーブルを列指向形式に変換します。(以下はORCの例)
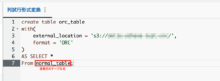
結果
| 時間(※) | スキャンデータサイズ | |
| 通常 | 1.2076 sec | 7.88 MB |
| 変換後(ORC) | 1.0738 sec | 1.61 MB |
| 変換後(Parquet) | 0.8862 sec | 2.84 MB |
※時間は5回分の平均を記載しています
- 時間、スキャンデータサイズともに縮小しました。
- ORC、Parquetのどちらを使用するかについてですが、公式には以下のように書かれています。
Parquet または ORC のいずれかを選択するには、以下の点を考慮してください。
クエリのパフォーマンス — Parquet はより幅広い種類のクエリをサポートしているため、複雑なクエリを実行する場合は、Parquet の方が適している場合があります。
複雑なデータ型 — 複雑なデータ型を使用している場合は、ORC の方が幅広い複合データ型をサポートしているので、より適している場合があります。
ファイルサイズ — ディスク容量が懸念される場合、通常、ORC を使用するとファイルが小さくなり、ストレージコストを低減できます。
圧縮 — Parquet と ORC はどちらも優れた圧縮機能を備えていますが、最適な形式は特定のユースケースによって異なります。
進化 — Parquet と ORC はどちらもスキーマの進化をサポートしています。つまり、時間の経過とともに列を追加、削除、または変更できます。
Parquet と ORC はどちらもビッグデータアプリケーションに適していますが、選択する前にシナリオの要件を検討してください。データとクエリに対してベンチマークを実行して、どの形式がユースケースに適したパフォーマンスを発揮するかを確認することをお勧めします。
クエリが複雑な場合はParquet、複雑なデータ型を使用している場合や、ストレージコストの低減を重視する場合はORCが適しているとのことです。
たしかに今回の結果を見ると、ORCの方がスキャンデータのサイズが小さくなっているのが分かります。
まとめ・感想
- 最適化の順番としては、
まずは手軽に実行できそうな方法2(データを圧縮する)を実施、
続いて方法1(パーティション化する)、方法3(データを列指向形式に変換する)を検討するという流れがいいかなと感じました。 - 今回試したのはそこまで大きなデータサイズではないので、
サイズが膨大だったり、ファイル数が増加するとまた違った結果になるかもしれませんが、
パフォーマンス改善を行う際の参考にしていただければと思います。 - クエリの統計を確認して「計画」の時間がネックになっていそうなら、パーティションの数を減らしてみるといいかと思います。



