
【Datadog初心者向け】APMハンズオン体験記!エラー調査からパフォーマンス改善まで
こんにちは!
これから仕事でDatadogを使う機会が増えそうなので、基本をしっかり学ぶためにAPM(Application Performance Monitoring)のハンズオンセミナーに参加してみました。
この記事では、セミナーで実際に体験した内容に沿って、僕が「これってどういうこと?」「なんでこうなるの?」と疑問に思ったポイントを調べ、解決していくプロセスをブログにまとめています。同じようにDatadogを学び始めた方の参考になれば嬉しいです!
Part 1: APMの用語解説
ハンズオンを進める上で、いくつか基本的な用語が出てきます。僕も最初は混乱したので、先にここで整理しておきます。
APMとは?
APMは「Application Performance Monitoring」の略で、日本語では「アプリケーションパフォーマンス監視」と訳されます。これは、アプリケーションがユーザーにとって快適に動いているか、問題が発生していないかを監視し、もし「遅い」「エラーが出ている」といった問題があれば、その原因をすばやく特定するための仕組みやツールのことです。
主要な用語の関係
APMの各用語は、大きなものから小さなものへと階層構造になっています。セミナーではレストランでの注文に例えていて、分かりやすかったのでご紹介します。
- サービス (Service): レストランの各部門(キッチン、ドリンクバーなど)
- リソース (Resource): 各部門が作る具体的な商品(「ステーキを焼く」「ジュースを作る」など)
- トレース (Trace): お客様の一連の注文全体(「ステーキとジュースをください」という1回の注文)
- スパン (Span): 注文をこなすための個々の作業(「肉を焼く」「盛り付ける」「ジュースを注ぐ」など)
各用語の解説
サービス (Service)
アプリケーションを構成する、独立した機能のまとまりです。ECサイトで例えるなら、「商品カタログ機能」「決済機能」「ユーザー認証機能」などがそれぞれサービスにあたります。マイクロサービスアーキテクチャでは、このサービス単位でプログラムが作られます。
レストランの例:「キッチン」「ドリンクバー」「レジ」など、役割ごとの部門。
リソース (Resource)
サービスが担当する具体的な処理やエンドポイントのことです。「商品カタログサービス」の中にある、「特定の商品ページを表示する処理 (GET /products/123)」や「商品を検索する処理 (GET /search?q=…)」がリソースです。
レストランの例:キッチン(サービス)が担当する「ステーキを焼く」「サラダを盛り付ける」といった具体的な調理工程。
トレース (Trace)
ユーザーが行った1回のリクエストが、アプリケーション内をどのように伝播し、処理されたかの一連の流れを記録したものです。
例えば、ユーザーが「購入ボタン」を押してから「購入完了」が表示されるまで、裏側では認証サービス、在庫確認サービス、決済サービスなどが連携して動きます。この一連の処理全体を1つのトレースとして記録します。
レストランの例:お客様が「ステーキとジュースをお願いします」と注文してから、全てがテーブルに届くまでの一連の流れ全体。
スパン (Span)
トレースを構成する、個々の処理単位です。1つのトレースは、複数のスパンで構成されます。各スパンには、処理の名前、開始時刻、処理時間が記録されており、どの処理にどれだけ時間がかかったかを正確に把握できます。
レストランの例:ステーキとジュースの注文(トレース)をこなすための、「肉を焼き始める→焼き終わる」(スパン1)、「ジュースを注ぎ始める→注ぎ終わる」(スパン2)、「レジで会計する」(スパン3)といった個々の作業。
Part 2: 【ハンズオン本編】エラーを特定して修正しよう
さて、用語を頭に入れたところで、いよいよハンズオン本編のレポートです!
ハンズオンは、ECサイト風のアプリがすでに動いている環境でスタート。最初のミッションは「発生しているエラーを見つけて修正する」という、いかにも実践的なものでした。
STEP 1: アプリの全体像を把握する
まずはDatadogにログインし、左のメニューからAPM > サービスマップを選択。すると、各サービスがどのように連携しているか、こんな感じの図で一発で分かります。
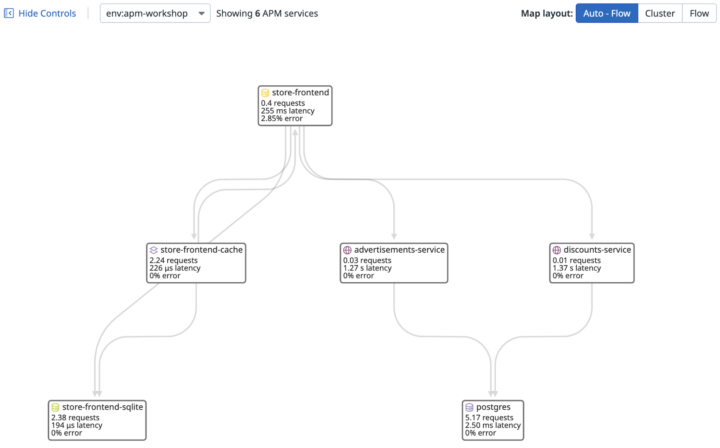
store-frontendというサービスが中心にいて、いくつかのサービスを呼び出している構成です。
まずはこの全体像を頭に入れます。
STEP 2: エラーを発見!
次に、同じく左メニューのAPM > サービスをクリックして、サービス一覧(サービスカタログ)を開きます。ここで各サービスのヘルスステータスが一覧できるんですが、案の定いました。
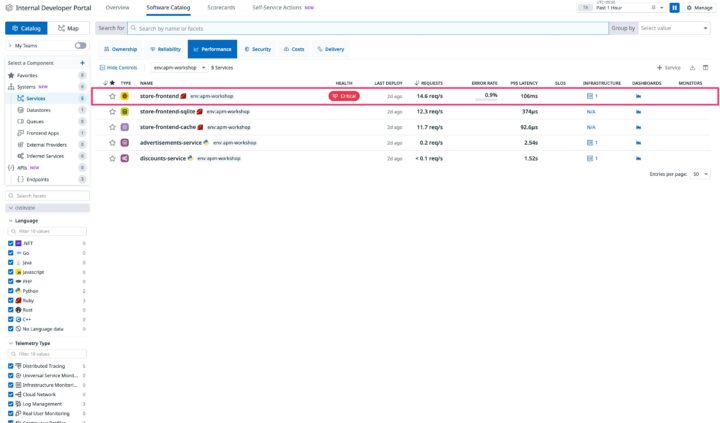
store-frontendが真っ赤です。エラーレートも表示されていて、store-frontendサービスにエラーが発生していることを示しています。
STEP 3: エラーの原因を特定
原因を特定するために、この真っ赤なstore-frontendサービスの行をクリックします。すると、サービスの詳細画面にジャンプします。
画面上部のタブからリソースを選ぶと、このサービス内のどの処理(エンドポイント)でエラーが出ているのかが分かります。
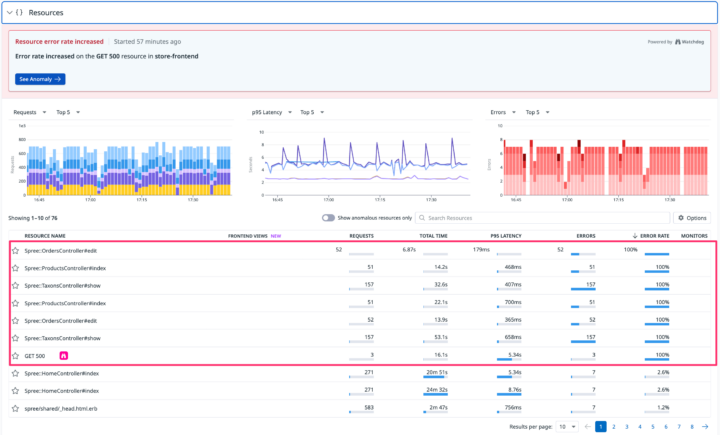
トレース一覧を見ると、赤いエラーがたくさん並んでいますね。この中から一つを選んで、さらに詳細画面へ。
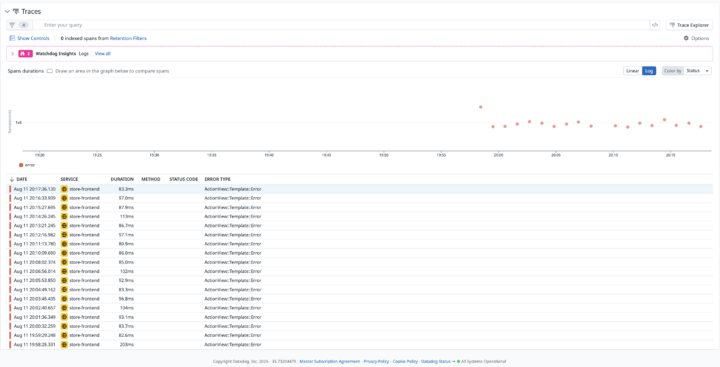
最終的に、エラーの詳細画面で根本原因が判明しました。
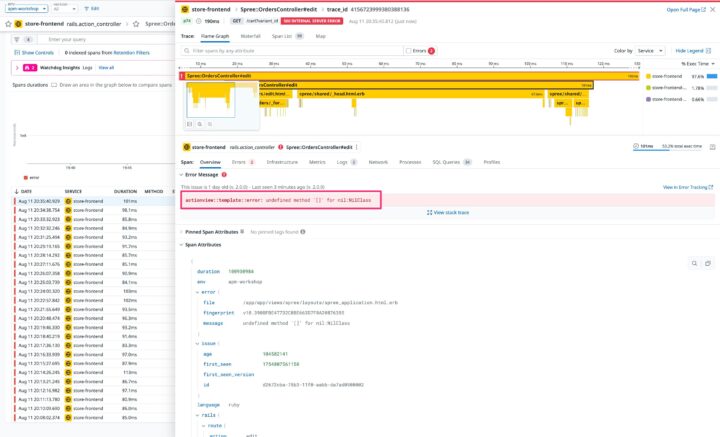
undefined method ‘[]’ for nil:NilClass
これはRubyなどでおなじみのエラー。「中身が空っぽ(nil)のデータに対して、何か処理しようとしてコケた」ってことですね。
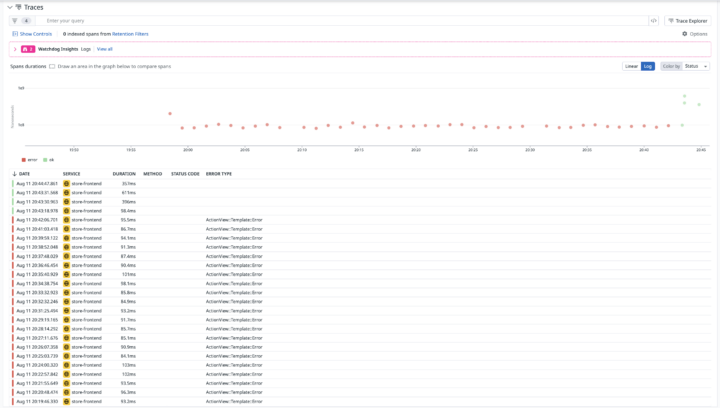
エラーが特定できたので、被疑箇所のコードを修正します。するとトレース一覧もこの通り緑色になりました!
Part 3: パフォーマンスのボトルネックを改善!
エラーは直りましたが、まだ終わりじゃありません。次は、サイトの動作を重くしている「パフォーマンスのボトルネック」を探し出すミッションです。
STEP 1: なんだか遅いサービスを発見
もう一度APM > サービスの一覧に戻ってみます。今度はエラーレートではなく、P95 LATENCYの列名をクリックして、応答が遅い順に並べ替えてみましょう。
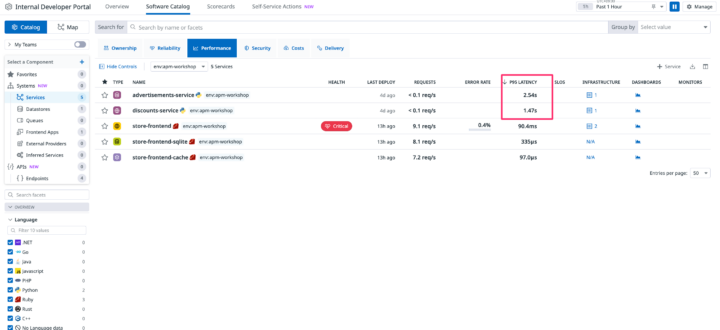
すると、advertisements-serviceとdiscounts-serviceが他に比べて明らかに遅いことが分かります。これがサイト全体の重さの原因になっていそうです。
🤔ポイント①「P95レイテンシ」
ここで僕が「ん?」と疑問に思ったのが、数値の矛盾です。「advertisements-service(2.56s)を呼んでいるstore-frontend(335ms)は、2.56秒より速いとおかしくない?」
調べて分かったのは、P95は平均値ではなく「外れ値」を見るための統計値だということ。すごく遅いリクエスト上位5%の値なので、たまに発生する激重リクエストを捉えるんです。
例えば、シェフ(advertisements-service)が焼くステーキのP95が25分でも、ウェイター(store-frontend)は高速なドリンク注文もたくさん受けるので、ウェイターの全仕事のP95は10分になる、みたいなイメージです。
つまり、store-frontendは遅い処理(広告)を呼ばないリクエストもたくさんあるから、全体のP95は低く見えていた、という訳でした。
STEP 2: ボトルネックを一つずつ潰していく
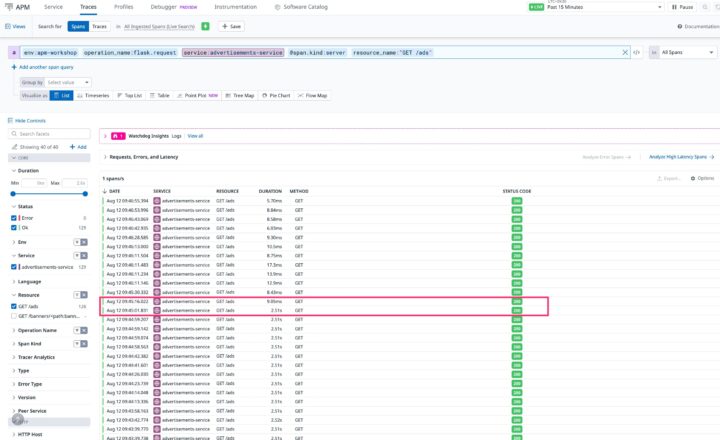
ボトルネックの調査を再開。まずは一番遅いadvertisements-serviceをクリックしてサービス詳細画面を開きます。トレース一覧を見ると、多くのリクエストに2.5秒以上かかっていることが確認できます。
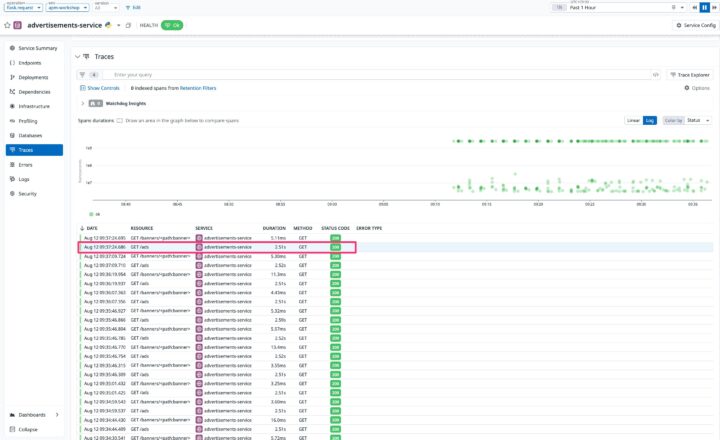
原因はソースコードに書かれていたtime.sleep(2.5)という、意図的に2.5秒待たせる処理でした。これを削除すると、処理時間は劇的に改善!
Part 4: SQLクエリを最適化
そして、次のボトルネックであるdiscounts-serviceを調査します。エラー修正後、store-frontendのトレースを改めて見てみると、今度はdiscounts-serviceの処理時間が大半を占めていることがフレームグラフから分かります。
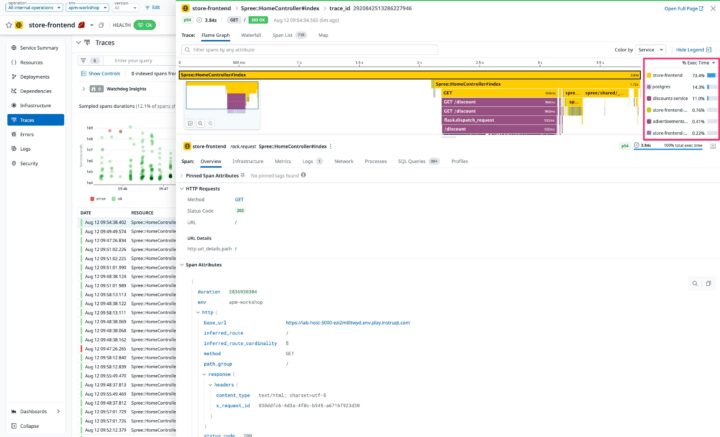
このdiscounts-serviceをクリックして、さらに詳細を追っていきます。
🤔ポイント②「N+1問題の見つけ方」
パフォーマンスを悪化させる原因として有名な「N+1クエリ問題」。DBへの問い合わせがループ処理の中で何度も実行されて遅くなる、というアレです。知識としては知っていましたが、Datadogでどうやって見つけるのか?
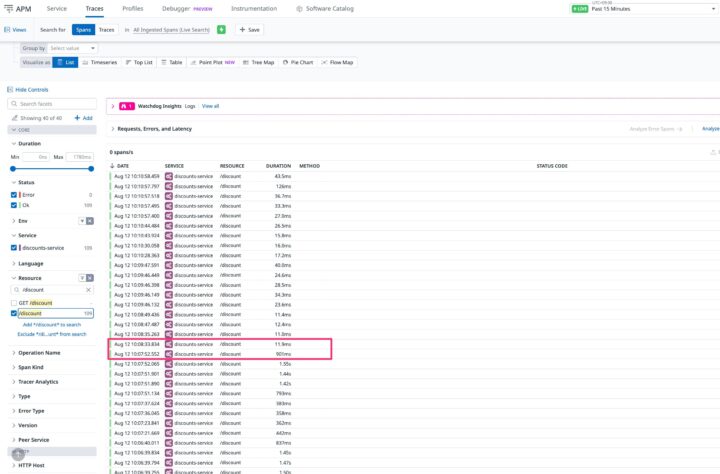
答えは、トレース詳細画面の下部にあるSpan Summaryにありました。
AVG SPANS/TRACE(1リクエストあたりの平均実行回数)を見ると、DBへの問い合わせ(
postgres.query)が平均200回以上も走っています。これが「ループ処理で何度もDBにアクセスしている」動かぬ証拠です。これが見つけられるのは本当に強力ですね!

このN+1問題もコードを修正し、アプリケーション全体のパフォーマンスが大幅に改善されました。
まとめ
というわけで、Datadog APMハンズオンの体験記でした!
単にエラーを通知してくれるだけでなく、クリック操作でドリルダウンしていくことで原因がどこにあるのかを深掘りしたり、今回のようにパフォーマンスを低下させている根本的な問題を発見したりできるのが、Datadogの本当にすごいところだなと実感しました。
これから業務で使うのが、ますます楽しみになりました!
Information
以下のような課題でお困りのお客様はぜひ当社にご相談ください。
サービス障害時にインフラ観点だけでなく、俯瞰的なボトルネック調査を行い、問題の特定・解決を早めたい
Daadog の導入は決まったものの、ノウハウもなくどうしたらいいかわからない
お客様の課題に合わせて、当社が提供するサービスをご提案させていただきます。
ぜひお気軽にアイレットへご相談ください。



