
はじめに
こんにちわ、Mitsuoです。
7月に入り暑くなってきましたね。
タイトルの通り、AthenaにてALBのアクセスログの分析を行っていたのですが、その際に出くわした事象について解説します。
事象
AthenaにてALBのアクセスログに対してSELECTクエリを実行すると特定の日付の行データがNULLで返ってくる。
実施内容
作成したテーブル(DDL)
日付単位でDBのテーブルをパーティショニングしています。
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code int,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
classification string,
classification_reason string
)
PARTITIONED BY
(
date STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) (.*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-_]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\"')
LOCATION 's3://`S3バケット名`/AWSLogs/`アカウントID`/elasticloadbalancing//'
TBLPROPERTIES
(
"projection.enabled" = "true",
"projection.date.type" = "date",
"projection.date.range" = "2023/01/01,NOW",
"projection.date.format" = "yyyy/MM/dd",
"projection.date.interval" = "1",
"projection.date.interval.unit" = "DAYS",
"storage.location.template" = "s3://`S3バケット名`/AWSLogs/`アカウントID`/elasticloadbalancing//${date}"
)
SELECTクエリの実行結果
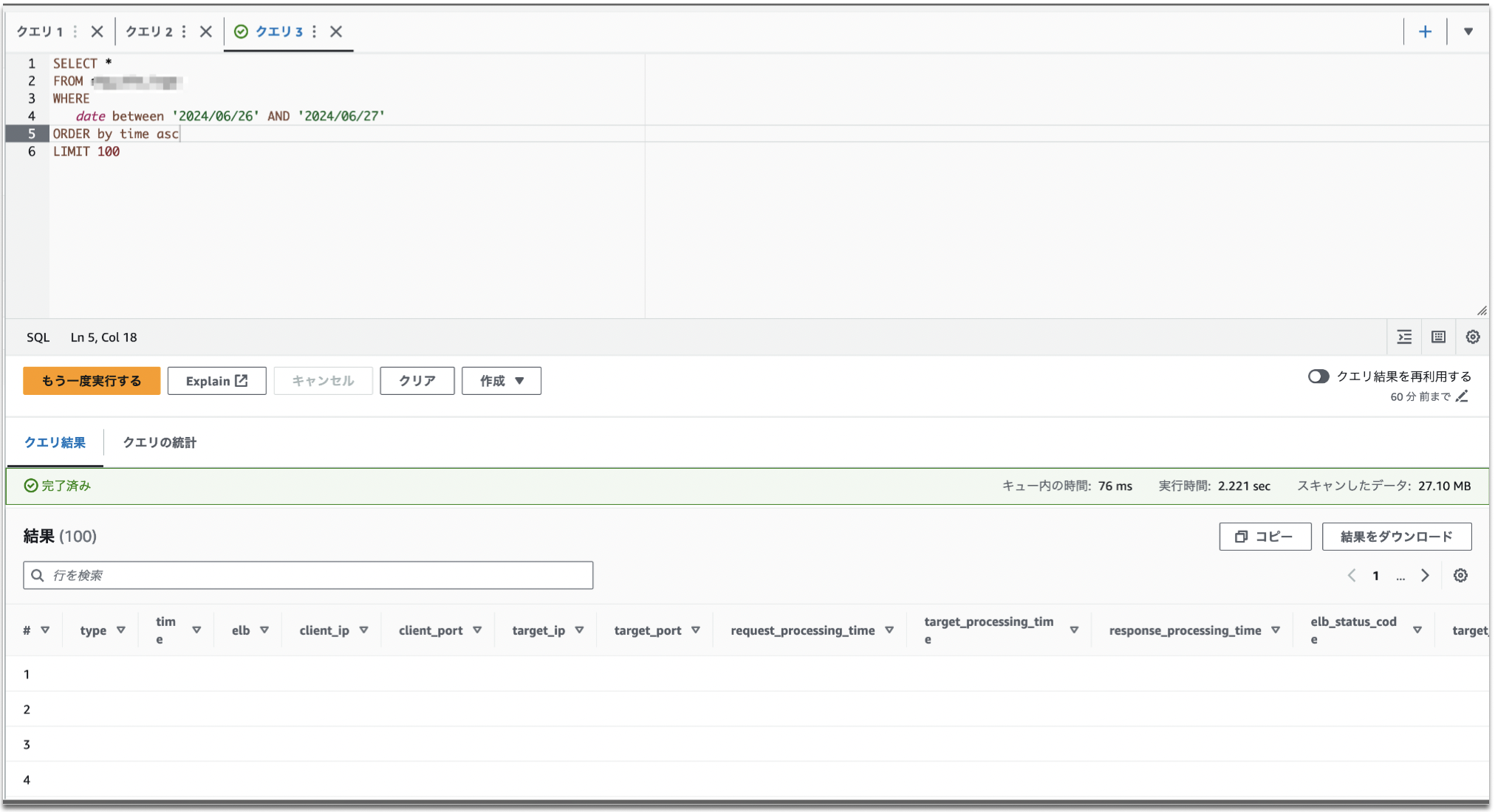
SELECT文のWHERE句で日付(date)でフィルタリングしスキャン数を減らす様にしていました。
6月26日から27日分のクエリだけ抽出する様にしています。
SELECT * FROM alb_logs WHERE date between '2024/06/26' AND '2024/06/27' ORDER by time asc LIMIT 100
以下のように列項目が表示されるのですが、行データが何もない状態(NULL)になります。
厳密に言うとパーティショニング列(date)は表示されました。
NULLを確認したクエリ
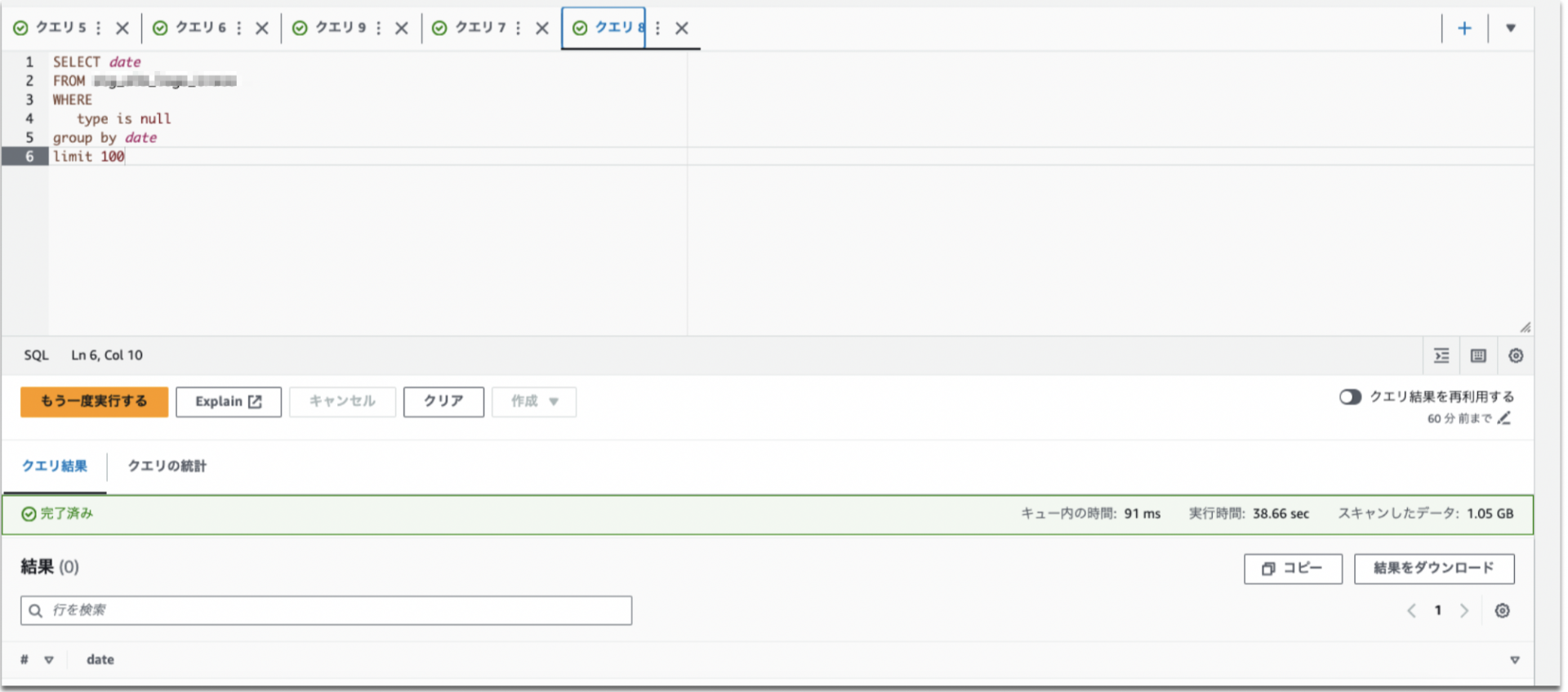
次にNULLデータを日付単位で抽出しました。
SELECT date FROM alb_logs WHERE type is null group by date limit 100
実行結果は以下の通りで5月18日からクエリの実行日時までのデータがNULLになっていることがわかりました。
# date 18 2024/05/18 6 2024/05/19 1 2024/05/20 4 2024/05/21 12 2024/05/22 13 2024/05/23 14 2024/05/24 9 2024/05/25 3 2024/05/26 5 2024/05/27 7 2024/05/28 2 2024/05/29 16 2024/05/30 10 2024/05/31 17 2024/06/01 11 2024/06/02 8 2024/06/03 15 2024/06/04 19 2024/06/05 21 2024/06/06 20 2024/06/07 23 2024/06/08 25 2024/06/09 28 2024/06/10 22 2024/06/11 24 2024/06/12 44 2024/06/13 32 2024/06/14 31 2024/06/15 36 2024/06/16 41 2024/06/17 26 2024/06/18 35 2024/06/19 37 2024/06/20 27 2024/06/21 46 2024/06/22 40 2024/06/23 39 2024/06/24 42 2024/06/25 34 2024/06/26 43 2024/06/27 29 2024/06/28 45 2024/06/29 33 2024/06/30 30 2024/07/01 38 2024/07/02
原因
ALBアクセスログのフォーマット変更に伴い、conn_trace_id (元:traceability_id)が追加されていたためです。
アクセスログのフォーマットについては、公式ドキュメントのAccess logs for your Application Load Balancerを参考にしてください。
conn_trace_idが追加されただけでNULL値で返す様になったのはAWS側の仕様になります。
以下はテーブル作成のクエリの抜粋になりますが、ROW FORMAT SERDEでAthenaが取り扱うデータの形式に応じた変換方法を定義しています。
org.apache.hadoop.hive.serde2.RegexSerDeでは正規表現を使用してテーブル列に抽出します。
RegexSerDeでは、行データと正規表現の項目が一致しない場合、データがNULLとして返される仕様があります。
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) (.*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-_]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\"')
CREATE EXTERNAL TABLEで定義した列項目に対して実際にどのような正規表現を使うかを上記のinput.regexで指定しています。
今回は実際のログにconn_trace_idの項目が追加されているにも関わらずinput.regexで正規表現の指定がない状態になっていました。
詳細は公式ドキュメントのRegex SerDeを参考ください。
公式ドキュメント抜粋
If a row in the data does not match the regex, then all columns in the row are returned as NULL. If a row matches the regex but has fewer groups than expected, the missing groups are NULL. If a row in the data matches the regex but has more columns than groups in the regex, the additional columns are ignored.
解決方法
テーブル作成(DDL)のクエリを修正しました。
公式ドキュメントのQuerying Application Load Balancer logsが最新のフォーマットに更新されています。リリースノートには無かったですが5月下旬(22日頃)に更新があった様です。
具体的には、CREATE EXTERNAL TABLEにconn_trace_idの列項目およびシリアライズする正規表現を追記しました。また、今後に備えて、unexpectedという列項目を追加しました。
修正版のクエリ
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code int,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
classification string,
classification_reason string,
conn_trace_id string,
unexpected string
)
PARTITIONED BY
(
date STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) (.*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-_]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\" ?([^ ]*) ?(.*)')
LOCATION 's3://`S3バケット名`/AWSLogs/`アカウントID`/elasticloadbalancing//'
TBLPROPERTIES
(
"projection.enabled" = "true",
"projection.date.type" = "date",
"projection.date.range" = "2023/01/01,NOW",
"projection.date.format" = "yyyy/MM/dd",
"projection.date.interval" = "1",
"projection.date.interval.unit" = "DAYS",
"storage.location.template" = "s3://`S3バケット名`/AWSLogs/`アカウントID`/elasticloadbalancing//${date}"
)
結果
NULLになっている項目が無くなったことを確認しました!
まとめ
今回はALBのアクセスログで事象が起きましたが、正規表現によるシリアライズ(Regex SerDe)を行なっている場合は、起こり得る内容になります。
動いていたクエリが急に動かなくなった、エラーは吐かないけどNULLで返ってきた場合はログのフォーマットを疑ってみましょう。
公式ドキュメントのクエリを参考にしつつ実際のログと比較してみることを推奨します。
なお、ALBアクセスログのクエリ方法が紹介されている日本語版のre:postでは、
conn_trace_idの列項目が追加されていないので同様の事象が起こり得ますので注意してください。
英語版のre:postは、執筆時点で17日前になっているので、メンテナンスされている様ですね。
英語版ドキュメントは最新の情報が反映されている事を再認識してます。
以上です、Mitsuoでした。
