
すいません、Lambda ではありません。
ども、mod_mruby ngx_mruby Advent Calendar 2014 5 日目、初心者枠の cloudpack の かっぱ (@inokara) です。
はじめ
前回の「ラズパイで mruby から Amazon S3 に mruby-aws-s3 使ってデータをアップしたりしてみる」では mruby-aws-s3 という mrbgems を触ってみた話を書きましたが、今回は mruby-aws-s3 と mod_mruby で Amazon S3 上の HTML ファイルを表示させて遊んでみたいと思います。
遊んでみるとは言え、何かメリットが無いか考えてみましたが、ラズパイのような容量が小さい端末でコンテンツをローカルに保存することなく効率よく表示させたい場合にちょっと使えるかもしれないなあって思ってまいます…。(強引ですが)
こんな感じで…
ざっくりやりたいことイメージ
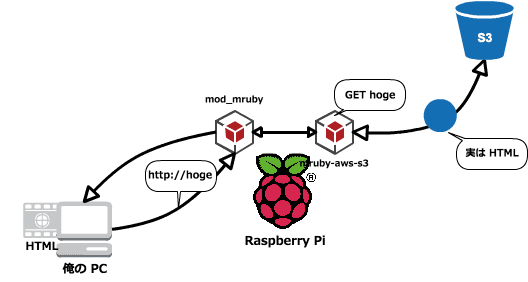
HTML は以下のように…
test hello Amazon S3
このファイルを Amazon S3 の適当なバケットにアップロードします。尚、S3 のバケットの設定は特に特別な設定を行っていません。(ウェブホスティング機能やバケットポリシー等の設定は行っていません。)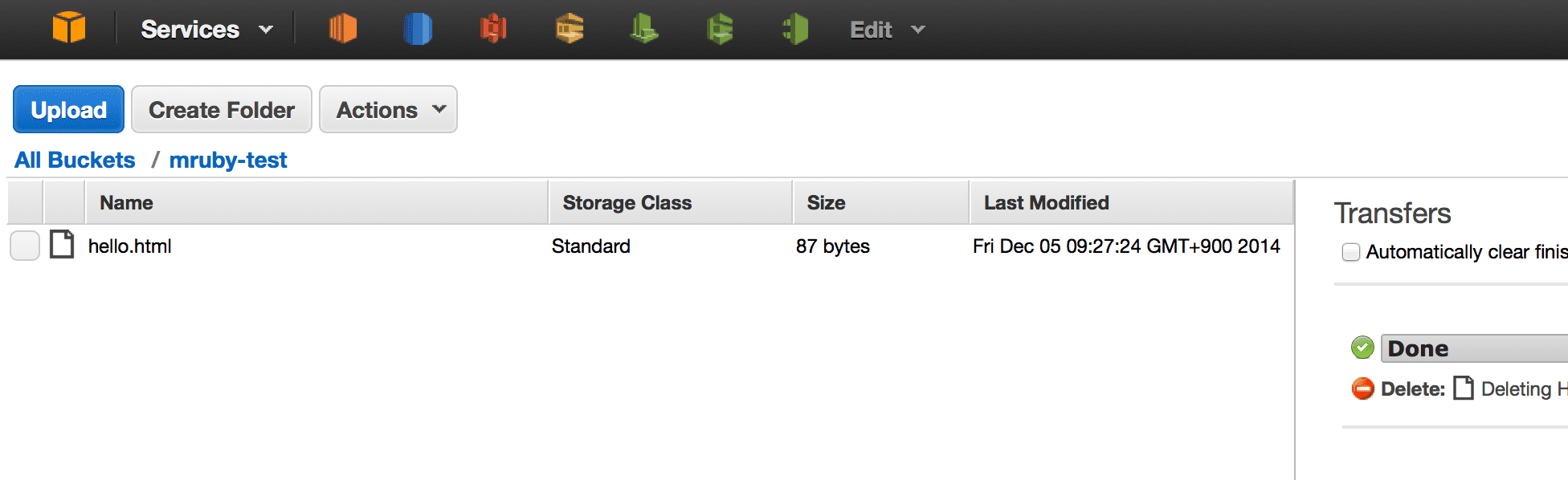
hook スクリプトは以下のように…
AWSAccessKeyId = 'YOUR_KEY'
AWSSecretAccessKey = 'YOUR_SECRET_KEY'
AWSBucket = "mruby-test"
aws = AWS::S3.new(AWSAccessKeyId, AWSSecretAccessKey)
aws.set_bucket(AWSBucket)
response = aws.download("/hello.html")
if response.code.to_i == 200
Apache.echo response.body
else
Apache.echo "Error code = " + response.code.to_s
Apache.echo "Response:"
Apache.echo response.body
end
/mruby にアクセスが発生したら S3 から任意の HTML ファイルオブジェクトをダウンロードして Apache.echo メソッドで response.body を表示しています。もし、ファイルが存在していない場合等は 404 エラー等が返るようになっています。
mod_mruby の設定
以下のように mrubyHandlerMiddle で mruby スクリプトを呼び出します。cache オプションを付加することで Apache の再起動時にスクリプトをコンパイルしてキャッシュします。
mrubyHandlerMiddle /etc/apache2/hooks/test.rb cache
試してみる
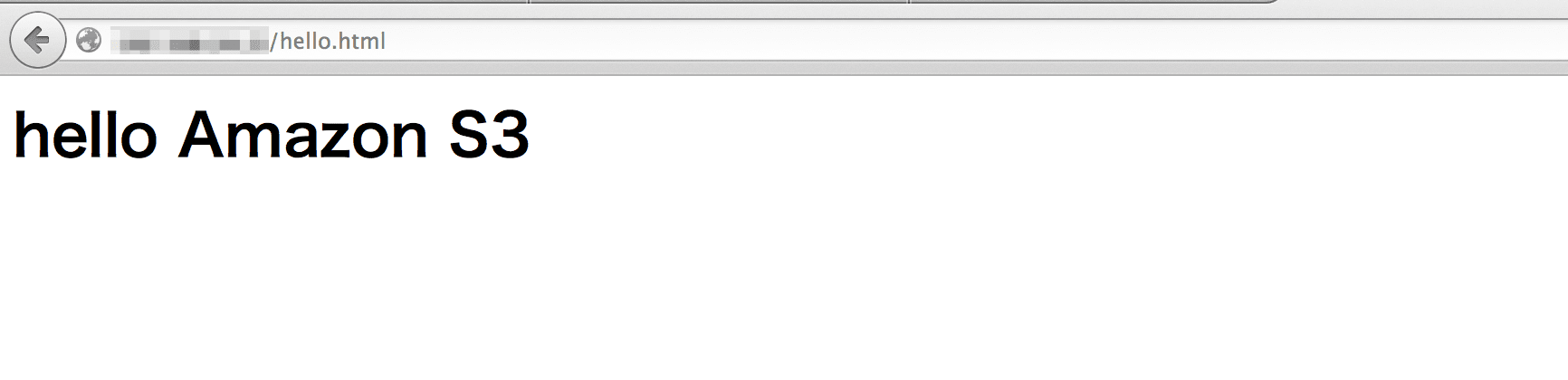
おお、ちゃんと表示されましたよ!
それなら…
異なる HTML ドキュメントを表示してみたいと思います。
HTML は以下のように
hoge ほげ
fuga ふが
hook スクリプトは以下のように…
AWSAccessKeyId = 'YOUR_KEY'
AWSSecretAccessKey = 'YOUR_SECRET_KEY'
AWSBucket = "mruby-test"
aws = AWS::S3.new(AWSAccessKeyId, AWSSecretAccessKey)
aws.set_bucket(AWSBucket)
r = Apache::Request.new()
response = aws.download("#{r.uri}.html")
if response.code.to_i == 200
Apache.echo response.body
else
Apache.echo "Error code = " + response.code.to_s
Apache.echo "Response:"
Apache.echo response.body
end
log = Fluent::Logger.new(nil, :host=>'127.0.0.1', :port=>'8888')
c = Apache::Connection.new()
log.post('test.hoge', {"remote_ip"=>"#{c.remote_ip}", "local_ip"=>"#{c.local_ip}", "keepalives"=>"#{c.keepalives.to_s}", "request_uri"=>"#{r.uri}", "resoinse_code"=>"#{response.code}"})
mod_mruby を利用することで、リクエストヘッダから Apache::Request クラスからオブジェクトを生成して uri メソッドで URI を取得して S3 からダウンロードするファイルを取得しています。もし、ファイルが存在していない場合等は 404 エラー等が返るようになっています。
更に fluent-logger-mruby でリクエスト URI とレスポンスコードと接続元の IP 等を取得するようにしています。
mod_mruby の設定
mrubyHandlerMiddle /etc/apache2/hooks/test.rb cache
試してみる
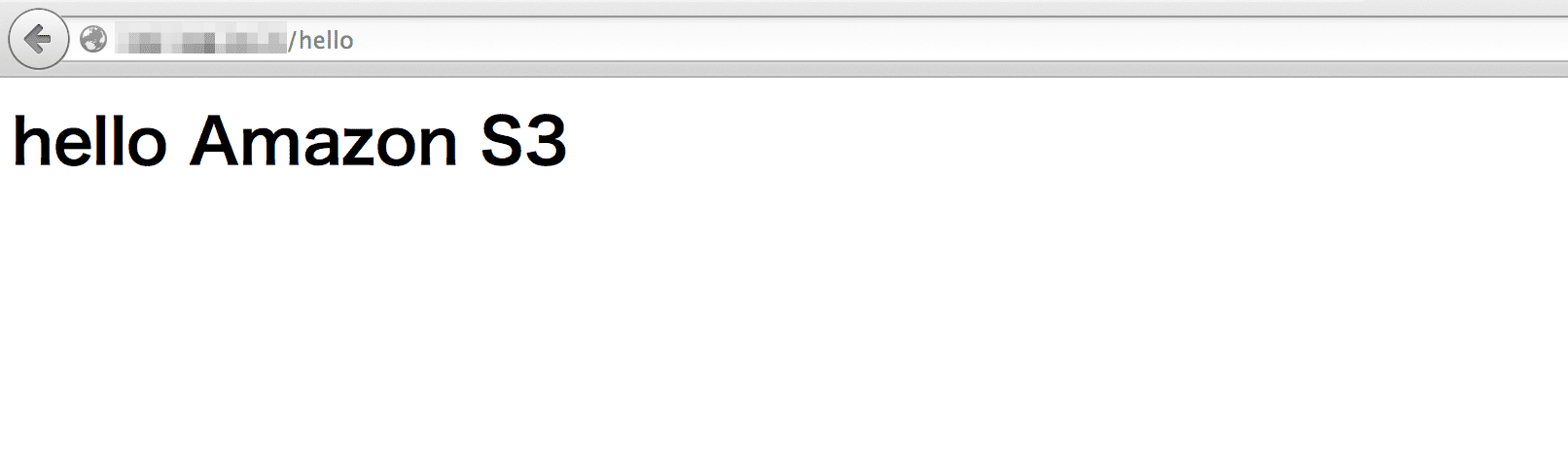
おお。
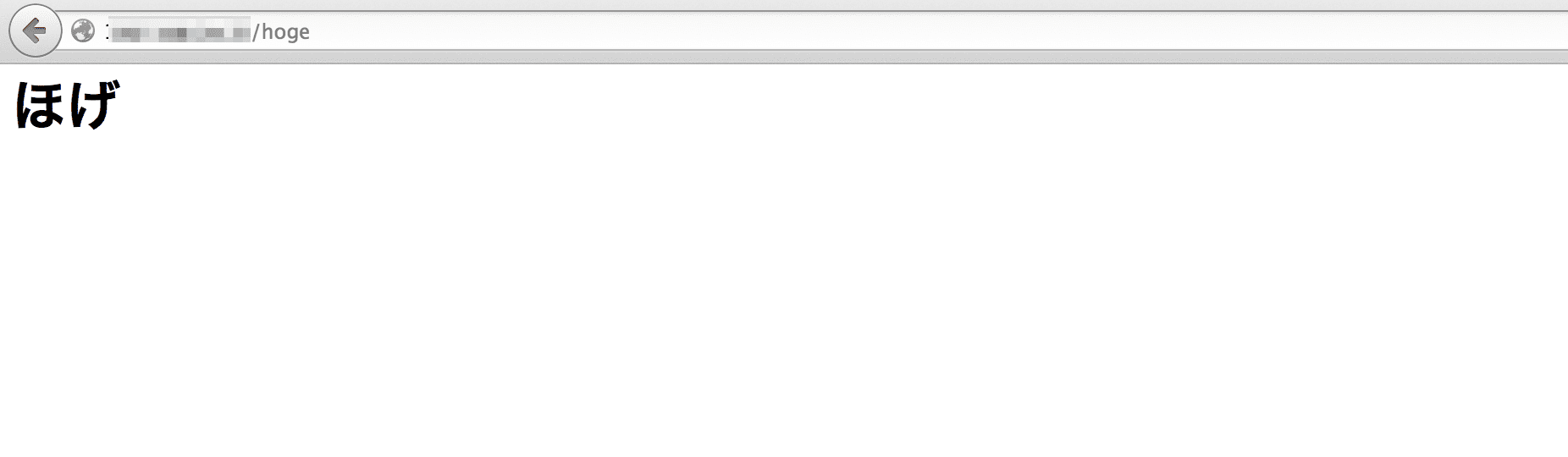
ほげ。
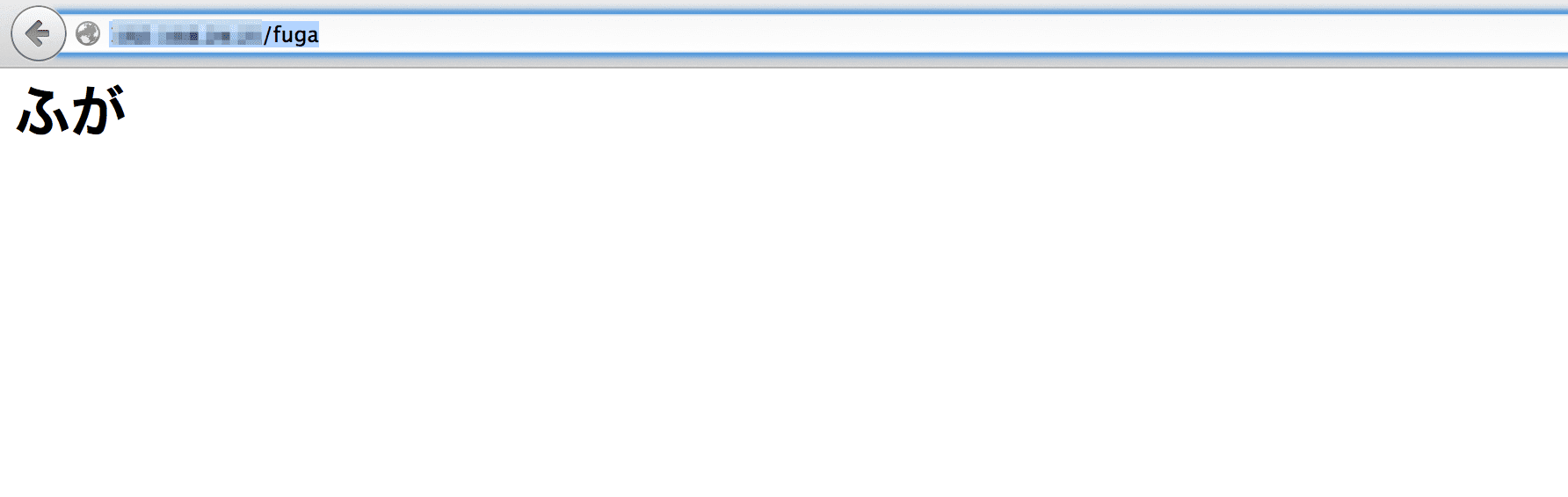
ふが。
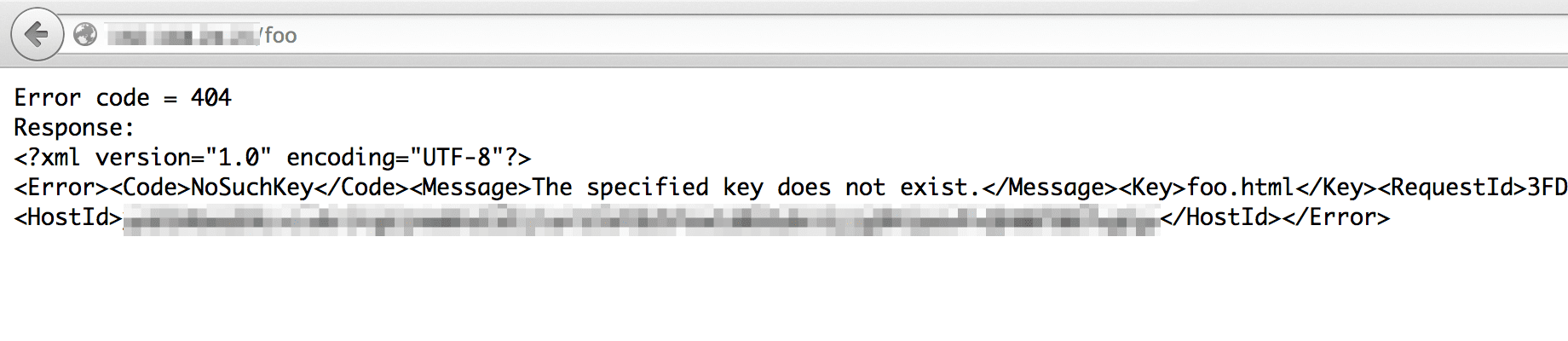
存在しない URI を叩くと上記のようにそれっぽい 404 エラーが出てくれます。(S3 が出力してくれています。これは S3 へのアクセスのレスポンスボディをそのまま表示しているからですね。)
これらのアクセスの際の fluent-logger-s3 のログは以下のようなログとなります。
2014-12-05 22:07:22 +0900 test.hoge: {"resoinse_code":"200","request_uri":"/hello","keepalives":"1","local_ip":"192.168.xx.x1","remote_ip":"192.168.xx.100"}
2014-12-05 22:08:33 +0900 test.hoge: {"resoinse_code":"200","request_uri":"/hoge","keepalives":"0","local_ip":"192.168.xx.x1","remote_ip":"192.168.xx.100"}
2014-12-05 22:09:39 +0900 test.hoge: {"resoinse_code":"200","request_uri":"/fuga","keepalives":"0","local_ip":"192.168.xx.x1","remote_ip":"192.168.xx.100"}
2014-12-05 22:11:31 +0900 test.hoge: {"resoinse_code":"404","request_uri":"/foo","keepalives":"0","local_ip":"192.168.xx.x1","remote_ip":"192.168.xx.100"}
mod_mruby の各クラスから生成した任意のメソッドの値が記録されていますね。もちろん、Apache のアクセスログでも同様の値はとれたりしますが、より詳細な情報が手軽に取得出来て fluentd で処理することが出来そうですね。
あと…
S3 からコンテンツを取得する download メソッドの引数をオブジェクトファイルではなくて / を指定すると面白いことが置きました。
aws = AWS::S3.new(AWSAccessKeyId, AWSSecretAccessKey)
aws.set_bucket(AWSBucket)
response = aws.download("/")
以下のようにバケットの一覧が XML で取得出来ました。
mruby-test 1000 false Hello.txt 2014-12-05T16:49:32.000Z "1a392270c92611dc909f90cc8071e7e6" 37 4dfxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx484bf 4dfxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx484bf kawahara STANDARD
ああ、mruby で XML パーサーがあれば mruby と mod_mruby で簡易的なバケット一覧やバケットコンソールも作れそうな気がしてきました…。
さいごに
たまたま見つけた mruby-aws-s3 と Amazon S3 と mod_mruby を利用してHTML ビューワー的に遊んでみました。たまたまラズパイで弄っていましたが、ローカルにコンテンツを置く必要がないのでストレージの節約になりますし、画像データ等が扱えるようになれば画像ビューワー的なものが簡単に作れそうな気がします。
ということで、
明日は rrreeeyyy さんの番ですよー。宜しくお願い致します。(※Advent Calendar の次の番へバトンタッチです)
元記事はこちらです。
「mod_mruby と mruby-aws-s3 を使って S3 上の HTML をコンテンツを表示させてみよう」
