「オブザーバビリティと監視の違いがわからない・・・」
「最近よく聞くオブザーバビリティについて、どうやって導入を進めれば良いかわからない・・・」
もし、あなたがシステム運用の現場でこのような疑問やモヤモヤを抱えているなら、この記事がその解決の一歩となるでしょう。
KDDIアイレットの MSP(Managed services provider)セクションは、お客様のクラウド環境における24時間365日の監視運用とサポートを担っています。
私たちは今、従来のシステム監視を超え、予測的なアプローチで未知の事象にも備える「オブザーバビリティ」の強化に注力しています。単なるアウトソースではなく、お客様の事業成長を支援する「次世代 MSP」への進化を目指しています。
本特集では、MSP セクションのリーダーである蓮沼が、以下のテーマを深く、そして幅広く解説します。
- オブザーバビリティの基本定義と、監視との決定的な違い
- なぜ今オブザーバビリティがビジネス現場で注目を集めているのか
- 実際のビジネス現場での活用方法と、具体的な導入事例
- システム運用の課題を解決に導くアプローチ
明日からの運用が変わる実践的な知見をお届けします。
また、iret.media では、KDDIアイレットのエンジニアたちが監視・運用実務を通して得たノウハウや、オブザーバビリティの基本から応用までを解説した記事を多数公開しています。
そちらもあわせてぜひご活用ください。
今注目されているオブザーバビリティとは
システムの複雑化に伴い、障害発生時の影響範囲が広域化し、根本原因の特定に長時間を要するケースが増えています。従来の監視手法では、システム全体の動作を可視化することが困難になり、障害対応の遅れがビジネスに深刻な損失をもたらすリスクが高まっています。
こうした課題を解決する新たなアプローチとして、近年「オブザーバビリティ」が大きな注目を集めています。
オブザーバビリティとは
オブザーバビリティとは可観測性とも言われ、システムの内部状態を外部から観測可能なデータに基づいて理解し、把握する能力のことです
オブザーバビリティでは、メトリクス、ログ、トレースなどの、システムの状態を表すテレメトリデータを使用して分散システムを詳細に可視化し、さまざまな問題の根本原因の究明やシステムのパフォーマンス向上を実現します。メトリクス、ログ、トレースのテレメトリデータは「オブザーバビリティの3つの柱」と呼ばれ、以下のような特徴があります。
オブザーバビリティの3つの柱
- ログ
特定の時点で発生したイベントのテキストレコードであり、発生日時を示すタイムスタンプとコンテキストを示すペイロードが記録されます。アプリケーションの動作やエラーの詳細な情報を提供します。
- メトリクス
アプリケーションやシステムの正常性やパフォーマンスを経時的に測定する時系列データです。CPU 使用率、メモリ消費量、レスポンス時間などの定量的な情報を提供します。
- トレース
分散アーキテクチャ全体で、エンドツーエンドのすべてのユーザーリクエストをコードレベルで記録します。複雑な分散システムにおけるリクエストの流れを追跡できます。
つまり、オブザーバビリティを導入すると、システムの外部から取得できる情報(メトリクス、ログ、トレース)を活用して、「なぜパフォーマンスが低下したのか」「なぜそれが起きたかを探り出すこと」といった、予測していなかった問題の根本原因まで特定できるようになります。
オブザーバビリティでできること
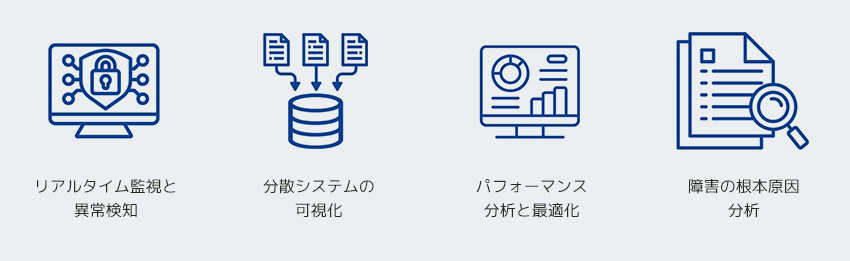
1. インフラ領域に留まらないリアルタイム監視と異常検知
従来の監視では検知できない未知の問題を早期に発見できます。例えばサーバーの負荷が正常に見えても、分散したアプリケーションの応答速度やエラーログを横断的に分析することで、ユーザーに影響が出る前に潜在的な障害を予測できます。これにより、システムトラブルを未然に防ぎ、サービスの安定性を大幅に向上させることができます。
2. 分散システムの可視化
複数のコンピューターやアプリケーションが連携するシステム全体の動作を、一つの画面で簡単に把握できます。例えば、ウェブサイトで商品を注文する際の処理が複数のシステム間をどのように流れているか、どこでエラーが発生しているか、どの部分が遅くなっているかを視覚的に確認できます。これにより、システムに問題が起きた時に原因箇所を素早く特定し、効率的に問題を解決することが可能になります。
3. パフォーマンス分析と最適化
システムの動作速度や処理能力を詳しく調べて、より快適に使えるように改善することができます。例えば、ウェブサイトの読み込みが遅い原因を特定し、画像のサイズを小さくしたり、データベースの処理を見直し、ユーザーが快適に利用できるようにします。この分析と改善により、システム全体のパフォーマンスを向上させ、ユーザー体験を大幅に改善することが可能になります。
4. 障害の根本原因分析
システムに問題が発生した際に、表面的な症状だけでなく、その問題を引き起こした本当の原因を深く掘り下げて調べることができます。例えば、ウェブサイトが突然アクセスできなくなった時、単にサーバーが停止したという事実だけでなく、なぜサーバーが停止したのか(メモリ不足、ネットワーク障害、プログラムのバグなど)まで詳しく分析します。この根本原因を特定することで、同じような問題の再発を防ぎ、システムの安定性を大幅に向上させることが可能になります。
オブザーバビリティと監視の違い
従来のシステム監視は、あらかじめ決められた項目をチェックして、問題が起きたときにお知らせする仕組みです。メモリの使用量、ウェブサイトの応答速度などを常に監視し、設定した基準値を超えると「問題が発生しました」という警告を出します。
しかし、この方法は異常を発見することだけに重点を置いているため、「何が起きているか」は分かっても「なぜそれが起きたか」までは分かりません。
一方、オブザーバビリティはシステムやアプリケーション内部の状態を外部から把握して、予期しない問題の根本原因まで特定できる仕組みとなっています。システムの様々な情報を組み合わせて分析することで、「なぜそれが起きたか」という問題の根本的な原因を特定することができます。
オブザーバビリティが注目される理由
時代の変化とともにビジネスが複雑化する今、システムの状態を常に把握し、トラブルに迅速に対応することは、事業成長に欠かせません。そのためオブザーバビリティの重要性が高まっています。
ここでは、オブザーバビリティが注目される理由を見ていきたいと思います。
複雑なシステムへの対応が可能
システムの複雑化に伴い、、AWS や Google Cloud で複数のマイクロサービスを組み合わせてシステムを構築することが一般的となりました。分散型システムは機能の追加・変更が容易で、スケーラビリティや可用性の観点で大きなメリットがある一方、マイクロサービス化やマルチクラウド化が進むにつれてシステム環境が複雑化し、従来のモニタリングではシステム全体を把握することが困難になりました。
このような複雑な分散環境において、オブザーバビリティはサービス間のリクエスト流れを追跡し、障害やボトルネックの発生箇所を迅速に特定できます。システム全体の健全性を包括的に把握することが可能になります。
システムの安定性向上による長期的なビジネス成長を促進
システムの安定性向上は、直接的に顧客体験とビジネス成果に影響します。オブザーバビリティによってシステムの問題を迅速に特定・解決することで、ダウンタイムの削減とパフォーマンス向上を実現できます。これにより、サービス停止による売上機会損失を防ぎ、顧客満足度の維持・向上につながります。また、システムの信頼性が高まることで競合他社に対する優位性を保持し、長期的なビジネス成長を支える基盤となります。
エンジニアの作業効率が向上
適切なオブザーバビリティツールにより、エンジニアの作業効率が向上し、創造的な業務により多くの時間を割けるようになります。また、原因の推測や発見に余計な時間と手間を取られることが少なくなり、いわゆる"アラート疲れ"も解消されます。
オブザーバビリティは DevSecOps の観点からも不可欠
DevSecOps とは、開発(Development)・セキュリティ(Security)・運用(Operations)を統合したソフトウェア開発・運用手法です。
従来は開発、セキュリティチェック、運用という順次的なプロセスでしたが、DevSecOps では開発の初期段階からセキュリティを組み込み、継続的にセキュリティテストや脆弱性チェックを自動化します。
DevSecOps はオブザーバビリティによって強化されるため、DevSecOps の継続的なセキュリティ監視とリスク管理を可能にするために不可欠です。
オブザーバビリティを活用したビジネスシーンでのユースケース
オブザーバビリティは、ビジネスシーンにおいて多岐にわたる活用が可能です。オブザーバビリティを活用することで、障害対応の迅速化、システム信頼性の向上、運用コストの削減、開発生産性の向上、ビジネス継続性の強化が期待できます。
IT・技術部門
- 分散トレーシングによる障害の即座の特定と復旧時間の短縮: 分散トレーシングによってリクエストの全体フローを可視化し、障害発生時にどのコンポーネントで問題が起きているかを即座に特定できます。メトリクスとログを相関させることで平均復旧時間を大幅に短縮し、根本原因分析にかかる時間を削減できます。
- 異常検知による障害の予兆把握と計画的メンテナンス: 異常検知により通常パターンから逸脱した挙動を自動識別し、メモリリークやディスク容量枯渇といった潜在的問題を早期発見できます。これにより計画的なメンテナンスでの対応が可能となり、予期せぬダウンタイムを防止します。
- データに基づくインフラ需要予測とコスト最適化: 長期的なリソース使用傾向を分析し、将来的なインフラ需要を正確に予測できます。トラフィックパターンやピーク時負荷の分析により、過剰プロビジョニングとリソース不足のバランスを最適化し、クラウド環境での運用コスト削減を実現します。
- SLO 達成状況の可視化とリリース判断の最適化: レスポンスタイムや可用性、エラーレートといった重要指標を継続的に計測し、SLO(サービスレベル目標)の達成状況を可視化できます。エラーバジェットの消費状況を把握しながら、新機能リリースと安定性のバランスを取った意思決定が可能になります。
開発・DevOps 部門
- 本番環境でのパフォーマンスボトルネック特定と最適化: 本番環境における実際のコード動作を詳細に分析し、パフォーマンスボトルネックや非効率なクエリを特定できます。スローなデータベースクエリや不要な API コール、メモリ使用量の多い処理を可視化することで、優先順位を付けた最適化が可能になります。
- 安全なデプロイメントとリリース影響の即時評価: 新バージョンのデプロイ前後でシステム挙動を比較分析し、リリースの影響を即座に評価できます。カナリアデプロイメントと組み合わせることで、エラーレートやレスポンスタイムを監視し、問題検出時には自動ロールバックする安全なデプロイメントを実現します。
- データに基づく技術的負債の可視化と優先順位付け: システム全体の依存関係やコンポーネント間の結合度を可視化し、レガシーコードや改善が必要な領域を客観的に評価できます。パフォーマンスメトリクスとエラーログの長期分析により、頻繁に問題を引き起こすモジュールを定量的に把握できます。
- 環境横断の可視化による開発サイクルの高速化: 開発環境からステージング、本番環境まで一貫したオブザーバビリティを実現することで、問題の早期発見と迅速な修正が可能になります。詳細なトレース情報により他チームのマイクロサービス動作を理解しやすくなり、分散システム全体の生産性が向上します。
プロダクト・ビジネス部門
- リアルユーザーモニタリングによる実体験の把握と UX 改善: リアルユーザーモニタリング(RUM)で実際のユーザーがどのようにプロダクトを利用しているかを把握できます。ページロード時間やインタラクティブ性を地域別、デバイス別に分析し、特定セグメントのパフォーマンス問題を特定してユーザー体験向上につなげられます。
- システム性能とビジネス成果の相関分析による投資判断: 技術的メトリクスとビジネス KPI を統合監視し、システムパフォーマンスがビジネス成果に与える影響を測定できます。決済処理のレスポンスタイムと購入完了率の相関を分析することで、技術投資の優先順位をビジネス価値に基づいて判断できます。
- A/B テストにおけるパフォーマンスと成果指標の統合評価: 新機能や UI 変更の効果測定時に、成果指標だけでなく各バリエーションのシステムパフォーマンスやエラー発生率を同時分析できます。セグメント別の詳細分析により、特定ユーザーグループに最適な体験を提供するパーソナライゼーション戦略を立案できます。
- カスタマージャーニーの可視化と不正利用の早期検知: ユーザーの行動パターンを時系列で追跡し、カスタマージャーニー全体を可視化することで顧客理解を深められます。機能の利用頻度や遷移パターンを分析し、価値の高い機能や改善領域を特定できるほか、異常な利用パターンから不正利用を早期発見できます。
セキュリティ・コンプライアンス部門
- 統合ログ分析によるセキュリティ脅威のリアルタイム検知: システム全体のログとメトリクスを統合分析し、セキュリティ脅威をリアルタイムで検知できます。不正アクセスの試みや異常なトラフィックパターン、権限昇格の兆候を自動識別し、攻撃の早期発見と対応を実現して組織のセキュリティポスチャーを強化します。
- 監査証跡の自動収集による規制準拠と監査対応の効率化: 監査証跡を自動収集し、コンプライアンス報告を効率化できます。システムへのアクセス記録やデータ操作履歴を詳細に記録することで、GDPR や SOC2 などの規制に準拠した証拠を提供でき、監査対応の負担を軽減します。
- プロアクティブな脅威探索による攻撃の事前阻止: プロアクティブに潜在的なセキュリティ脅威を探索し、既知の攻撃パターンや異常な挙動を発見できます。過去のインシデントパターンを学習して類似の兆候を早期検知することで、攻撃が成功する前に対処でき、組織のリスクを低減します。
- 詳細トレースによる攻撃全体像の把握と被害の最小化: セキュリティインシデント発生時に、詳細なトレースとログ情報により攻撃の全体像を迅速に把握できます。侵入経路や影響範囲、データアクセス状況を時系列で再構築し、効果的な封じ込めと根絶を実施してダウンタイムとビジネス影響を最小限に抑えます。
経営・マネジメント層
- システム依存関係の可視化による事業継続リスクの事前評価: システム全体の健全性とリスク要因を包括的に可視化し、事業継続計画の実効性を高められます。重要ビジネスプロセスを支えるコンポーネントの依存関係を明確にし、単一障害点を特定することで災害時の影響範囲を事前評価できます。
- 投資効果の定量化によるオブザーバビリティ導入の正当性証明: オブザーバビリティへの投資効果を定量的に示せます。障害による損失時間削減、インフラコスト最適化、開発生産性向上といった成果を金額換算し、顧客体験改善によるコンバージョン率向上など、ビジネス成果への貢献を明確にできます。
- リアルタイムデータに基づく戦略的意思決定の迅速化: リアルタイムデータに基づいた迅速な意思決定を可能にします。市場投入時間短縮や新機能パフォーマンス評価、ユーザー反応の即座把握により、戦略的方向転換や投資判断をデータドリブンで行い、経営資源の最適配分を実現できます。
- 継続的な最適化による市場競争優位性の確立と維持: システムパフォーマンスと顧客体験を継続的に最適化し、市場における競争優位性を維持できます。競合他社と比較したサービス品質を定量評価して差別化ポイントを明確にし、迅速なイノベーションサイクルを支える技術基盤として長期的な競争力を構築します。
オブザーバビリティ導入の実例で学ぶシステム運用課題解決のヒント
システムの信頼性向上と DX を加速させた、オブザーバビリティの導入事例をご紹介いたします。
複数の AWS 環境を統合的にモニタリング、オブザーバビリティ強化でサービス品質向上を実現
株式会社カーフロンティア様では、複数の AWS 環境を運用している中で、サービス障害発生時に原因を特定するのに時間がかかる状況でした。従来のインフラ監視やサービスの維持だけでなく、さらなるサービスレベルの向上につながるオブザーバビリティの強化や指標の見直しが課題となっていました。
そこで、New Relic One の導入支援を実施。統一的なプラットフォーム上で障害発生から原因特定までのリードタイム改善、監視設定の手動設定からコード管理への置き換えによる管理コスト削減、アプリケーションやブラウザなどのインフラレイヤー以外のオブザーバビリティ強化を実装しました。
New Relic One の導入により、SLI(サービスレベル指標)/ SLO(サービスレベル目標)を策定し、サービスの信頼性を維持しながらユーザー体験の継続的な改善活動が可能になりました。
株式会社カーフロンティア様の導入事例はこちら
フルスタックオブザーバビリティで運用改善サイクルを確立、継続的なサービス品質向上を実現
株式会社電通クリエイティブピクチャーズ様では、システム監視において、アラートやサービス稼働状況の全体像を把握しづらい状況で、障害発生時にアプリケーション側に問題が発生した際には、原因特定に時間を要するリスクが生じておりました。また、定期的に監視設定を見直し、運用を最適化するプロセスがないことが課題となっていました。
そこで、New Relic のサービスレベル機能を導入して SLI(サービスレベル指標)と SLO(サービスレベル目標)を設定、取得データをもとにダッシュボードを構築し、定期的なオブザーバビリティレポートとレビューミーティングの実施による継続的な運用改善・最適化を推進する仕組みを実装しました。これにより、Web サイトのサービス水準を評価できるようになり、システム状況の全体像を把握し、定期的に監視・運用の最適化を行う機会創出が実現しました。
本プロジェクトの結果、システム監視の全体像を把握し、サービスレベルを可視化する仕組みを実現。定期的なオブザーバビリティレポートとレビューミーティングの実施により、継続的な運用改善を促進しています。
株式会社電通クリエイティブピクチャーズ様の導入事例はこちら
AWS 環境に分散していた100台以上のシステムリソースを一元管理、Terraform による IaC 化で運用改善を実現
株式会社エナリス様では、既存監視製品から Datadog への移行を検討していたものの、社内に十分な知見がなく、監視リソースの設定が煩雑になっており、現行の監視設計を見直す必要がありました。また、インフラレイヤーだけでなく、アプリケーションレイヤーも含めたオブザーバビリティの強化が求められていました。
そこで、既存製品から Datadog へ全面移行し、AWS 環境に分散していた100台以上のシステムリソースを一元管理可能にしました。APM 導入と共に、可視化ダッシュボードの作成・整備を実施。ログ監視や Synthetics の導入検討・一部実装を通じて可視化レベルを段階的に向上させました。また、監視モニターの構成を Terraform により IaC 化し、設定の標準化・再利用性向上・構成ミス防止を実現しました。
Datadog の導入により、インフラからアプリケーションレイヤーまでを横断した統合的な可視化が可能となり、障害につながり得るサインをプロアクティブに把握できる環境の構築を実現。新規環境への迅速な展開も可能になりました。
株式会社エナリス様の導入事例はこちら
生成 AI の回答精度評価と運用監視を自動化し、年間31人日分の工数削減を実現
社内向けの生成 AI ソリューション「cloudpack サポートデータ検索システム」の運用において、生成 AI による回答の成否判定・集計を手動で行なっていたため、年間で数十人日規模の大きな工数がかかっていました。また、トークン消費量や API コストなどのパフォーマンス指標の可視化ができておらず、迅速な改善サイクルを回すことが困難でした。
そこで、RAG 評価フレームワークである「Ragas」を導入し、現場の判断基準に基づくカスタム指標で回答精度の自動判定を確立しました。さらに、Datadog の「LLM Observability」と連携し、パフォーマンス指標を問い合わせ単位でリアルタイムにトレース・可視化する基盤を構築しました。
この取り組みにより、最大の課題であった判定作業を完全に自動化し、年間で31.2人日分の工数削減を達成しました。また、分析頻度が週次からニアリアルタイムに向上し、精度向上サイクルを迅速に回せる体制が整い、運用効率と品質の両面で大幅な改善を実現しました。
KDDIアイレット株式会社の導入事例はこちら
【まとめ】次世代 MSP への挑戦:監視から予測へ
システムの複雑化が進む現代において、オブザーバビリティは従来の監視を超えた重要な技術となっています。既知の問題への対処に留まらず、未知の問題の発見と根本原因の特定を可能にし、メトリクス、ログ、トレースなどのテレメトリデータを活用してシステムの深い理解を実現します。導入事例が示すように、オブザーバビリティはシステム運用の効率化、サービス品質向上、そして顧客満足度向上まで、組織全体に効果をもたらします。
クラウドネイティブな分散システムが主流となる中、組織全体でシステム状況を共有し、迅速な意思決定を行える環境構築が競争優位性につながります。また、オブザーバビリティは、DevSecOps の観点からも欠かせません。
KDDIアイレットでは、お客様の新しい価値創出と成長を高いレベルで実現する真のパートナーを目指しており、システムのモニタリングや運用・監視を担うManaged Service Provider(MSP)の専門チームが中心となってオブザーバビリティの強化を積極的に推進しています。
また、未知の事象に備える予防的なアプローチへの変革を「次世代MSP」として定義し、生成 AI の活用と内製化支援の強化を行ない、従来のインフラ監視から一歩進んだMSP サービスを目指しています。
オブザーバビリティの強化にご関心のある方は、ぜひお気軽にご相談ください。