
マルチモーダルプロンプトとは
テキスト、画像、動画など複数の情報源から情報を組み合わせたプロンプトです。
Pythonでテキストと画像のプロンプトをGeminiに送信する、簡単なサンプルを見つけたので自分なりに理解するために編集したものを記載しようと思います。
目次
- 元ネタの紹介
- Jupyter Notebook ファイルと画像
- 実行環境
- Jupyter Notebook 上でライブラリインストール等初期設定
- テキストと画像のマルチモーダルプロンプトをGeminiへ送信
- 複数のテキストと複数の画像のマルチモーダルプロンプト
元ネタの紹介
Google Cloud の オンラインLab の講座を元ネタにしています。
LabのJupyter Notebook ファイルは、Githubで公開されています。
Jupyter Notebook ファイルと画像
元ネタのJupyter Notebook ファイルを編集した、今回紹介するJupyter Notebook ファイルと画像です。
Jupyter Notebook ファイル 「multimodal_tutorial.ipynb」
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "QDU0XJ1xRDlL"
},
"source": [
"## 初期設定\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "N5afkyDMSBW5"
},
"source": [
"### Vertex AI SDK for Python インストール\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "kc4WxYmLSBW5",
"tags": []
},
"outputs": [],
"source": [
"! pip3 install --upgrade --user google-cloud-aiplatform"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "R5Xep4W9lq-Z"
},
"source": [
"### カーネル再起動\n",
"\n",
"インストールしたパッケージを適用するためにカーネル再起動します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "XRvKdaPDTznN",
"tags": []
},
"outputs": [],
"source": [
"import IPython\n",
"\n",
"app = IPython.Application.instance()\n",
"app.kernel.do_shutdown(True)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SbmM4z7FOBpM"
},
"source": [
"<div class=\"alert alert-block alert-warning\">\n",
"<b>⚠️ カーネルが再起動されます。ステータスが完了するまでお待ちください。 ⚠️</b>\n",
"</div>\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "QGB8Txa_e4V0"
},
"source": [
"### Vertex AI 初期化\n",
"\n",
"プロジェクトID、使用リージョンを設定して、Vertex AIを初期化します。 \n",
"PROJECT_ID、LOCATIONは、起動している Vertex AI Workbench の Jupyter ノートブックの PROJECT_ID、LOCATION を設定します。"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"id": "JGOJHtgDe5-r",
"tags": []
},
"outputs": [],
"source": [
"PROJECT_ID = \"プロジェクトIDを設定\" # @param {type:\"string\"}\n",
"LOCATION = \"us-central1\" # @param {type:\"string\"}\n",
"\n",
"import vertexai\n",
"\n",
"vertexai.init(project=PROJECT_ID, location=LOCATION)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "BuQwwRiniVFG"
},
"source": [
"### ライブラリインポート\n"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"id": "JTk488WDPBtQ",
"tags": []
},
"outputs": [],
"source": [
"from vertexai.generative_models import GenerationConfig, GenerativeModel, Image, Part"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "eTNnM-lqfQRo"
},
"source": [
"### Gemini 1.5 Flash model 使用定義\n"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"id": "2998506fe6d1",
"tags": []
},
"outputs": [],
"source": [
"multimodal_model = GenerativeModel(\"gemini-1.5-flash\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "MpL3OkSCfIAR"
},
"source": [
"### ヘルパー関数を定義\n"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"id": "S7QMAHXse339",
"tags": []
},
"outputs": [],
"source": [
"import http.client\n",
"import typing\n",
"import urllib.request\n",
"\n",
"import IPython.display\n",
"from PIL import Image as PIL_Image\n",
"from PIL import ImageOps as PIL_ImageOps\n",
"\n",
"\n",
"def display_images(\n",
" images: typing.Iterable[Image],\n",
" max_width: int = 600,\n",
" max_height: int = 350,\n",
") -> None:\n",
" \"\"\"\n",
" ノートブック上に画像を表示\n",
" \"\"\"\n",
" for image in images:\n",
" pil_image = typing.cast(PIL_Image.Image, image._pil_image)\n",
" if pil_image.mode != \"RGB\":\n",
" # RGB is supported by all Jupyter environments (e.g. RGBA is not yet)\n",
" pil_image = pil_image.convert(\"RGB\")\n",
" image_width, image_height = pil_image.size\n",
" if max_width < image_width or max_height < image_height:\n",
" # Resize to display a smaller notebook image\n",
" pil_image = PIL_ImageOps.contain(pil_image, (max_width, max_height))\n",
" IPython.display.display(pil_image)\n",
"\n",
"def load_image_from_local(path: str) -> Image:\n",
" \"\"\"\n",
" ローカルの画像をPIL.Imageで取得\n",
" \"\"\"\n",
" with open(path, 'rb') as file:\n",
" image_bytes = file.read()\n",
" return Image.from_bytes(image_bytes)\n",
"\n",
"def display_content_as_image(content: str | Image | Part) -> bool:\n",
" \"\"\"\n",
" PIL.Imageの場合はノートブック上に画像を表示\n",
" \"\"\"\n",
" if not isinstance(content, Image):\n",
" return False\n",
" display_images([content])\n",
" return True\n",
"\n",
"\n",
"def print_multimodal_prompt(contents: list[str | Image | Part]):\n",
" \"\"\"\n",
" プロンプトの内容を表示\n",
" \"\"\"\n",
" for content in contents:\n",
" if display_content_as_image(content):\n",
" continue\n",
" print(content)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5OWurhO4mu4J"
},
"source": [
"## マルチモーダルプロンプトの動作確認\n",
"\n",
"1つのテキスト(指示内容)と1の画像をプロンプトで指定して、Geminiの推論結果を受け取りノートブック上に結果を表示します。\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "UyRoVquPmy9H",
"tags": []
},
"outputs": [],
"source": [
"# 猫の画像を読み込み\n",
"image_cat_url = \"run_cat_smile.png\"\n",
"image_cat = load_image_from_local(image_cat_url)\n",
"\n",
"prompt = \"この画像に表示されている動物の種類を教えてください。\"\n",
"\n",
"contents = [\n",
" prompt,\n",
" image_cat,\n",
"]\n",
"\n",
"# Geminiへプロンプト送信し結果を取得\n",
"responses = multimodal_model.generate_content(contents, stream=True)\n",
"\n",
"print(\"-------Prompt--------\")\n",
"print_multimodal_prompt(contents)\n",
"\n",
"print(\"\\n-------Response--------\")\n",
"for response in responses:\n",
" print(response.text, end=\"\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "zy-me3PdgMUH"
},
"source": [
"## 複数テキスト、複数画像をプロンプトに指定\n",
"\n",
"果物の画像と価格表を画像から、果物の合計価格をGeminiに判定させ、ノートブック上に結果を表示します。\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "yDjN4thV8orx",
"tags": []
},
"outputs": [],
"source": [
"image_fruit_url = \"apple_banana.png\"\n",
"image_fruit = load_image_from_local(image_fruit_url)\n",
"\n",
"image_price_url = \"price_list.png\"\n",
"image_price = load_image_from_local(image_price_url)\n",
"\n",
"instructions = \"価格表の画像と、複数の果物の画像を入力として、質問に回答してください。\"\n",
"prompt1 = \"\"\"\n",
"果物の画像:\n",
"\"\"\"\n",
"prompt2 = \"\"\"\n",
"価格表の画像:\n",
"\"\"\"\n",
"prompt3 = \"\"\"\n",
"- 質問1:果物の画像には表示されている果物の種類を教えてください。\n",
"- 質問2:各果物の数量を教えてください。\n",
"- 質問3:各果物の価格の小計を教えてください。\n",
"- 質問4:小計から合計価格を教えてください。\n",
"\"\"\"\n",
"\n",
"contents = [\n",
" instructions,\n",
" prompt1,\n",
" image_fruit,\n",
" prompt2,\n",
" image_price,\n",
" prompt3\n",
"]\n",
"\n",
"# Geminiへプロンプト送信し結果を取得\n",
"responses = multimodal_model.generate_content(contents, stream=True)\n",
"\n",
"print(\"-------Prompt--------\")\n",
"print_multimodal_prompt(contents)\n",
"\n",
"print(\"\\n-------Response--------\")\n",
"for response in responses:\n",
" print(response.text, end=\"\")"
]
}
],
"metadata": {
"colab": {
"name": "intro_multimodal_use_cases.ipynb",
"toc_visible": true
},
"environment": {
"kernel": "conda-base-py",
"name": "workbench-notebooks.m125",
"type": "gcloud",
"uri": "us-docker.pkg.dev/deeplearning-platform-release/gcr.io/workbench-notebooks:m125"
},
"kernelspec": {
"display_name": "Python 3 (ipykernel) (Local)",
"language": "python",
"name": "conda-base-py"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.15"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
画像3枚
りんごとバナナの画像はChatGPTに指示して生成しました。


実行環境
お金が掛からない手段で Jupyter Notebook ファイルを実行するには、Google Cloud の オンラインLab の講座 を利用する手があります。
おすすめの Lab は、「Getting Started with the Vertex AI Gemini API and Python SDK」です。
Lab の手順に沿って、「タスク 1. Vertex AI Workbench でノートブックを開く」まで手順を実施し、ノートブック実行環境を起動します。
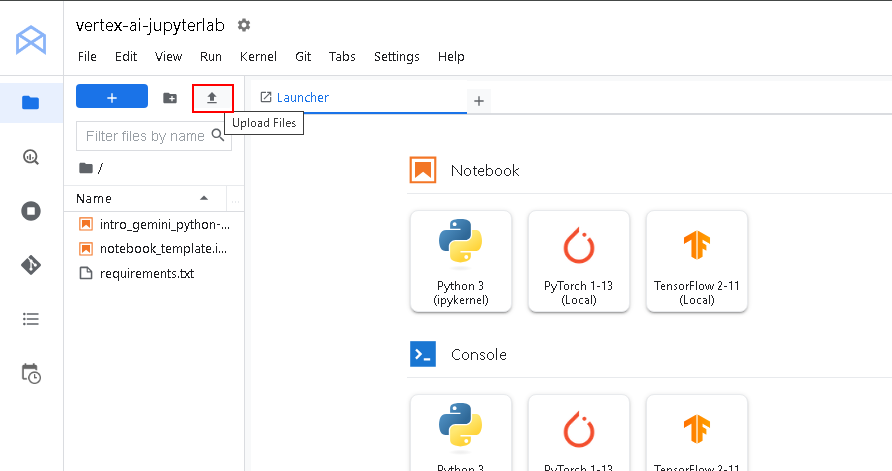
ノートブック実行環境を起動したら、Jupyter Notebook ファイルと画像をアップロードします。
アップロードは、下図の赤枠のアイコンをクリックするとファイルダイアログが表示されるので、アップロードするファイルを選択してアップロードします。
Jupyter Notebook 上でライブラリインストール等初期設定
ノートブック環境で、アップロードしたファイルの「multimodal_tutorial.ipynb」を開きます。
「マルチモーダルプロンプトの動作確認」の手前まで各セルを実行します。
・Vertex AI SDK for Python インストール
インストール完了することを確認してから次の手順を実施します。
! pip3 install --upgrade --user google-cloud-aiplatform
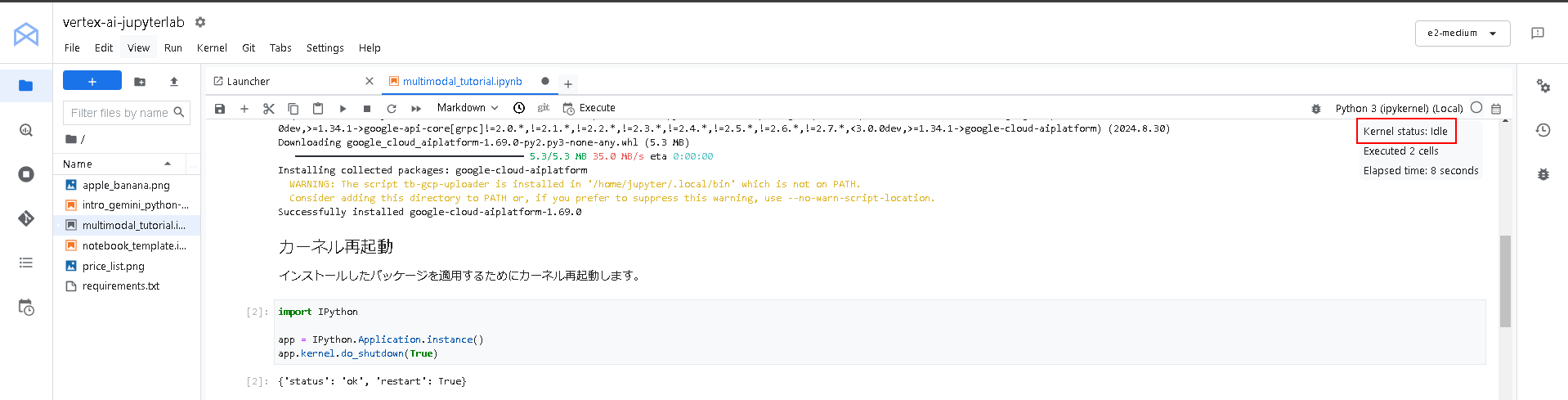
・カーネル再起動
import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True)
下図の様に 「Kernel status: idle」となること確認してから次の手順を実施します。
・Vertex AI 初期化
PROJECT_ID に Lab のプロジェクトIDを設定したからセル実行します。
LOCATIONは変更なしで良いです。
PROJECT_ID = "プロジェクトIDを設定" # @param {type:"string"}
LOCATION = "us-central1" # @param {type:"string"}
import vertexai
vertexai.init(project=PROJECT_ID, location=LOCATION)
プロジェクトIDはGoogle Cloud のプロジェクトIDを設定してください。
・ライブラリインポート、Gemini 1.5 Flash model 使用定義、ヘルパー関数を定義
それぞれのセルを実行します。
from vertexai.generative_models import GenerationConfig, GenerativeModel, Image, Part
multimodal_model = GenerativeModel("gemini-1.5-flash")
import http.client
import typing
import urllib.request
import IPython.display
from PIL import Image as PIL_Image
from PIL import ImageOps as PIL_ImageOps
def display_images(
images: typing.Iterable[Image],
max_width: int = 600,
max_height: int = 350,
) -> None:
"""
ノートブック上に画像を表示
"""
for image in images:
pil_image = typing.cast(PIL_Image.Image, image._pil_image)
if pil_image.mode != "RGB":
# RGB is supported by all Jupyter environments (e.g. RGBA is not yet)
pil_image = pil_image.convert("RGB")
image_width, image_height = pil_image.size
if max_width < image_width or max_height < image_height:
# Resize to display a smaller notebook image
pil_image = PIL_ImageOps.contain(pil_image, (max_width, max_height))
IPython.display.display(pil_image)
def load_image_from_local(path: str) -> Image:
"""
ローカルの画像をPIL.Imageで取得
"""
with open(path, 'rb') as file:
image_bytes = file.read()
return Image.from_bytes(image_bytes)
def display_content_as_image(content: str | Image | Part) -> bool:
"""
PIL.Imageの場合はノートブック上に画像を表示
"""
if not isinstance(content, Image):
return False
display_images([content])
return True
def print_multimodal_prompt(contents: list[str | Image | Part]):
"""
プロンプトの内容を表示
"""
for content in contents:
if display_content_as_image(content):
continue
print(content)
テキストと画像のマルチモーダルプロンプトをGeminiへ送信
・マルチモーダルプロンプトの動作確認
1つのテキスト(指示内容)と1の画像をプロンプトで指定して、Geminiの推論結果を受け取りノートブック上に結果を表示します。
猫の画像をプロンプトで指定して、Geminiに動物の種類を判定させます。
# 猫の画像を読み込み
image_cat_url = "run_cat_smile.png"
image_cat = load_image_from_local(image_cat_url)
prompt = "この画像に表示されている動物の種類を教えてください。"
contents = [
prompt,
image_cat,
]
# Geminiへプロンプト送信し結果を取得
responses = multimodal_model.generate_content(contents, stream=True)
print("-------Prompt--------")
print_multimodal_prompt(contents)
print("\n-------Response--------")
for response in responses:
print(response.text, end="")
・実行結果
猫と判定されています。

複数のテキストと複数の画像のマルチモーダルプロンプト
・複数テキスト、複数画像をプロンプトに指定
果物の画像と価格表を画像から、果物の合計価格をGeminiに判定させ、ノートブック上に結果を表示します。
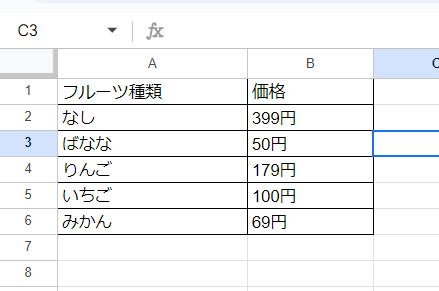
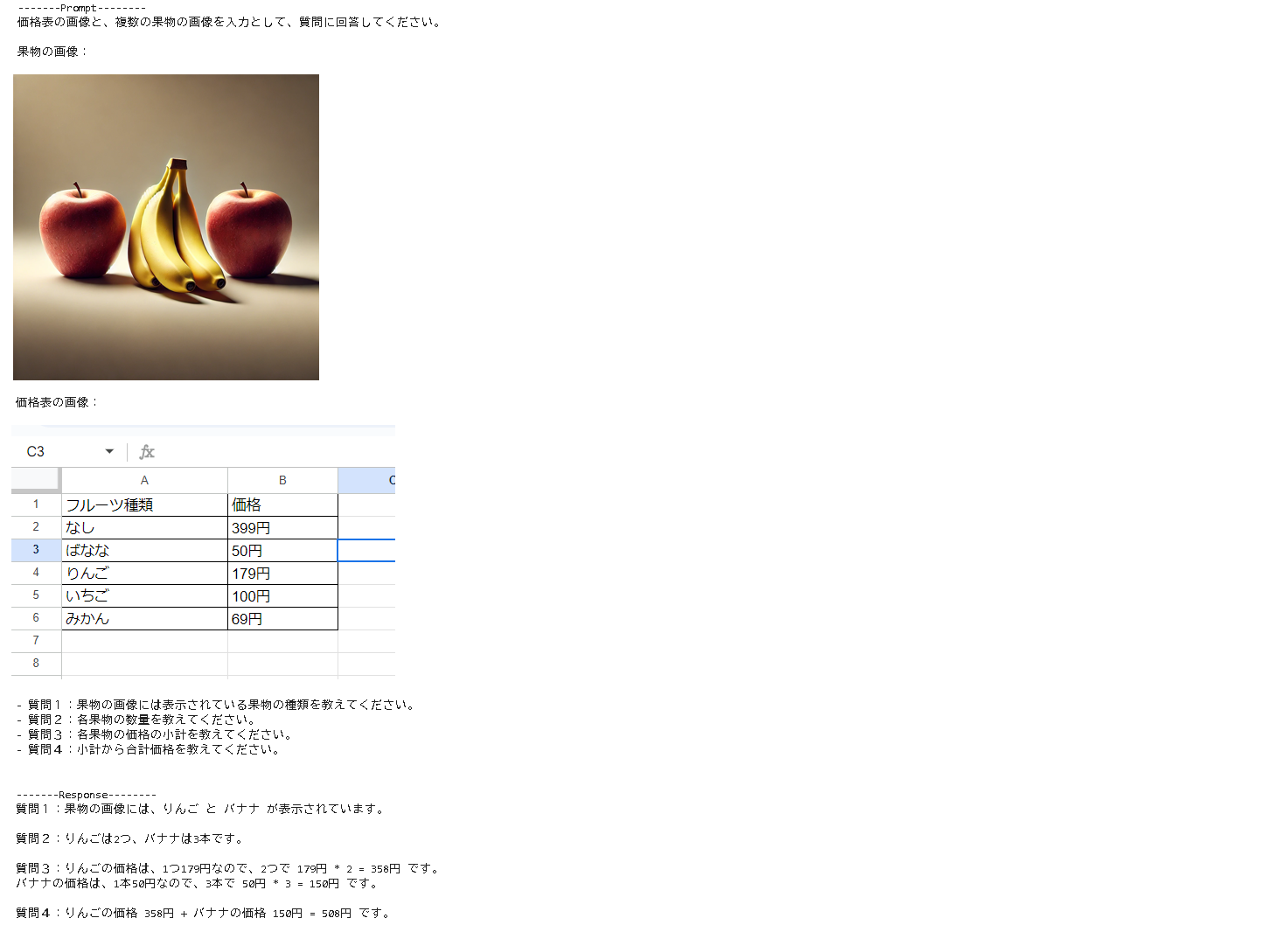
りんご2つ、バナナ3つの合計価格を価格表に基づいて計算して貰います。
また、果物の種類、数量、小計等、途中の経過も出力するようプロンプトで指示しています。
image_fruit_url = "apple_banana.png"
image_fruit = load_image_from_local(image_fruit_url)
image_price_url = "price_list.png"
image_price = load_image_from_local(image_price_url)
instructions = "価格表の画像と、複数の果物の画像を入力として、質問に回答してください。"
prompt1 = """
果物の画像:
"""
prompt2 = """
価格表の画像:
"""
prompt3 = """
- 質問1:果物の画像には表示されている果物の種類を教えてください。
- 質問2:各果物の数量を教えてください。
- 質問3:各果物の価格の小計を教えてください。
- 質問4:小計から合計価格を教えてください。
"""
contents = [
instructions,
prompt1,
image_fruit,
prompt2,
image_price,
prompt3
]
# Geminiへプロンプト送信し結果を取得
responses = multimodal_model.generate_content(contents, stream=True)
print("-------Prompt--------")
print_multimodal_prompt(contents)
print("\n-------Response--------")
for response in responses:
print(response.text, end="")
・実行結果
合計508円で期待通りです。小計も合っています。
まとめ
Pythonでテキストと画像のプロンプトをGeminiに送信するサンプルを実行してみました。
テキストと画像が混在した場合、どう指定するのか試すことができました。


