
はじめに
こんにちわ、Mitsuoです。
早速ですが、Amazon Athena(以降Athena) 便利ですよね!?
お手軽にログ分析を始めることが出来る素晴らしいサービスです。
AthenaはAWSサービスのログ分析を行うためのDDLクエリやDMLクエリのサンプルが公式ドキュメントにて用意されており、ほぼSQLの知識不要で利用が出来ます。
今回の記事は、CSVやタブ区切りのデータを分析する際に用いるLazySimpleSerDeとOpenCSVSerDeについてご紹介します。

対象読者
Athena初心者の方
ログ分析を業務で行っているがクエリの中身をあまり把握出来ていない方
なお、Athenaの基礎基本をまとめたブログを別で書いています。
澤田先輩と優しく学ぶAmazon Athenaです。
良ければ見ていってください。
SerDeについて
AthenaにおけるSerDeとは、シリアライザー、デシリアライザークラスと呼ばれるもので、非常にざっくりいうと「Athenaがログ分析を出来る様にするための処理」のことです。内部の処理が公開されている訳ではない理解ですが、使用するログの形式をどのようにログデータを解析するかをAthenaに指示する役割を担っています。
Athenaでは、CREATE TABLEのDDLクエリ内でSerDe タイプを明示的に指定します。
きめ細かく言うとROW FORMATにてSerDeを指定します。
後述する OpenCSVSerDeの例は以下の様になります。
CREATE EXTERNAL TABLE IF NOT EXISTS testtimestamp1( `profile_id` string, `creationdate` date, `creationdatetime` timestamp ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' LOCATION 's3://DOC-EXAMPLE-BUCKET'
Athenaでは様々なデータ形式に対応するためのSerDeが用意されています。
サポートされる代表的なSerDeタイプを紹介します。
| SerDeタイプ | 概要 | URL |
|---|---|---|
| Avro SerDe | JSONベースの行指向データApache Avroに対応 | Avro SerDe |
| Parquet SerDe | メタデータを持つ列指向データApache Parquetに対応 | Parquet SerDe |
| Grok SerDe | Grokパターンと呼ばれる正規表現を用いる | Grok SerDe |
| Regex SerDe | 正規表現(Regex)を用いる | Regex SerDe |
| LazySimpleSerDe | CSV、TSV、カスタム文字に対応 | Lazy Simple SerDe for CSV, TSV, and custom-delimited files |
| OpenCSVSerDe | CSVに対応 | Open CSV SerDe for processing CSV |
| Hive JSON SerDe | CloudTrailなどのJSONデータに対応 | Hive JSON SerDe |
LazySimpleSerDeについて
Amazon Athenaでテーブル作成する際にデフォルトで指定されるSerDeタイプです。CSV、TSV(タブ単位)、カスタム文字などで項目を区切ることが出来ます。
CSVデータでのクエリ実行
簡単なCSVデータを作成してみました。
こちらを用いてクエリ実行します。
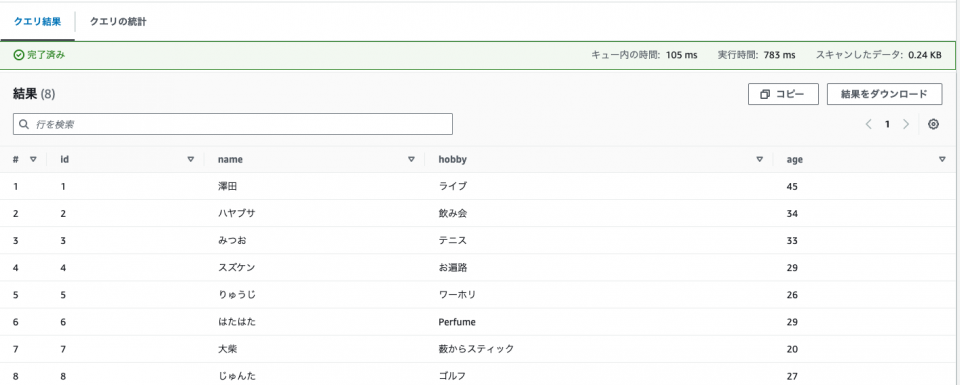
id,name,hobby,age 1,澤田,ライブ,45 2,ハヤブサ,飲み会,34 3,みつお,テニス,33 4,スズケン,お遍路,29 5,りゅうじ,ワーホリ,26 6,はたはた,Perfume,29 7,大柴,薮からスティック,20 8,じゅんた,ゴルフ,27
以下のDDLクエリを実行します。
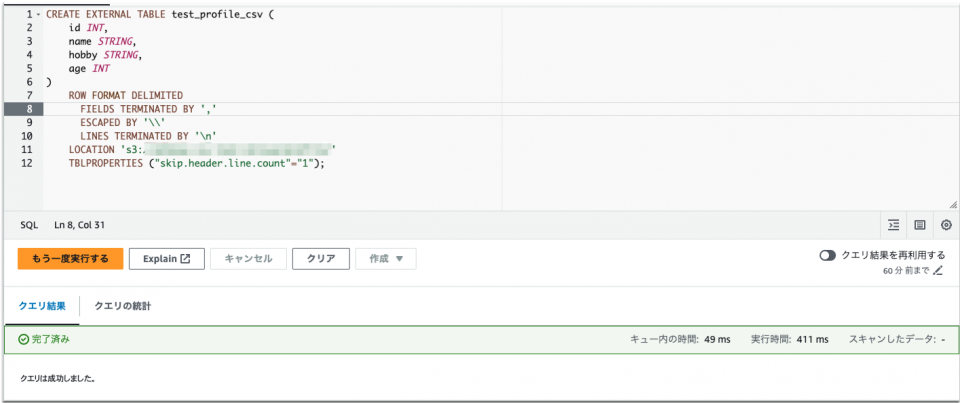
CREATE EXTERNAL TABLE test_profile_csv (
id INT,
name STRING,
hobby STRING,
age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3のURI(S3バケット上でオブジェクトが格納されているディレクトリ)'
TBLPROPERTIES ("skip.header.line.count"="1");
テーブル作成後に以下のクエリを実行します。
SELECT * FROM test_profile_csv
DDLクエリの解説
CREATE EXTERNAL TABLEにてデータベース上にテーブルを作成します。
test_profile_csvの所で実際に作成したいテーブル名を指定します。
その次の行からCSVデータにおける列項目のデータ型を一つずつ定義していきます。
Athenaにおけるデータ型の指定はDDLクエリかDMLクエリによって異なります。
CREATE TABLEのようなDDLクエリの場合は、Apache Hiveデータタイプを用いています。
SELECTなどのDMLクエリは、Trinoデータタイプを用いています。
基本的にはData types in Amazon Athenaにサマライズされているのでそちらを参考にするで良いです。
CREATE EXTERNAL TABLE test_profile_csv (
id INT,
name STRING,
hobby STRING,
age INT
)
次にSerDeに関する設定です。
DDLクエリの中でROW FORMAT SERDEの指定がないため、デフォルトのSerDeであるLazySimpleSerDeになります。
ROW FORMAT DELIMITEDにて以下の内容を指定します。
| 項目 | 内容 |
|---|---|
FIELDS TERMINATED BY |
列項目(カラム)の区切り文字を指定する ここではカンマ ,で区切ると定義する |
ESCAPED BY |
エスケープ文字を指定する ここではバックスラッシュ \を定義する |
LINES TERMINATED BY |
行の区切り文字を指定する ここでは改行 \nを定義する |
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
その他の設定です。
| 項目 | 内容 |
|---|---|
LOCATION |
データの保管場所 Athenaでクエリ実行するオブジェクトがあるディレクトリを指定する |
TBLPROPERTIES |
テーブルのプロパティ設定 様々な設定項目がある |
LOCATION 's3のURI(S3バケット上でオブジェクトが格納されているディレクトリ)'
TBLPROPERTIES ("skip.header.line.count"="1");
skip.header.line.count"="1ではCSVファイル内でスキップする行数を指定しています。
テストデータのように、1行目に「id,name,hobby,age」と実際のデータではない列項目が含まれている場合に指定します。
id,name,hobby,age 1,澤田,ライブ,45 2,ハヤブサ,飲み会,34 3,みつお,テニス,33 4,スズケン,お遍路,29 5,りゅうじ,ワーホリ,26 6,はたはた,Perfume,29 7,大柴,薮からスティック,20 8,じゅんた,ゴルフ,27
以下クエリはskip.header.line.count"="1を指定せずにテーブル作成した場合の例です。
DDLクエリ
CREATE EXTERNAL TABLE noskip_test_profile_csv (
id INT,
name STRING,
hobby STRING,
age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3のURI(S3バケット上でオブジェクトが格納されているディレクトリ)';
DMLクエリ
SELECT * FROM noskip_test_profile_csv
実行結果
余計な行が残っていることがわかりますね。
# id name hobby age 1 name hobby 2 1 澤田 ライブ 45 3 2 ハヤブサ 飲み会 34 4 3 みつお テニス 33 5 4 スズケン お遍路 29 6 5 りゅうじ ワーホリ 26 7 6 はたはた Perfume 29 8 7 大柴 薮からスティック 20 9 8 じゅんた ゴルフ 27
TSVデータでのクエリ実行
CSVデータの場合と文法は同様になります。
TSVデータの場合は、CSVデータと異なり列の区切り文字がタブになるため、
FIELDS TERMINATEDでタブ \tを指定しています。
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ESCAPED BY '\\' LINES TERMINATED BY '\n'
LazySimpleSerDeを用いるAWSサービスのログ
VPCフローログは空白を区切り文字に指定します。
CREATE EXTERNAL TABLE IF NOT EXISTS `vpc_flow_logs` (
列項目...,
列項目...
)
PARTITIONED BY (`date` date)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
LOCATION 's3://amzn-s3-demo-bucket/prefix/AWSLogs/{account_id}/vpcflowlogs/{region_code}/'
TBLPROPERTIES ("skip.header.line.count"="1");
CloudFrontのアクセスログはタブを区切り文字に指定します。
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_standard_logs ( 列項目..., 列項目... ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION 's3://amzn-s3-demo-bucket/' TBLPROPERTIES ( 'skip.header.line.count'='2' )
OpenCSVSerDeについて
CSVファイル用のSerDeタイプです。
DDLクエリの中でROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'を指定するだけで良いです。
CSVデータでのクエリ実行
LazySimpleSerDeのテストで使ったCSVデータを用います。
id,name,hobby,age 1,澤田,ライブ,45 2,ハヤブサ,飲み会,34 3,みつお,テニス,33 4,スズケン,お遍路,29 5,りゅうじ,ワーホリ,26 6,はたはた,Perfume,29 7,大柴,薮からスティック,20 8,じゅんた,ゴルフ,27
DDLクエリ
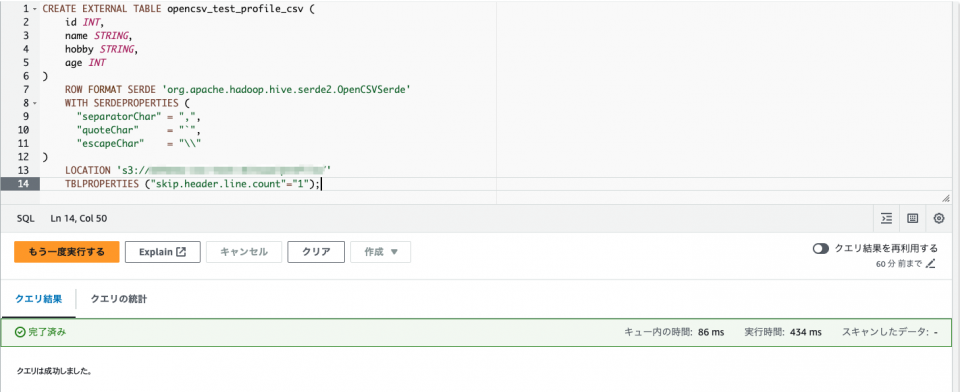
CREATE EXTERNAL TABLE opencsv_test_profile_csv (
id INT,
name STRING,
hobby STRING,
age INT
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"quoteChar" = "`",
"escapeChar" = "\\"
)
LOCATION 's3のURI(S3バケット上でオブジェクトが格納されているディレクトリ)'
TBLPROPERTIES ("skip.header.line.count"="1");
DMLクエリ
SELECT * FROM opencsv_test_profile_csv
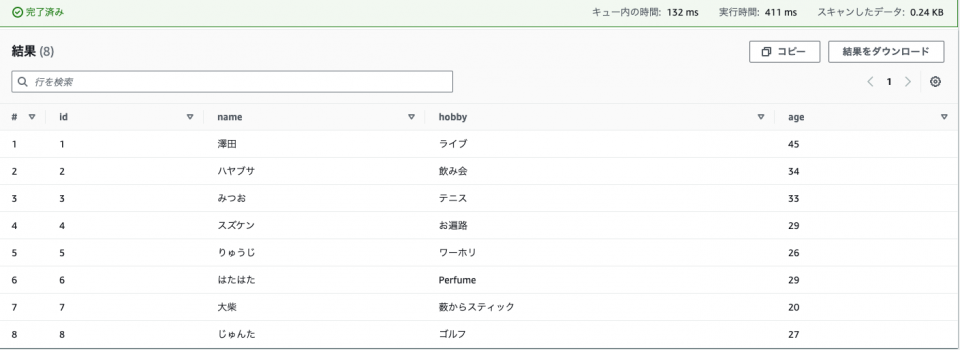
LazySimpleSerDeを用いた時と同じ結果が返ってきたことが確認出来ました。
DDLクエリの解説
LazySimpleSerDeで解説した箇所は割愛します。
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"quoteChar" = "`",
"escapeChar" = "\\"
| 項目 | 内容 |
|---|---|
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' |
OpenCSVSerdeによるシリアライズを指定する |
WITH SERDEPROPERTIES |
OpenCSVSerdeで文字の区切り文字、引用符文字、およびエスケープ文字を指定する separatorChar 区切り文字の指定 quoteChar 引用符の指定 escapeChar エスケープ文字の指定 |
OpenCSVSerdeではデフォルトの引用符がダブルクォーテーション "ですが、quoteCharによって変更する事が可能です。
引用符は列項目のずれをなくすために指定します。
例えば、区切り文字が,で何かしらの列項目がoutput is good,mitsuo is also goodだったとします。
ここで引用符の指定がないとoutput is goodとmitsuo is also goodがそれぞれ別の列として解釈されてしまいます。
OpenCSVSerDeとLazySimpleSerDeのどちらを使う?
まずはデータに引用符(シングルクォーテーションあるいはダブルクォーテーション)が含まれるかどうかで考えてみると良いです。
※厳密に言えば、ログの中で引用符による解釈が必要かどうかが正しいと考えます。
データに引用符を含む場合は、OpenCSVSerDeを利用してください。
WITH SERDEPROPERTIESで区切り文字、引用符、エスケープ文字を指定してください。
一方でデータに引用符がない場合はLazySimpleSerDeを利用してください。
FIELDS TERMINATED BYで区切り文字を、ESCAPEDでエスケープ文字を指定してください。
その他の判断ポイントとして、データに UNIX の TIMESTAMP 数値 (1579059880000 など) を含む場合は、OpenCSVSerDe を使用します。
データが java.sql.Timestamp(YYYY-MM-DD HH:MM:SS.fff) 形式を使用する場合は、LazySimpleSerDe を使用します。
まとめ
少し長くなってしまったので当ブログは一旦これで書き上げます。
初学者の方向けに書いてみましたが分かりやすい内容になっていれば幸いです。
OpenCSVSerDeは上述したTIMESTAMP型やDATEに関して注意事項があったり、DDLテーブル生成時に意外な仕様があるためそれは別の記事にまとめれればと思います。
以上です、Mitsuoでした。



