
はじめに
DX開発事業部の田村です。
この記事ではSlackから社内文書に存在する情報を質問すると、文書から検索して質問に対する回答を生成するチャットボットアプリの実装手順をまとめていきます。
留意点
アプリで使用するGoogle Cloud全般の知識や各種サービスの詳細な説明、プログラミングの基礎知識、その他ITの専門用語については取り扱いません。
また簡易的な実装になりますのでセキュリティや同時処理などは別途考慮が必要となります。
システム構成図
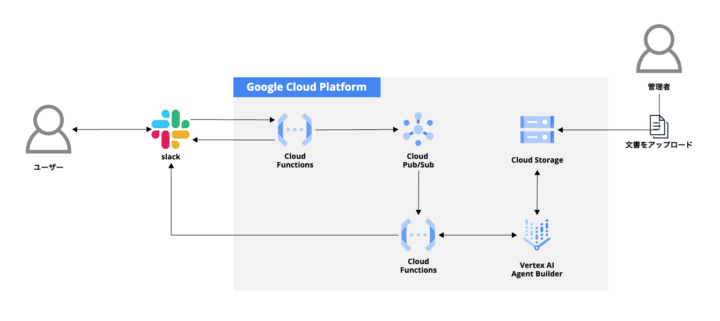
使用する技術
- Slack Bolt for Python
- Cloud Functions
- Cloud Pub/Sub
- Cloud Storage
- Vertex AI Agent Builder
処理の流れ
- Slackからメッセージを送信する
- 1つ目のCloud Fucntionsがリクエストを受け取り、Cloud Pub/Subにメッセージを発行した後に一旦Slackにレスポンスを返す
- Cloud Pub/Subへのメッセージ発行をトリガーとして2つ目のCloud Functionsを起動し、Vertex AI Agent BuilderでRAG検索を実行する
- Cloud FunctionsはRAG検索結果を受け取り、回答用に整形や要約をしてSlackにレスポンスを返す
実装の流れ
- Slackアプリの作成
- Google Cloudの各種リソース作成
- Agent Builderでサーチアプリとデータストアを作成
- Slackのメッセージ受信用の関数を作成
- 回答生成とメッセージ返信の関数を作成
- Event Subscriptionsの設定
- 動作確認
Slackアプリの作成
まずはSlack APIのサイトにアクセスしてアプリを作成していきます。(画面右上の「Your apps」)
スクラッチで作成することもできますが、今回はマニフェストから作成する方法で進めていきます。
「Create New App」で「From an app manifest」を選択し作成先のワークスペースを決めます。次の画面で以下のYAMLデータをコピペして作成します。
{
"display_information": {
"name": "RagChatBot"
},
"features": {
"bot_user": {
"display_name": "RagChatBot",
"always_online": false
}
},
"oauth_config": {
"scopes": {
"bot": [
"channels:history",
"chat:write",
"groups:history",
"incoming-webhook",
"app_mentions:read"
]
}
},
"settings": {
"org_deploy_enabled": false,
"socket_mode_enabled": false,
"token_rotation_enabled": false
}
}
作成が完了すると作成したSlackアプリのページに遷移しますので、まずはWorkspaceにインストールします。
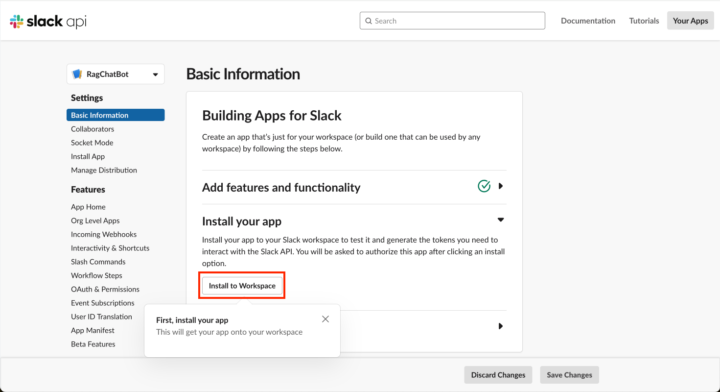
インストールが完了したら後のCloud Functionsで使う各種情報を取得します。
必要となる情報は以下の3種類です。
| 項目名 | 概要 |
| Signing Secret | Basic Information > App Credentialsから取得します。 |
| Bot User OAuth Token | OAuth & Permissions > OAuth Tokens for Your Workspaceから取得します。
xoxb-で始まる文字列 |
| Webhook URL | Incoming Webhooks > Webhook URLs for Your Workspace > Webhook URLから取得します。 |
Google Cloudの各種リソース作成
今回はCloud Shellというサービスを使い、コンソール上から必要なリソースをデプロイしていきます。
Cloud ShellはGoogle Cloudのコンソール画面右上にあるターミナルのアイコンから開くことが可能です。
クリックすると画面下部にターミナルの黒い画面が表示されます。
そしてターミナルのツールバー上にある「エディタを開く」ボタンを押下すると、Google Cloudのコンソール上で利用可能なVSCodeのような開発環境を起動することができます。
先にGCの各種リソースをデプロイした方が都合が良いため作成していきます。
GCの各種APIを有効化
gcloud services enable artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ eventarc.googleapis.com \ run.googleapis.com \ storage.googleapis.com \ aiplatform.googleapis.com
Cloud Pub/Subのトピックを作成
slack-rag-topicというトピック名で作成します。
gcloud pubsub topics create slack-rag-topic
Cloud Storageのバケットを作成
※エラーが発生する場合はgs://のあとのバケット名を任意の名称に変えて実行してください。
gcloud storage buckets create gs://slack-rag-bucket \ --default-storage-class=standard \ --location=asia-northeast1 \ --uniform-bucket-level-access
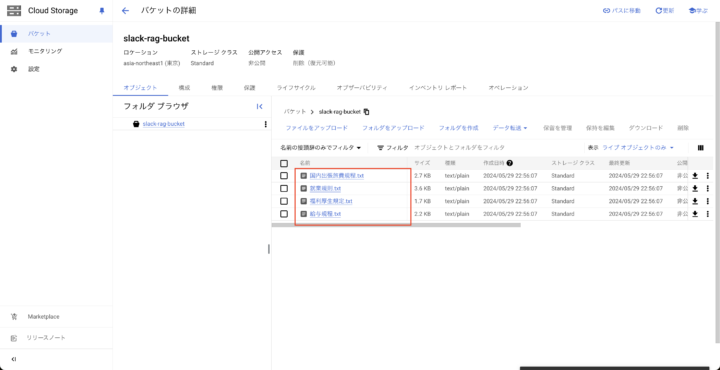
コンソールからRAG検索で使用するファイルをアップロードします。(gsutilコマンドでも勿論問題ありません)
検索バーで「Cloud Storage」を検索し、先ほど作成したバケットの画面からRAG検索させたい文書をアップロードします。
今回はGeminiアプリで生成AIに作ってもらった社内規定のサンプルをアップロードして使います。
Agent Builderでサーチアプリとデータストアを作成
コンソールの検索バーで「Agent Builder」を検索して画面を開きます。
「アプリを作成する」を押下し、以下の設定でアプリを設定していきます。(設定は基本的にデフォルトのままです)
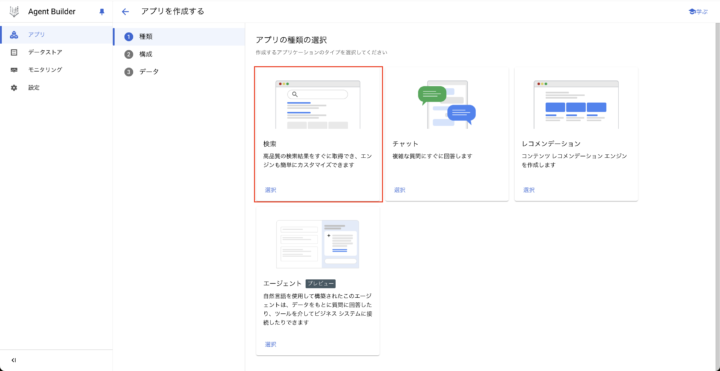
- 種類:
- アプリの種類:検索
- 構成
- アプリ名:
slack-rag-search-engine - 会社名:
slack-rag(任意の文字列)
- アプリ名:
- データ
- データストアを作成:Cloud Storageを選択し、インポートするCloud Storageのフォルダを選択します。
- データストア名:
slack-rag-datastore - 作成したデータストアを選択して「作成」を押下します。
5分~10分程でファイルがインポートされて利用可能になります。
インポートがされなかったり、失敗した場合はアクティビティ > データからをインポートを再実行してください。
- データソースを選択:Cloud Storage
- インポートするフォルダ:先ほど作成したCloud Storageのバケット名を指定します
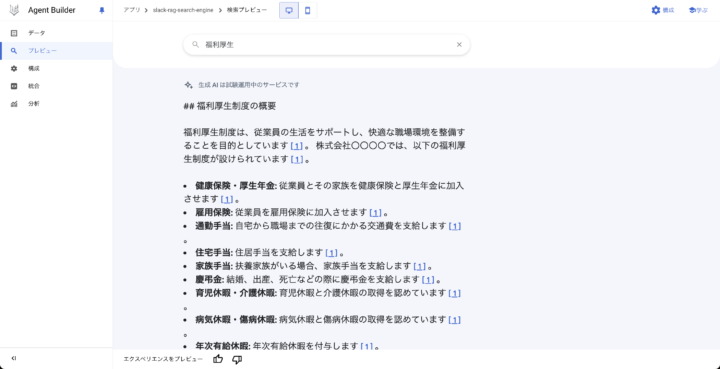
試しにプレビューから実行してみると、問題なく検索していることが確認できました。
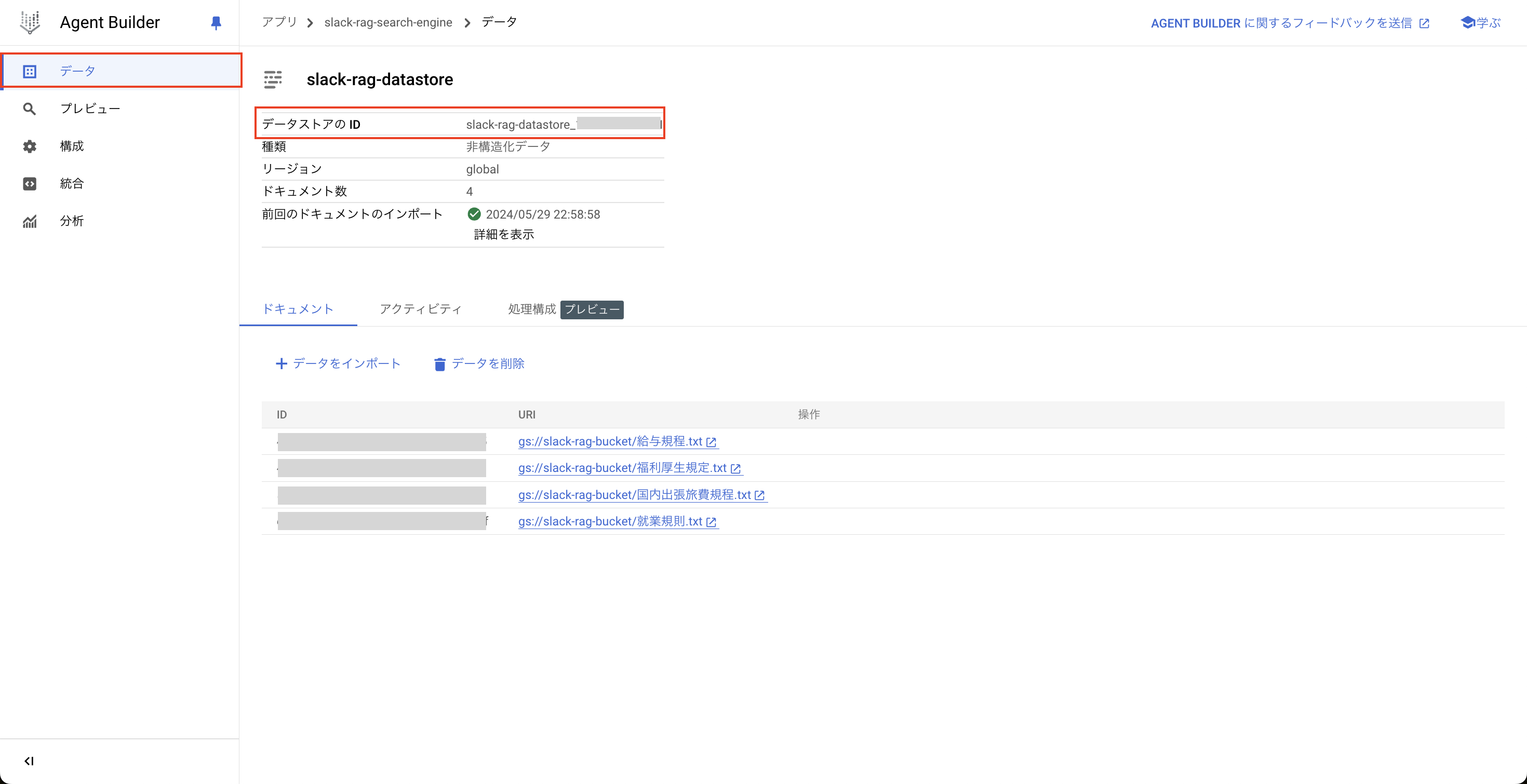
データストアIDを後の工程で使用するため、コピーしておきます。
Slackのメッセージ受信用の関数を作成
次にCloud Functionsにて関数を作成してきます。
mkdir -p ~/slack-rag-demo/slack-rag-app && cd $_
slack-rag-app内で以下のソースコードを用意します。
⚠️main.pyのソースコードを転載した際に43行目がブランクになってしまうため、以下のソースコードに置き換えて使用してください。(画像で申し訳ありません。)

main.py
import functions_framework
import json
import logging
import os
import re
logging.basicConfig(level=logging.DEBUG)
from slack_bolt import App, context
from slack_bolt.adapter.flask import SlackRequestHandler
"""Publishes multiple messages to a Pub/Sub topic with an error handler."""
from concurrent import futures
from google.cloud import pubsub_v1
from typing import Callable
from box import Box
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(os.environ["PROJECT_ID"], os.environ["TOPIC_ID"])
publish_futures = []
# process_before_response must be True when running on FaaS
app = App(process_before_response=True)
handler = SlackRequestHandler(app)
@functions_framework.http
def main(request):
headers = {"Content-Type": "application/json"}
body = request.get_json()
if body.get("type") == "url_verification":
print("url_verification")
res = json.dumps({"challenge": body["challenge"]})
return (res, 200, headers)
return handler.handle(request)
@app.event("app_mention")
def handle_app_mention_events(body: dict, logger):
body = Box(body)
event = body["event"]
text = re.sub("", "", event["text"])
thread_ts = event["ts"]
channel = event["channel"]
messages = {
"text": text,
"channel":channel,
"thread_ts": thread_ts,
}
publish_message(messages)
headers = {"Content-Type": "application/json"}
return ("OK", 200, headers)
def publish_message(messages: dict):
text = messages["text"]
channel = messages["channel"]
thread_ts = messages["thread_ts"]
data = json.dumps(
{
"data": {
"text": text,
"channel": channel,
"thread_ts": thread_ts
},
}
)
# When you publish a message, the client returns a future.
publish_future = publisher.publish(topic_path, data.encode("utf-8"))
# Non-blocking. Publish failures are handled in the callback function.
publish_future.add_done_callback(get_callback(publish_future, data))
publish_futures.append(publish_future)
# Wait for all the publish futures to resolve before exiting.
futures.wait(publish_futures, return_when=futures.ALL_COMPLETED)
def get_callback(
publish_future: pubsub_v1.publisher.futures.Future,
data: str
) -> Callable[[pubsub_v1.publisher.futures.Future], None]:
def callback(publish_future: pubsub_v1.publisher.futures.Future) -> None:
try:
# Wait 60 seconds for the publish call to succeed.
print(publish_future.result(timeout=60))
except futures.TimeoutError:
print(f"Publishing {data} timed out.")
return callback
requirements.txt
functions-framework==3.* slack-bolt==1.18.1 python-box==7.1.1 google-cloud-discoveryengine==0.11.11 vertexai==1.49.0 google-cloud-pubsub==2.21.1 cloudevents==1.10.1 requests==2.32.2
.env.yaml
このファイルの<>にはSlackのクレデンシャル情報やGCアカウントの情報を入力します。
SLACK_SIGNING_SECRET: <Signing Secret> SLACK_BOT_TOKEN: <Bot User OAuth Token> PROJECT_ID: <GCのプロジェクト名> TOPIC_ID: <Pub/Subのトピック名>
.gcloudignore
.env.yamlがデプロイされないように対象ファイルを定義します。
* !. !main.py !requirements.txt
ここまで用意できたら一度デプロイしてみます。
slack-rag-appのディレクトリ直下に移動して以下のコマンドを実行します。
gcloud functions deploy slack-rag-app \ --gen2 \ --runtime=python312 \ --region=asia-northeast1 \ --source=. \ --entry-point=main \ --trigger-http \ --env-vars-file .env.yaml \ --allow-unauthenticated
デプロイ成功時に表示される関数のURLはSlackアプリとの繋ぎこみに使用するためコピーしておきます。
コンソール画面からも取得することは可能です。
少し解説
main.pyではSlackから送信したメッセージを受け取り、Cloud Pub/Subにメッセージをパブリッシュしてから一旦Slackに200レスポンスを戻します。
これはSlackのAPIがリクエストを送ってから3秒以内に200レスポンスを受け取る必要があるためです。
3秒以内にレスポンスを受け取れない場合はデフォルトで3回までリクエストが再試行される仕様になっているようです。
回答生成とメッセージ返信の関数を作成
次もCloud Functionsで2つ目の関数を作成してきます。
mkdir -p ~/slack-rag-demo/slack-rag-search && cd $_
slack-rag-app内で以下のソースコードを用意します。
main.py
import base64
import json
import os
from cloudevents.http import CloudEvent
import functions_framework
import logging
logging.basicConfig(level=logging.INFO)
from google.api_core.client_options import ClientOptions
from google.cloud import discoveryengine_v1alpha as discoveryengine
from google.protobuf.json_format import MessageToDict
import requests
import vertexai
from vertexai.language_models import TextGenerationModel
from vertexai.generative_models import GenerativeModel, Part, FinishReason
import vertexai.preview.generative_models as generative_models
# Triggered from a message on a Cloud Pub/Sub topic.
@functions_framework.cloud_event
def main(cloud_event: CloudEvent):
data = base64.b64decode(cloud_event.data["message"]["data"]).decode()
data = json.loads(data)
text = data["data"]["text"]
channel = data["data"]["channel"]
thread_ts = data["data"]["thread_ts"]
documents = vais_search(
text = text,
project_id = os.environ["PROJECT_ID"],
data_store_id = os.environ["DATA_STORE_ID"],
)
result = generate_message(
text=text,
result=documents[0]["extractive_answers"][0]["content"],
project_id=os.environ["PROJECT_ID"])
link = documents[0]["link"]
result = f"{result}\n---\n{link}"
result = result.replace("<b>", "").replace("</b>", "").replace("**", "")
WEB_HOOK_URL = os.environ["WEB_HOOK_URL"]
requests.post(WEB_HOOK_URL, data=json.dumps(
{
"text" : result,
"channel" : channel,
"thread_ts" : thread_ts
}
))
headers = {"Content-Type": "application/json"}
return ("OK", 200, headers)
def vais_search(
text: str,
project_id: str,
data_store_id: str
) -> list:
client_options = (
ClientOptions(
api_endpoint=f"global-discoveryengine.googleapis.com"
)
)
client = discoveryengine.SearchServiceClient(client_options=client_options)
serving_config = client.serving_config_path(
project=project_id,
location="global",
data_store=data_store_id,
serving_config="default_config",
)
content_search_spec = discoveryengine.SearchRequest.ContentSearchSpec(
snippet_spec=discoveryengine.SearchRequest.ContentSearchSpec.SnippetSpec(
return_snippet=True
),
summary_spec=discoveryengine.SearchRequest.ContentSearchSpec.SummarySpec(
summary_result_count=3,
include_citations=True,
ignore_adversarial_query=True,
ignore_non_summary_seeking_query=True,
model_spec=discoveryengine.SearchRequest.ContentSearchSpec.SummarySpec.ModelSpec(
version="preview"
)
),
extractive_content_spec=discoveryengine.SearchRequest.ContentSearchSpec.ExtractiveContentSpec(
max_extractive_answer_count=1,
max_extractive_segment_count=1,
return_extractive_segment_score=True,
num_previous_segments=1,
num_next_segments=1,
)
)
request = discoveryengine.SearchRequest(
serving_config=serving_config,
query=text,
page_size=3,
content_search_spec=content_search_spec,
query_expansion_spec=discoveryengine.SearchRequest.QueryExpansionSpec(
condition=discoveryengine.SearchRequest.QueryExpansionSpec.Condition.AUTO,
),
spell_correction_spec=discoveryengine.SearchRequest.SpellCorrectionSpec(
mode=discoveryengine.SearchRequest.SpellCorrectionSpec.Mode.AUTO
),
)
response = client.search(request)
documents = []
for r in response.results:
document_info = {}
r_dct = MessageToDict(r._pb)
if 'link' in r_dct['document']['derivedStructData']:
document_info['link'] = r_dct['document']['derivedStructData']['link']
if 'extractive_answers' in r_dct['document']['derivedStructData']:
document_info['extractive_answers'] = r_dct['document']['derivedStructData']['extractive_answers']
document_info['summary'] = response.summary.summary_with_metadata.summary
documents.append(document_info)
headers = {"Access-Control-Allow-Origin": "*"}
return documents
def generate_message(text: str, result:str, project_id:str):
print("generate_message")
vertexai.init(project=project_id, location="asia-northeast1")
model = GenerativeModel(
"gemini-1.5-pro-001",
system_instruction=["""あなたは優秀な総務労務サポート窓口のエージェントです。"""]
)
context = f"{text}\n下記の文章を利用して上記の文章に対する回答を生成してください。回答では下記の文書を300文字で要約したものを使用してください。\n{result}"
generation_config = {
"temperature": 0,
"max_output_tokens": 8192,
"top_p": 0.95,
}
safety_settings = {
generative_models.HarmCategory.HARM_CATEGORY_HATE_SPEECH: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
generative_models.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
generative_models.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
generative_models.HarmCategory.HARM_CATEGORY_HARASSMENT: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
}
responses = model.generate_content(
[context],
generation_config=generation_config,
safety_settings=safety_settings,
)
return responses.candidates[0].content.parts[0].text
requirements.txt
functions-framework==3.* google-cloud-discoveryengine==0.11.11 vertexai==1.49.0 google-cloud-pubsub==2.21.1 cloudevents==1.10.1 requests==2.32.2
.env.yaml
このファイルの<>にはSlackアプリでコピーしたWebhookのURLやGCアカウントの情報、リソースのID名を入力します。
DATA_STORE_ID: <データストアID> WEB_HOOK_URL: <コピーしたWebhookURL> PROJECT_ID: <GCのプロジェクト名> TOPIC_ID: <Pub/Subのトピック名>
.gcloudignore
.env.yamlがデプロイされないように対象ファイルを定義します。
* !. !main.py !requirements.txt
こちらもgcloudコマンドを使用してデプロイしてみます。
slack-rag-searchのディレクトリ直下に移動して以下のコマンドを実行します。
gcloud functions deploy slack-rag-search \ --gen2 \ --runtime=python312 \ --region=asia-northeast1 \ --source=. \ --entry-point=main \ --trigger-topic=slack-rag-topic \ --env-vars-file .env.yaml \ --memory=512MB \ --allow-unauthenticated
少し解説
こちらの関数はCloud Pub/Subへのメッセージ発行をトリガーとして起動し、メッセージから値を取得してユーザ入力のテキスト文でRAG検索を行います。
その後300文字で要約して回答を生成するようにGeminiにリクエストし、結果をWebhookのURL先にレスポンスとして返します。
Event Subscriptionsの設定
ひと通りのリソース作成が終わったため、SlackのアプリとCloud Functions関数の繋ぎこみを行います。
Slack APIのページに戻り、サイドバーからFeatures > Event Subscrptionsを選択します。
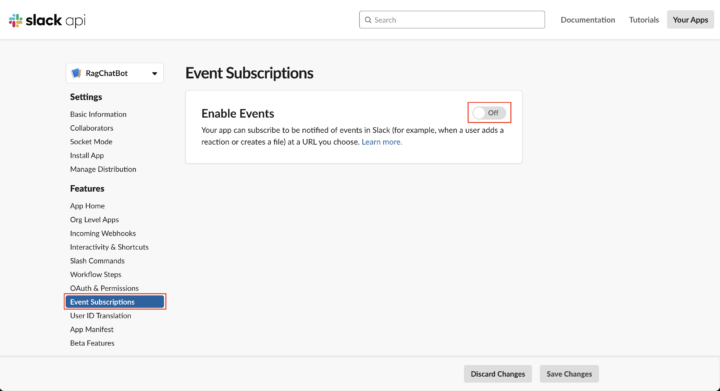
「Enable Events」をOnにして、「Request URL」に1つ目のCloud Functions関数のURLを貼り付けます。
「Verified」という緑色の文字が表示されれば接続に関しては問題ありません。
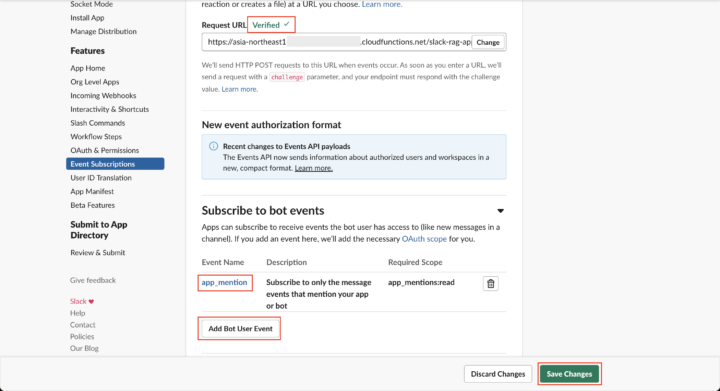
続いて同じ画面にてSubscribe to bot events > Add Bot User Eventを押下して「app_mention」を追加します。
これによりアプリに対してSlack上でメンションされた場合にイベントが起動するようになります。
その後画面下部にある「Save Changes」を押下して変更を保存します。
動作確認
Slackからアプリにメンションをあてて実行してみます。
※招待のメッセージが出ましたら追加して、チャンネル内に招待してください。

少し待つとスレッド上に回答が返ってきました。
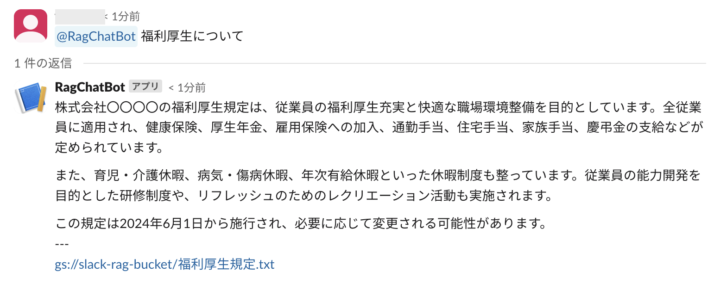
以上で実装は完了となります。
さいごに
最後までご覧いただきありがとうございます。
SlackのAPIとサーバレスのCloud Functionsを使ったRAG検索アプリを実装しましたがいかがだったでしょうか。
手順こそ少し多いものの慣れてしまえばものの数分でデプロイ可能な難易度かなと思っています。
サーバレスサービスを利用しているので比較的運用もしやすく、小難しい設定も特に不要な点が良いですね(サーバレス、API万歳!)
こちらの記事が少しでも皆様のお役に立てると幸いです。




