

EMRがImpalaをサポートするようになりました。ImpalaはClouderaが提供するオープンソースのクエリエンジンで、Hiveより断然速いそうです。
例として、Cloudfrontのログを、タイムスタンプをJSTに直して1時間ごとのアクセス数の集計をしてみます。
ログバケットの確認
まずCloudFrontのログが以下のS3にたまっているとします。
s3://memorycraft-impala-input/cf/logs
EMRクラスタの起動
次に、EMRクラスタを起動します。
EMRのダッシュボードで「Create Cluster」をクリックし、新規クラスタ作成画面を表示します。
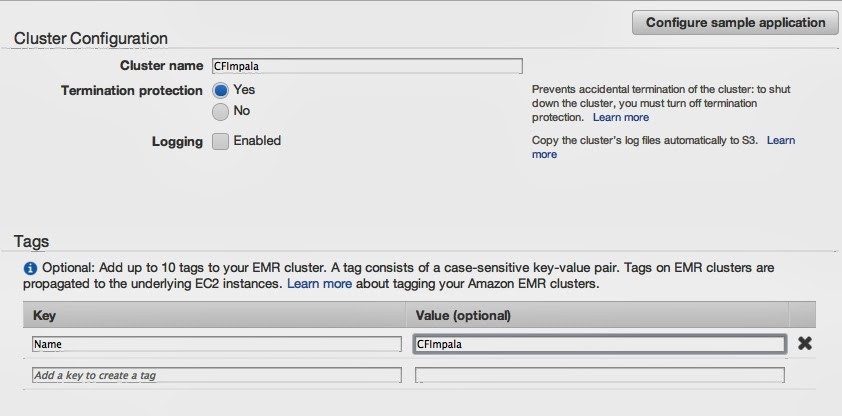
Cluster Configuration
Cluster nameに適当なクラスタ名を入力します。また、今回はEMRのログは出力しないのでLoggingのチェックはOFFなんかにしておきます。起動したインスタンスの名前をつける場合は、TagsのNameとしてインスタンス名をつけておきます。
Software Configuration
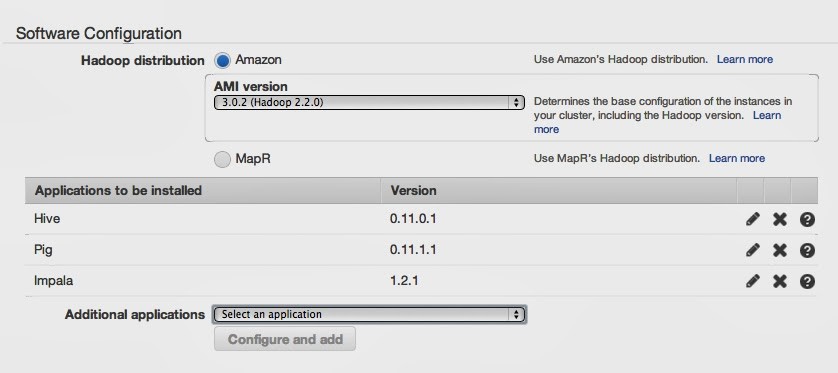
Hadoopのバージョンとアプリケーションのリストを設定します。
Applications to be installedのリストにはデフォルトでHiveとPigが追加されていますが、
AMI versionは現時点で最新の3.0,2を選ぶち、下のAdditional applicationsのドロップダウンでImpalaが選択できるようになります。
Impalaを選択し、「Configure and add」をクリックして追加します。
Hardware Configuration
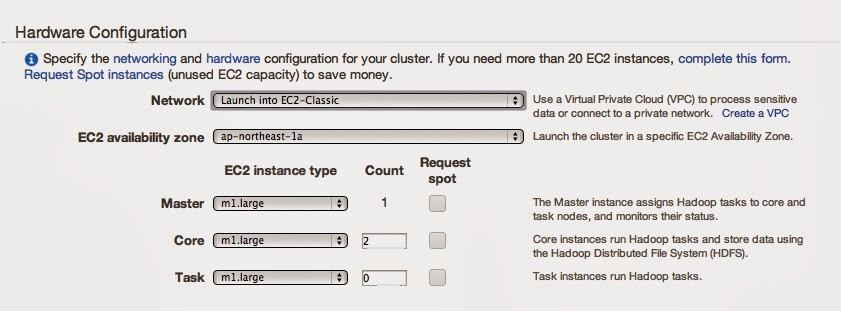
ここでVPCやゾーンやインスタンス数を設定します。
ここでは、EC2-Classicで、ゾーンはA、インスタンス数はデフォルトにしてみます。
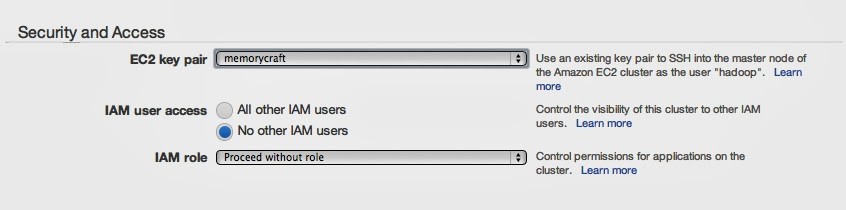
Security and Access
EC2 key pairで、hadoopインスタンスに接続するときのキーペア名を設定します。
ここが未定義だと、インスタンスに接続できないので注意が必要です。
Bootstrap Actions & Steps
ここでは、起動した後の挙動や起動パラメータなどを定義します。
今回は未設定のままでOKです。
最後に「Create cluster」ボタンをクリックして、クラスタを作成します。

EMRのインスタンスへの接続
起動完了するとクラスタ詳細画面で、Master public DNSに、マスタインスタンスのPublicDNSが表示されます。
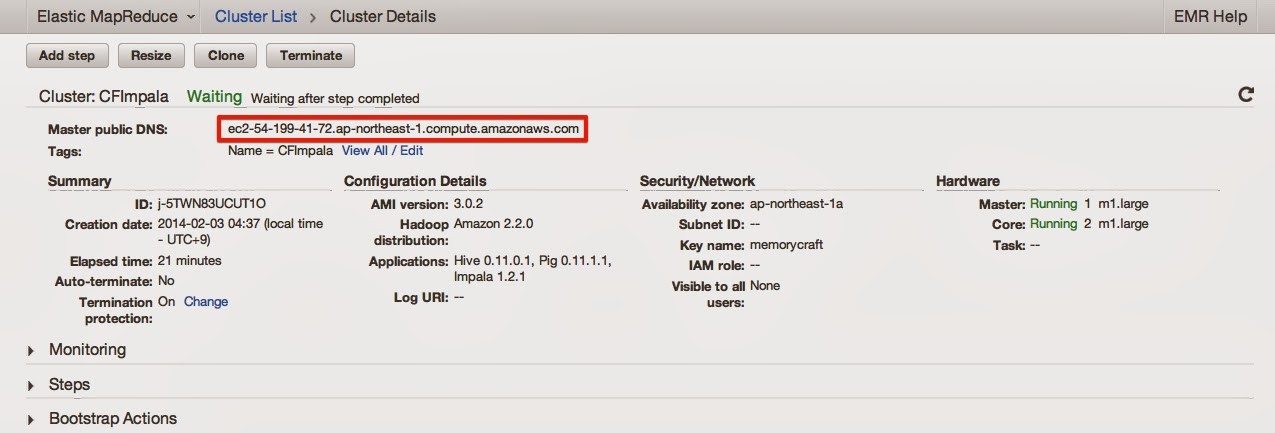
そのPublicDNSに対して、先ほど選択した鍵を使ってhadoopユーザーでSSH接続します。
$ ssh -i ~/.ssh/keys/memorycraft.pem hadoop@ec2-54-199-41-72.ap-northeast-1.compute.amazonaws.com The authenticity of host 'ec2-54-199-41-72.ap-northeast-1.compute.amazonaws.com (54.199.41.72)' can't be established. RSA key fingerprint is 0f:ac:d5:8d:50:2b:7c:92:6a:ad:74:5e:f3:d1:52:05. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'ec2-54-199-41-72.ap-northeast-1.compute.amazonaws.com,54.199.41.72' (RSA) to the list of known hosts. __| __|_ ) _| ( / Amazon Linux AMI ___|___|___| https://aws.amazon.com/amazon-linux-ami/2013.09-release-notes/ 13 package(s) needed for security, out of 46 available
Run "sudo yum update" to apply all updates.
Welcome to Amazon Elastic MapReduce running Hadoop and Amazon Linux. Hadoop is installed in /home/hadoop. Log files are in /mnt/var/log/hadoop. Check /mnt/var/log/hadoop/steps for diagnosing step failures. The Hadoop UI can be accessed via the following commands: ResourceManager lynx http://localhost:9026/ NameNode lynx http://localhost:9101/
$
接続が完了しました。
S3データのコピー
現状、ImpalaでExternalテーブルにS3のパスを直接指定するとエラーになってしまいました。方法がわからなかったため、S3DistCpでHDFS上の/input/にコピーしてきます。
$ vim ./import.sh
!/bin/bash
. /home/hadoop/impala/conf/impala.confhadoop jar /home/hadoop/share/hadoop/common/lib/EmrS3DistCp-1.0.jar -Dmapreduce.job.reduces=30 --src s3://memorycraft-impala-input/cf/logs/ --dest hdfs://$HADOOP_NAMENODE_HOST:$HADOOP_NAMENODE_PORT/input/ --outputCodec 'none'
$ chmod 755 ./import.sh $ ./import.sh 14/02/02 20:12:41 INFO s3distcp.S3DistCp: Running with args: -Dmapreduce.job.reduces=30 --src s3://memorycraft-impala-input/cf/logs/ --dest hdfs://172.31.0.95:9000/input/ --outputCodec none 14/02/02 20:12:41 INFO s3distcp.S3DistCp: S3DistCp args: --src s3://memorycraft-impala-input/cf/logs/ --dest hdfs://172.31.0.95:9000/input/ --outputCodec none 14/02/02 20:12:45 INFO s3distcp.S3DistCp: Using output path 'hdfs:/tmp/8f7379de-1ebf-4f31-be50-bd17aa54f2d5/output' 14/02/02 20:12:46 INFO s3distcp.S3DistCp: GET http://169.254.169.254/latest/meta-data/placement/availability-zone result: ap-northeast-1a 14/02/02 20:12:46 INFO s3distcp.S3DistCp: Created AmazonS3Client with conf KeyId XXXXXXXXXXXXXX 〜(中略)〜 Combine output records=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=3406 File Output Format Counters Bytes Written=0 14/02/02 20:13:37 INFO s3distcp.S3DistCp: Try to recursively delete hdfs:/tmp/8f7379de-1ebf-4f31-be50-bd17aa54f2d5/tempspace
コピーの実行が終わりました。HDFSの内容を見ると、コピーされているのが分かります。
$ hadoop fs -ls /input/ Found 20 items -rw-r--r-- 1 hadoop supergroup 1728 2014-02-02 20:13 /input/E2KNLXPGJLJRRQ.2014-01-30-07.21fcnUK5 -rw-r--r-- 1 hadoop supergroup 1726 2014-02-02 20:13 /input/E2KNLXPGJLJRRQ.2014-01-30-07.9jiEU8sU -rw-r--r-- 1 hadoop supergroup 1477 2014-02-02 20:13 /input/E2KNLXPGJLJRRQ.2014-01-30-07.9pD0UZAy -rw-r--r-- 1 hadoop supergroup 4996 2014-02-02 20:13 /input/E2KNLXPGJLJRRQ.2014-01-30-07.CECpH1q4 -rw-r--r-- 1 hadoop supergroup 3636 2014-02-02 20:13 /input/E2KNLXPGJLJRRQ.2014-01-30-07.DmeAD298 -rw-r--r-- 1 hadoop supergroup 979 2014-02-02 20:13 /input/E2KNLXPGJLJRRQ.2014-01-30-07.GhmYMPjI -rw-r--r-- 1 hadoop supergroup 1915 2014-02-02 20:13 /input/E2KNLXPGJLJRRQ.2014-01-30-07.IvAE5n9h -rw-r--r-- 1 hadoop supergroup 1853 2014-02-02 20:13 /input/E2KNLXPGJLJRRQ.2014-01-30-07.K3Crm40n -rw-r--r-- 1 hadoop supergroup 6120 2014-02-02 20:13 /input/E2KNLXPGJLJRRQ.2014-01-30-07.KILmQ81g -rw-r--r-- 1 hadoop supergroup 969 2014-02-02 20:13 /input/E2KNLXPGJLJRRQ.2014-01-30-07.KdRXIw4s -rw-r--r-- 1 hadoop supergroup 1731 2014-02-02 20:13 /input/E2KNLXPGJLJRRQ.2014-01-30-07.MIAnZGc4
Impalaの実行
Impalaはimpala-shellというコマンドで専用のプロンプトを起動して使います。hiveのhiveコマンドと同じようなものです。
$ impala-shell Starting Impala Shell without Kerberos authentication Connected to ip-10-146-59-193.ap-northeast-1.compute.internal:21000 Server version: impalad version 1.2.1 RELEASE (build 8c1da7709727f3545974009a4bb677a0004024ec) Welcome to the Impala shell. Press TAB twice to see a list of available commands.Copyright (c) 2012 Cloudera, Inc. All rights reserved.
(Shell build version: Impala Shell v1.2.1 (8c1da77) built on Sun Dec 1 20:57:24 PST 2013) [ip-10-146-59-193.ap-northeast-1.compute.internal:21000] >
まずは、入力テーブルをつくります。ファイルの場所はS3DistCpのコピー先に指定した/input/を指定します。
[ip-10-146-59-193.ap-northeast-1.compute.internal:21000] > CREATE EXTERNAL TABLE IF NOT EXISTS input ( cf_date STRING, cf_time STRING, x_edge_location STRING, sc_bytes INT, c_ip STRING, cs_method STRING, cs_host STRING, cs_uri_stem STRING, sc_status STRING, cs_referrer STRING, cs_user_agent STRING, cs_uri_query STRING, cs_cookie STRING, x_edge_result_type STRING, x_edge_request_id STRING, x_host_header STRING, cs_protocol STRING, cs_bytes INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/input/';
それでは、クエリを実行してみます。
[ip-10-146-59-193.ap-northeast-1.compute.internal:21000] >
SELECT
w.jsttime,
count(mydata)
FROM
(
SELECT
SUBSTR(
CAST(
FROM_UTC_TIMESTAMP(
FROM_UNIXTIME(
UNIX_TIMESTAMP(CONCAT(cf_date, " ", cf_time), 'yyyy-MM-dd HH:mm:ss')
), 'JST'
) as STRING
), 1, 13
) AS jsttime,
'AAA' AS mydata
FROM
input
WHERE
cf_date NOT LIKE '#%'
) w
GROUP BY
w.jsttime
;
Query: select w.jsttime, count(mydata) from (select substr(cast(from_utc_timestamp(from_unixtime(unix_timestamp(concat(cf_date, " ", cf_time), 'yyyy-MM-dd HH:mm:ss')), 'JST') as STRING), 1, 13) as jsttime, 'AAA' as mydata from input where cf_date not like '#%') w group by w.jsttime
+---------------+---------------+
| jsttime | count(mydata) |
+---------------+---------------+
| 2014-01-30 16 | 95 |
| 2014-01-30 17 | 33 |
+---------------+---------------+
Returned 2 row(s) in 0.88s
1秒かかりませんでした。
Hiveとの速度比較
これと同じ集計をHiveで行ってみます。
Total MapReduce jobs = 1 Launching Job 1 out of 1 Number of reduce tasks not specified. Estimated from input data size: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=In order to limit the maximum number of reducers: set hive.exec.reducers.max= In order to set a constant number of reducers: set mapred.reduce.tasks= Starting Job = job_1391362544864_0002, Tracking URL = http://10.132.128.116:9046/proxy/application_1391362544864_0002/ Kill Command = /home/hadoop/bin/hadoop job -kill job_1391362544864_0002 Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1 2014-02-02 17:46:18,013 Stage-1 map = 0%, reduce = 0% 2014-02-02 17:46:29,536 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.92 sec 2014-02-02 17:46:30,585 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.92 sec 2014-02-02 17:46:31,646 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.92 sec 2014-02-02 17:46:32,707 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.92 sec 2014-02-02 17:46:33,773 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.92 sec 2014-02-02 17:46:34,822 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.92 sec 2014-02-02 17:46:35,872 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.92 sec 2014-02-02 17:46:36,925 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.92 sec 2014-02-02 17:46:37,975 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.85 sec 2014-02-02 17:46:39,034 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.85 sec 2014-02-02 17:46:40,083 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.85 sec MapReduce Total cumulative CPU time: 6 seconds 850 msec Ended Job = job_1391362544864_0002 Counters: MapReduce Jobs Launched: Job 0: Map: 2 Reduce: 1 Cumulative CPU: 6.85 sec HDFS Read: 58636 HDFS Write: 34 SUCCESS Total MapReduce CPU Time Spent: 6 seconds 850 msec OK 2014-01-30 16 95 2014-01-30 17 33 Time taken: 40.334 seconds, Fetched: 2 row(s)
40秒も掛かりました。いかにImpalaが速いかがわかります。
8億レコードでやってみた
上と全く同じ内容のクエリを使って、8億レコードのCloudFrontログ解析をImpala上で実行してみました。
データコピー(S3→HDFS)
$ . /home/hadoop/impala/conf/impala.conf $ $ hadoop jar /home/hadoop/share/hadoop/common/lib/EmrS3DistCp-1.0.jar -Dmapreduce.job.reduces=30 --src s3://cloudfront-big-log/logs/cf/ --dest hdfs://$HADOOP_NAMENODE_HOST:$HADOOP_NAMENODE_PORT/input/ --outputCodec 'none' 14/02/03 05:21:10 INFO s3distcp.S3DistCp: Running with args: -Dmapreduce.job.reduces=30 --src s3://cloudfront-big-log/logs/cf/ --dest hdfs://172.31.0.95:9000/input/ --outputCodec none 14/02/03 05:21:10 INFO s3distcp.S3DistCp: S3DistCp args: --src s3://cloudfront-big-log/logs/cf/ --dest hdfs://172.31.0.95:9000/input/ --outputCodec none 14/02/03 05:21:14 INFO s3distcp.S3DistCp: Using output path 'hdfs:/tmp/9dc925c6-0f4e-4043-a19a-f21930f89b6b/output' 14/02/03 05:21:15 INFO s3distcp.S3DistCp: GET http://169.254.169.254/latest/meta-data/placement/availability-zone result: ap-northeast-1a 14/02/03 05:21:15 INFO s3distcp.S3DistCp: Created AmazonS3Client with conf KeyId XXXXXXXXXXXXXXXXXXXXXXXX 14/02/03 05:21:16 INFO s3distcp.S3DistCp: Skipping key 'logs/cf/' because it ends with '/' 14/02/03 05:21:16 INFO s3distcp.FileInfoListing: Opening new file: hdfs:/tmp/9dc925c6-0f4e-4043-a19a-f21930f89b6b/files/1 14/02/03 05:21:57 INFO s3distcp.S3DistCp: Created 1 files to copy 211761 files 14/02/03 05:21:57 INFO s3distcp.S3DistCp: Reducer number: 29 〜(中略)〜 CPU time spent (ms)=16164160 Physical memory (bytes) snapshot=18180935680 Virtual memory (bytes) snapshot=53996851200 Total committed heap usage (bytes)=14206107648 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=39560891 File Output Format Counters Bytes Written=0 14/02/03 06:30:50 INFO s3distcp.S3DistCp: Try to recursively delete hdfs:/tmp/9dc925c6-0f4e-4043-a19a-f21930f89b6b/tempspace
入力テーブル作成(input)
$ impala-shell > > CREATE EXTERNAL TABLE IF NOT EXISTS input ( > cf_date STRING, > cf_time STRING, > x_edge_location STRING, > sc_bytes INT, > c_ip STRING, > cs_method STRING, > cs_host STRING, > cs_uri_stem STRING, > sc_status STRING, > cs_referrer STRING, > cs_user_agent STRING, > cs_uri_query STRING, > cs_cookie STRING, > x_edge_result_type STRING, > x_edge_request_id STRING, > x_host_header STRING, > cs_protocol STRING, > cs_bytes INT > ) > ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' > LOCATION '/input/'; Query: create EXTERNAL TABLE IF NOT EXISTS input ( cf_date STRING, cf_time STRING, x_edge_location STRING, sc_bytes INT, c_ip STRING, cs_method STRING, cs_host STRING, cs_uri_stem STRING, sc_status STRING, cs_referrer STRING, cs_user_agent STRING, cs_uri_query STRING, cs_cookie STRING, x_edge_result_type STRING, x_edge_request_id STRING, x_host_header STRING, cs_protocol STRING, cs_bytes INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/input/'</p> <p>Returned 0 row(s) in 266.06s
入力件数
> select count(<em>) from input; Query: select count(</em>) from input</p> <p>+-----------+ | count(*) | +-----------+ | 820545673 | +-----------+</p> <p>Returned 1 row(s) in 642.03s
出力テーブル作成(output)
> CREATE EXTERNAL TABLE IF NOT EXISTS output_pv ( > dth STRING, > cnt BIGINT > ) > ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' > LOCATION '/output_pv/'; Query: create EXTERNAL TABLE IF NOT EXISTS output_pv ( dth STRING, cnt BIGINT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/output_pv/'</p> <p>Returned 0 row(s) in 2.23s
解析(input→output)
> insert into output > select w.jsttime, count(mydata) from > (select substr(cast(from_utc_timestamp(from_unixtime(unix_timestamp(concat(cf_date, " ", cf_time), 'yyyy-MM-dd HH:mm:ss')), 'JST') as STRING), 1, 13) as jsttime, 'AAA' as mydata from input where cf_date not like '#%') w > group by w.jsttime > ; Query: insert into output select w.jsttime, count(mydata) from (select substr(cast(from_utc_timestamp(from_unixtime(unix_timestamp(concat(cf_date, " ", cf_time), 'yyyy-MM-dd HH:mm:ss')), 'JST') as STRING), 1, 13) as jsttime, 'AAA' as mydata from input where cf_date not like '#%') w group by w.jsttime</p> <p>Inserted 759 rows in 14940.46s
結果
| 内容 | 所用時間 |
|---|---|
| データのコピー(S3→HDFS) | 約1時間 |
| テーブル作成(input) | 約4分 |
| テーブル作成(output) | 約2秒 |
| 解析(input→output) | 約4時間 |
想像していたより全然速いです。
ちなみに、特定のURIに絞ってクエリを実行したら15分ほどで終わってしまいました。
> insert into output_pv > select w.jsttime, count(mydata) from > (select substr(cast(from_utc_timestamp(from_unixtime(unix_timestamp(concat(cf_date, " ", cf_time), 'yyyy-MM-dd HH:mm:ss')), 'JST') as STRING), 1, 13) as jsttime, 'AAA' as mydata from input where cf_date not like '#%' and (cs_uri_stem = '/' or cs_uri_stem = '/index.html')) w > group by w.jsttime > ; Query: insert into output_pv select w.jsttime, count(mydata) from (select substr(cast(from_utc_timestamp(from_unixtime(unix_timestamp(concat(cf_date, " ", cf_time), 'yyyy-MM-dd HH:mm:ss')), 'JST') as STRING), 1, 13) as jsttime, 'AAA' as mydata from input where cf_date not like '#%' and (cs_uri_stem = '/' or cs_uri_stem = '/index.html')) w group by w.jsttime</p> <p>Inserted 755 rows in 852.34s
今回はHiveで8億レコードは試せませんでしたが、いままでHiveを使用していた感覚からするとImpalaは異常なほどの速さです。
これからEMRでクエリを使用する場合はImpala一択になりそうです。
以上です。


