
第四開発事業部改め。
DX開発事業部モダンエンジニアリングセクションの西田です!
Dialogflow CXを使うとチャットボットエージェントをGUIで簡単に作成することができます。
ユーザーとチャットボットとのやり取りはログに出力することができ、そのログはBigQueryに簡単にエクスポートして分析にかけることができます。
この会話履歴ログをBigQuery MLでGeminiと組み合わせることで、問い合わせの感情分析に使えそうだと思ったので試してみました!
会話履歴ログをBigQueryにエクスポート
まずは分析にかけるログをエクスポートします。
マニュアル通りにやっていきます。
まずはあらかじめ出力対象のプロジェクトでデータセットとテーブルを作っておきます。
CREATE TABLE <your_dataset_name>.dialogflow_bigquery_export_data( project_id STRING, agent_id STRING, conversation_name STRING, turn_position INTEGER, request_time TIMESTAMP, language_code STRING, request JSON, response JSON, partial_responses JSON, derived_data JSON, conversation_signals JSON, bot_answer_feedback JSON );
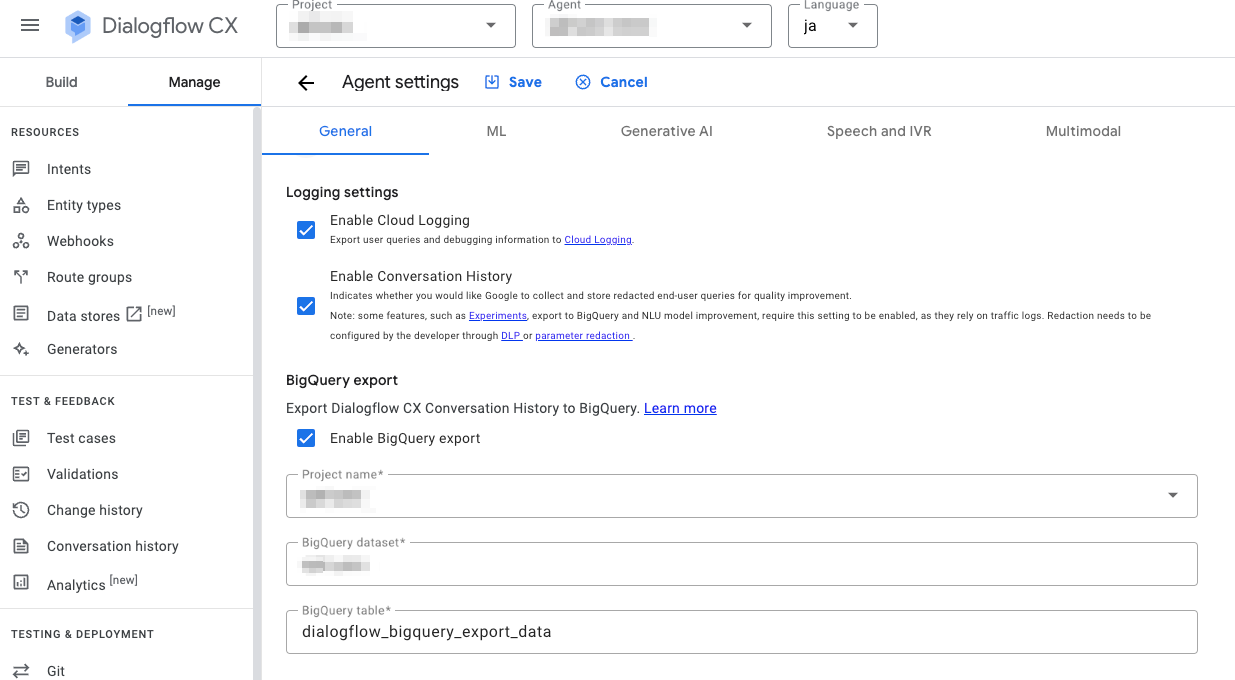
Dialogflow CXのエージェントのログ設定を有効化して、作ったテーブルを紐づけます。
このような設定方法なのでテーブルはエージェント毎にわけることも共通することも設計上できますね。
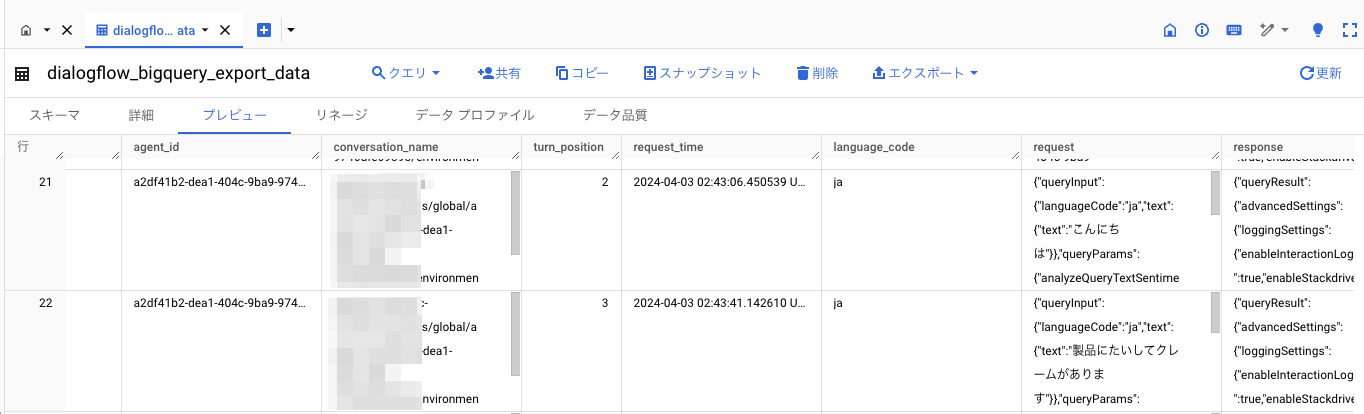
エージェントを動かしてこのようにログが流れてきたらまずは成功です🙌
BiqQuery MLでGeminiを使ってみる
マニュアルを参考にデータセットにモデルを作成します。
CREATE OR REPLACE MODEL `my-dataset.my_gemini` REMOTE WITH CONNECTION `asia-northeast1.my-connection` OPTIONS (ENDPOINT = 'gemini-pro');
単純なクエリを実行します。
promptの名前にした列がモデルに渡るようになっています。
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL my-dataset.my_gemini,
(
SELECT 'アイレット株式会社について教えて' AS prompt
),
STRUCT(
0.5 AS temperature,
1000 AS max_output_tokens,
TRUE AS flatten_json_output
)
);
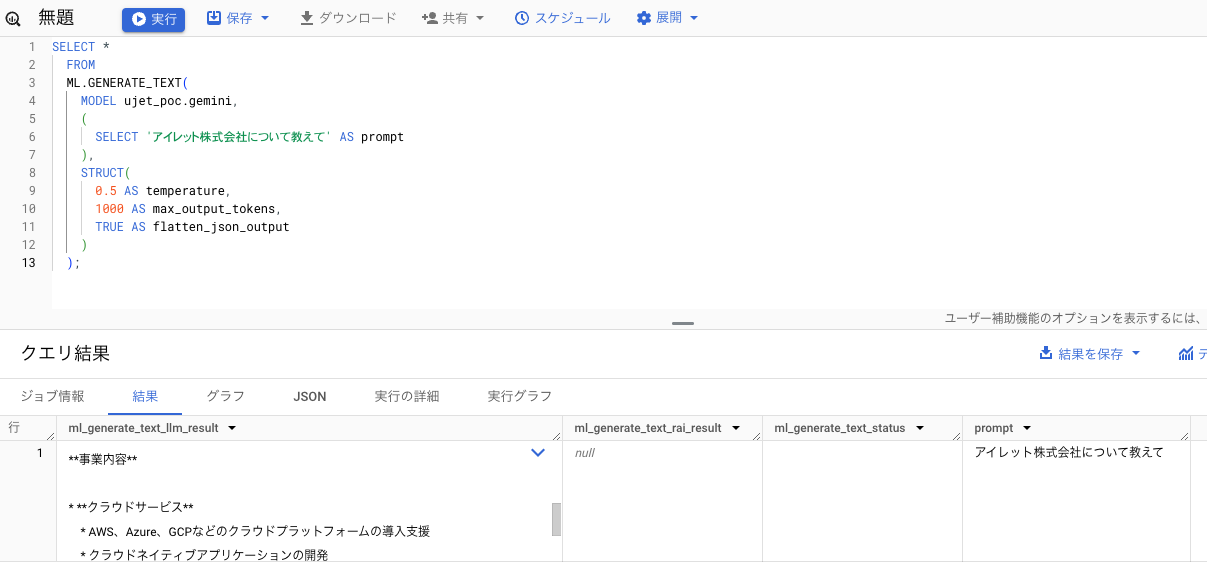
Geminiにプロンプトを渡して生成結果を得ることができました🙌
会話履歴ログをGeminiで感情分析してみる
いよいよ本題です。
このようなクエリにしてみました。
会話履歴ログの中身はJSONになっているので関数で取り出して渡しています。
SELECT
*
FROM
ML.GENERATE_TEXT(
MODEL my-dataset.my_gemini,
(
SELECT
CONCAT(
'この文章の感情を分析し、喜怒哀楽のどれか1文字で表現しなさい。該当するものがない場合は無としなさい:¥n',
STRING(JSON_EXTRACT(request, '$.queryInput.text.text'))
) AS prompt,
request,
STRING(JSON_EXTRACT(request, '$.queryInput.text.text')) AS user_request_message,
derived_data,
STRING(JSON_EXTRACT(derived_data, '$.agentUtterances')) AS agent_response_message,
request_time,
conversation_name,
turn_position
FROM
`my-dataset.dialogflow_bigquery_export_data`
WHERE
JSON_EXTRACT(request, '$.queryInput.text.text') IS NOT NULL
ORDER BY
request_time DESC,
turn_position DESC
LIMIT
100
), STRUCT(
0 AS temperature,
1000 AS max_output_tokens,
TRUE AS flatten_json_output
)
);
あまりいいデータが用意できませんでしたがプロンプト通り感情分析ができてそうです🙌
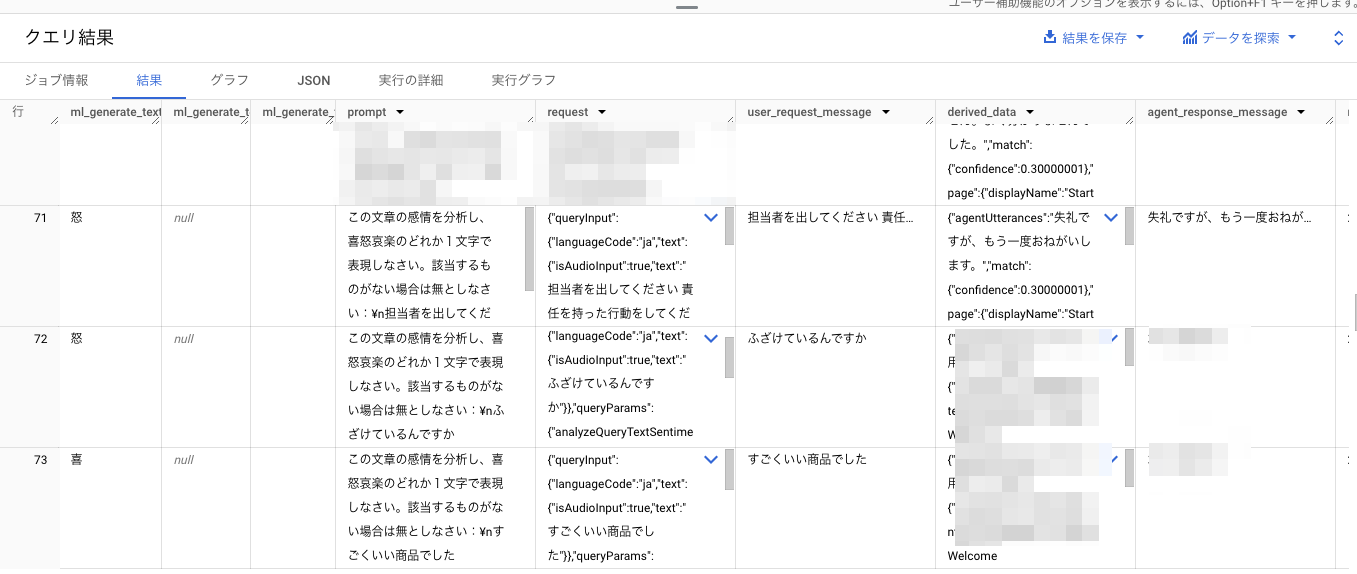
取り急ぎ結果は取れましたがレコード数が増えるとどんどんクエリが重くなるので、アドホックな分析には向かなそうです。
1ターンの会話が1レコードとして格納されているので、これをconversation_nameでまとめて、turn_positionで並べることで一連の会話として扱えます。
こうすれば会話の要約といったタスクにも使えそうですね。




