
概要
セッション詳細: How Vertex AI makes it easy to customize gen AI models
スピーカー:
Anand Iyer (Google Cloud Group Product Manager, Vertex AI)
May Hu (Google Cloud Group Product Manager, Vertex AI)
Lavanya Ramani (Palo Alto Networks Director of Engineering, NetSec)

セッション内容
このセッションでは Vertex AI で text-bison や Gemini といったモデルをどのようにカスタマイズできるのかの紹介とその具体的な手順の紹介が行われました。
あわせて Palo Alto Networks社における、モデルをカスタマイズしてドキュメントチャットボットを作成した成功事例の紹介も行われました。こちらもかなり質の良い内容のセッションでしたので、別記事で公開予定となります。
モデルのカスタマイズ手法
生成AI モデルはそのままの状態でも様々なタスクをこなすことができますが、エンタープライズのワークロードの多くでは、生成AI モデルをカスタマイズした方が特定のタスクにおいてより良い結果が得られる可能性が非常に高いです。とは言われても具体的にどのように生成AI モデルをカスタマイズするのか、なかなかイメージがつかないですよね。
生成AI モデルのカスタマイズとは、プロンプトエンジニアリングなどでプロンプトに context を与えたり、example を与えるのもカスタマイズの一つです。

ですが、一般的に生成AI におけるカスタマイズというと、グラウンディング / RAG とチューニングの2つの手法があげられます。ここで言うチューニングとは、新しいパラメータを学習するために、提供されたサンプルに基づいて新しいパラメータを学習することです。
グラウンディング / RAG はドメイン固有のコーパス (データソース) から関連する情報を動的に検索したり、Google 検索の結果をモデルに渡してカスタマイズすることができます。この手法は比較的手軽に行うことができます。
一方、チューニングは、従来の機械学習と同様に、提供された学習データをもとにモデルに新しいパラメーターを学習させることを指します。
グラウンディングかチューニングか
ではグラウンディング / RAG とチューニングのどちらを採用すべきかという話になりますが、この2つはそれぞれ排他的なものではなく、両方を併用することで回答の精度が最高になることがあるとのことです。実際に多くの顧客がこの2つを併用して使っているとのこと。
ただし使い分ける場合の判断材料としては、グラウンディングの場合はモデルに対して定期的に更新される事実情報を渡す場合に有効です。
チューニングが適している場合としては、より質の高い出力が求められる場合です。なぜなら、アプリケーションに最も関連性のある意味論的なルールやロジック、アプリケーションに最も関連する専門用語、ドメイン固有の構文や専門用語をモデルに教えることができるからです。

また、チューニングには安全性という側面もあります。エンタープライズアプリケーションの多くはより特定のタスクに焦点を当てていますが、それでもゴミのような入力を与えるエンドユーザーや悪意のあるエンドユーザーが存在する可能性があります。チューニングを行うことで、モデルに焦点を絞らせ、ゴミのような入力や悪意のある入力を無視するように教えることができます。
コスト面での判断基準
プロンプトを使用する場合、課金は入力プロンプト内のトークンの数に基づいて行われます。チューニングを行った場合、多くの場合において入力プロンプトのサイズを小さくすることができます。なぜなら、毎回コンテキストをそれほど渡さなくてもよくなるからです。
これによりチューニングを行ったモデルの方が入力トークン数が少なくなり、リクエストごとのランニング費用が削減できます。ですが、コスト計算は慎重に行う必要があります。チューニングを行うと、チューニングジョブを実行するコストがかかるからです。チューニングジョブを実行するコストとチューニングされたモデルを使用するコストのバランスをとる必要があります。しかし、QPS (クエリパーセコンド) の多いユースケースの場合、前もってチューニングを行っておくと、コストを節約できることがよくあるとのことです。
チューニングを行うとベースのモデルまで変更されるのか
チューニングを行うと、学習を行った際にベースとなった Gemini などのモデルまで変更されるかと疑問に思うかもしれませんが、結論から言ってしまうと Vertex AI 上でチューニングを行ってもベースとなったモデルのパラメータは変更されないとのことです。
これは Vertex AI ではアダプティブチューニングと呼ばれる最新の手法が採用されており、Gemini などのベースとなる生成AI モデルは変更せずにユーザーのトレーニングデータを用いてベースモデルのパラメータを微調整しているとのことでした。
これにより、お客様のユースケースに特化した出力を得ることができ、同時に Google Cloud の他のユーザーに影響を与えることなくお客様のデータを安全に保つことができるとのことです。
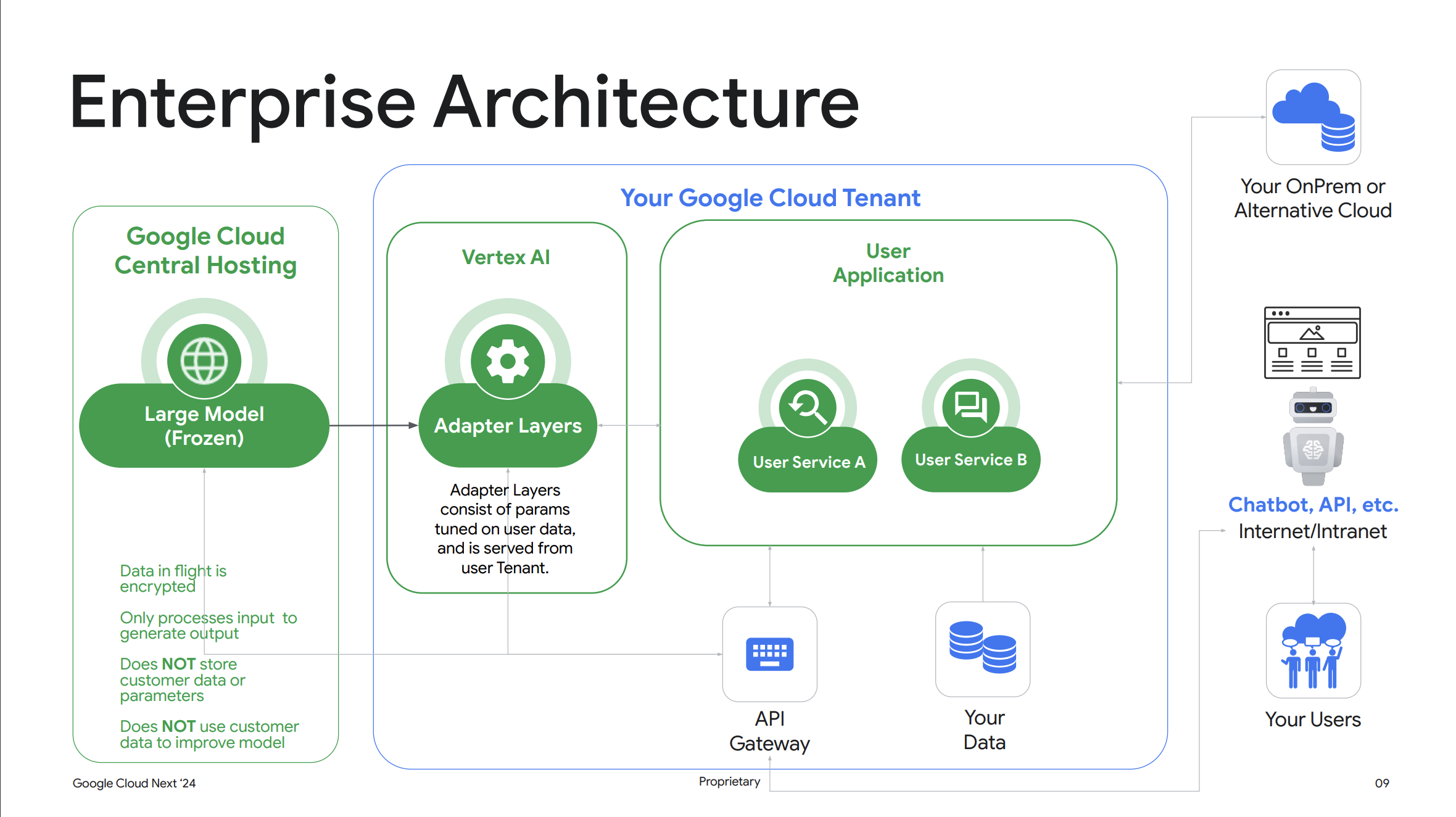
3つのチューニング手法
次にチューニングの一般的な手法として、以下で紹介する3つの手法が存在します。

教師あり学習 (Supervised Tuning)
Vertex AI における最も一般的なチューニング方法は、教師あり学習によるチューニングです。教師あり学習によるチューニングでは、チューニングジョブに例となるトレーニングデータを与えます。各例は、完全な入力プロンプトと、理想的な出力、つまりモデルの望ましい出力で構成されます。モデルの出力が複数の段落にわたる場合でも、すべての出力と高品質な評価基準を提示する必要があります。通常は数百個の高品質な例を用意すれば、良好な結果が得られるようになります。
人間のフィードバックによる強化学習 (RLHF)
次に、人間によるフィードバックを取り入れた強化学習がありますが、これは非常に複雑な手法です。教師あり学習との主な違いは、入力と望ましい出力を提示しない点にあります。強化学習では、モデルに2つの出力を提示し、どちらが出力が望ましいのかを教えます。人間によるフィードバックを取り入れた強化学習は、主観的な好みをモデルに教え込むのに役立ちます。あるいは、入力と出力を提示し、その出力が良好であったか悪かったかを教えることもできます。この場合、モデルは主観的な好みを学習します。
ディスティレーション (蒸留)
最後に、よく用いられる手法としてディスティレーションがあります。ディスティレーションでは教師モデルとして大きなモデルを利用し、小さなモデルを作成します。
教師あり学習のトレーニング手順
教師あり学習は、お客様のデータを使ってモデルの動作をカスタマイズする手法です。

このプロセスでは、モデルの出力をチューニングデータセットで提供されたラベルとの差を最小化するために、モデルの重みを更新します。教師あり学習によるチューニングは、出力が定義しやすいユースケースに最適です。例えば、カテゴリ化、要約、特定のスタイルへの準拠、長文からの属性抽出などのユースケースでのチューニングに適しています。

トレーニングに適したデータの準備
機械学習はトレーニングに使用するデータセットが重要であり、生成AI モデルでも同様です。チューニングされたモデルの品質は、データセットの品質に大きく依存します。以下はチューニングデータセットの見本です。

Vertex AI ではアダプティブチューニングと呼ばれる特殊なチューニング手法が採用されています。アダプティブチューニングは、基本モデルを固定し、お客様のデータを使用して別の非常に小さなアダプターを構築することで、コスト効率よくモデルをカスタマイズすることができます。アダプティブチューニングの性質上、通常は数百個の例だけで良好なパフォーマンス向上が見られるとのことです。もちろん、パフォーマンスをさらに向上させるためにより多くの例を追加することもできますが、その際には追加する例の数は適切に増やすようにしてください。
また、チューニングデータセットは本番環境で想定される状況を模倣する必要があります。フォーマット、コンテキスト、およびチューニングデータセットの分布は、本番環境でモデルが扱うと想定されるものと一致させる必要があるとのこと。

プロンプト設計
2つ目のポイントとしては、常にプロンプトエンジニアリングのベストプラクティスを採用し、実行するタスクの詳細な説明と出力の形式に関する明確な指示を提供する必要があるとのこと。ただし、チューニングではすでにモデルに例を学習させているため、プロンプト内に少数の短い例を入れる必要がなくなります。
チューニングデータセットを準備したら、Vertex AI からチューニングジョブを作成することができます。ジョブが送信されると、チューニングジョブの進捗状況を視覚化できるリアルタイム監視機能が提供されます。このプロセス中に、チューニングされたモデルの品質に大きな影響を与える可能性のある注意点がいくつかあるとのことです。
トレーニング時によく発生する問題
1つ目のよくある問題は、過学習 (Overfitting) です。過学習はモデルがトレーニングデータセットから学習しすぎて、新しいデータに対して一般化する能力を失ってしまう状態です。Vertex AI のパフォーマンスグラフを見ることで簡単に発見できるとのことです。
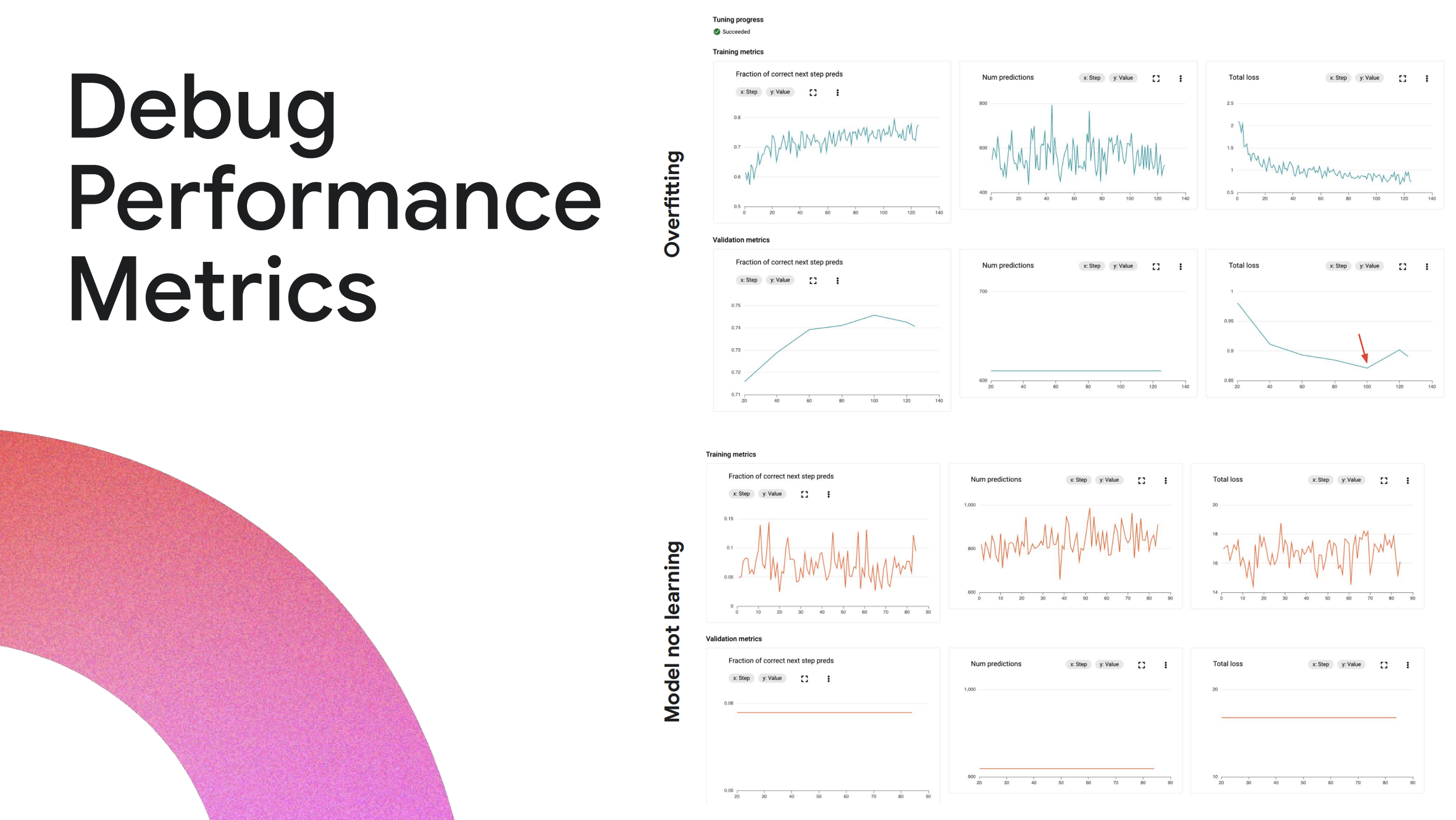
パフォーマンスグラフの最初の行は、トレーニングデータのパフォーマンス指標を示しており、トレーニングが進むにつれて精度が向上し、損失が減少していることが確認できます。これらはすべて良い兆候であり、モデルが学習していることを意味します。
しかし、2行目の検証データセットのメトリクスは、最初は精度が向上しその後減少します。損失も同じように、最初は減少してから増加します。これは過学習の典型的な兆候とのことです。過学習を修正するには、検証データセットのパフォーマンスの損失が最小になるポイントまで、トレーニングデータセットの例の数を減らすと良いとのこと。
もう1つのよくある問題は、せっかくチューニングデータセットの準備とジョブの実行に時間をかけても、モデルが学習しないことです。Model not learning のグラフを見ると、精度と損失が変動していますが、全体的な傾向としては横ばい状態です。
よくある原因としてはトレーニングデータセットにあるようです。もう少し詳しく見てみると、損失の値が非常に大きくなっています。損失が 10を超える値から始まる場合、モデルはラベルから大きくかけ離れた予測を行っていることを示しており、非常に間違った回答を出力しています。
考えられる根本的な原因としては、入力プロンプトがモデルが許容する最大コンテキスト長を超えていることが考えられるとのこと。このような場合、入力プロンプトは切り捨てられ、モデルは不完全なプロンプトに基づいて予測を行っているため間違った予測を出力します。この問題を解決するには、トレーニングデータセットが入力プロンプトの最大コンテキスト長を超えないようにし、次に紹介するベストプラクティスに準拠する必要があります。
教師あり学習におけるベストプラクティス
以下は教師あり学習のチューニングにおけるベストプラクティスです。

評価
最初に必ずゴールを設定してください。チューニングで何を達成したいのか、成功をどのように測定したいのかを明確にすることが重要です。評価手法と指標は、最初に定義しておくことが成功の鍵となります。
Vertex AI では、チューニングサービスが評価サービスと統合されており、チューニングされたモデルに対して行列ベースの評価や並列評価を実行できます。並列評価は Vertex AI で導入された革新的なアプローチであり、大規模言語モデルを使用してチューニングされたモデルとベースモデルの出力を比較し、チューニングされたモデルがベースモデルよりも優れているかどうかを確認することができます。
参考: AutoSxS
実験
次に、チューニングは反復プロセスであることを理解する必要があります。これは他のモデルトレーニングと同様で、データセットを厳選しさまざまなハイパーパラメーターを試すことで、最適な構成を見つける必要があります。
Vertex AI では、すべてのチューニングジョブが Vertex Experiment AI で管理されているため、パフォーマンス指標を視覚化し、異なるチューニングジョブを簡単に比較して最適なラウンドを見つけることができます。
モニタリング
最後に、チューニングされたモデルを本番環境にデプロイした後も、本番トラフィックを継続的に監視する必要があります。モデルに送信されるクエリの種類を追跡します。これらはすべて、モデルのパフォーマンスを継続的にチューニングして向上させるために役立つ貴重な情報になります。
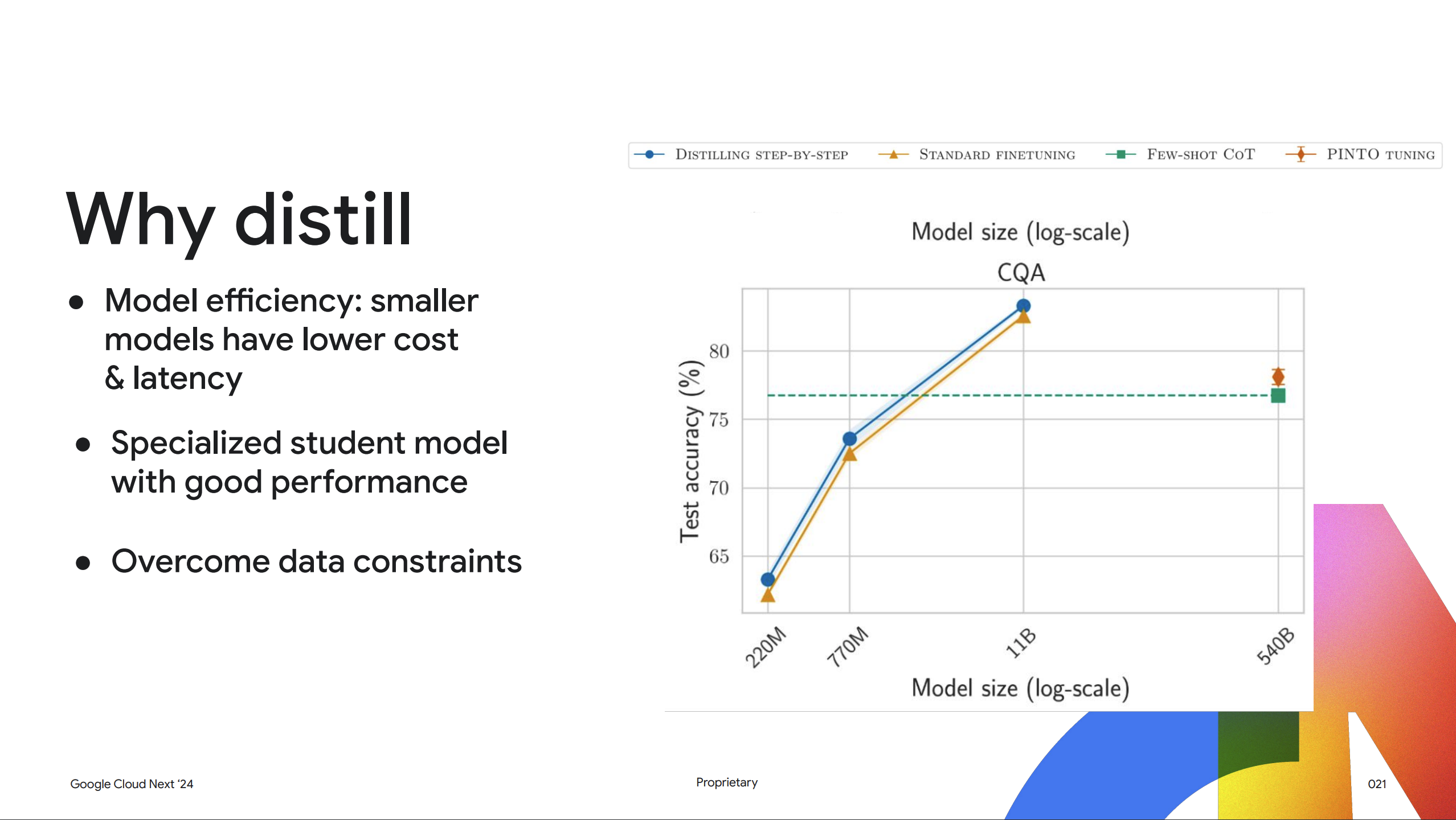
なぜディスティレーションを行うのか
生成AI において回答精度だけが重要ではなく、コストとレイテンシも重要になってきます。チャットボットを構築していると想像してください。チャットボットがどんなに完璧な回答を返しても、応答に 10 秒もかかってしまうとユーザーはストレスが溜まってしまいます。このような場合に、ディスティレーションが役立ちます。

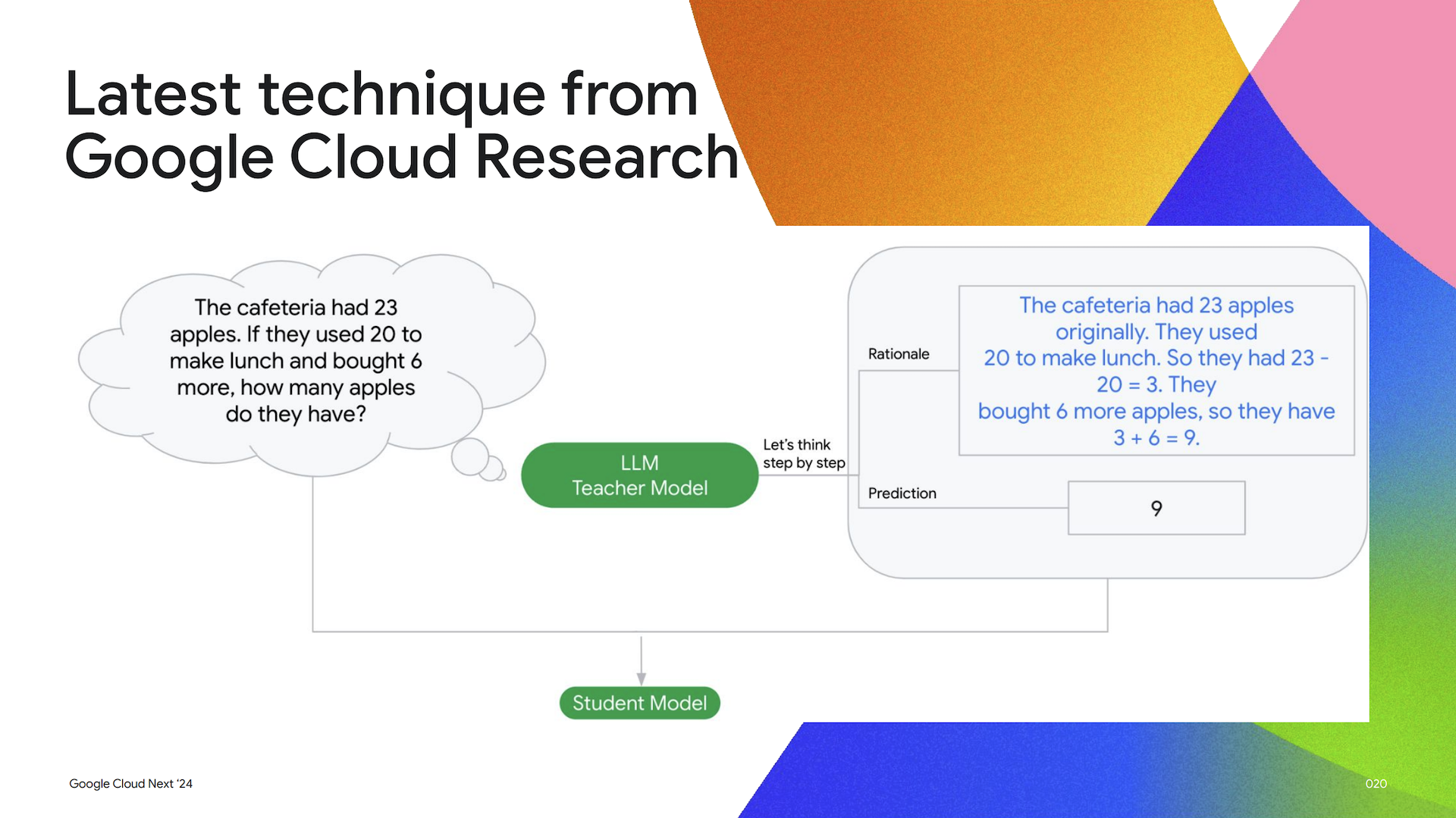
ディスティレーションは、モデルサイズを小さくすることで、提供時のコストを削減しレイテンシを改善します。Vertex AI では、Google Cloud Research から最新のディスティレーション手法を採用しているとのことです。これは「Distilling Step-by-Step」という公開論文で詳しく説明されているようですが、簡単に言うと、教師モデルと呼ばれる強力なモデルを使用して、予測とその予測の根拠 (なぜモデルがそのような予測を行うのか) を生成します。次に、根拠と予測の両方を使用して、はるかに小さな生徒モデルを訓練し教師モデルから学習させます。つまり、ディスティレーションを使用すると、はるかに小さな生徒モデルを訓練して、低コストかつ低レイテンシでタスクを実行させることができます。
なお、Vertex AI では教師モデルとして Gemini Pro や、生徒モデルとして Google のオープンソースの軽量モデルである Gemma などが利用できます。チューニングされたモデルは、最終的に Vertex AI Model Registry にアップロードされます。その後、Vertex AI 予測サービスを使用してエンドポイントを作成し、モデルをデプロイできます。
そして、ディスティレーションにはもう1つの利点があります。先ほど説明した教師あり学習の話に戻りますが、チューニングの成功には高品質なラベル付きデータセットが重要であることを説明しました。しかし、すべてのお客様がこのような高品質なデータセットを準備するのは現実的に考えて難しいです。なぜなら、高品質なラベル付きデータセットを作成するには、時間と労力が必要だからです。
ディスティレーションでは、人間にラベリング作業を依頼する代わりに、教師モデルを使用して自動的にラベリングを行います。言い換えれば、ラベル付けされていないデータセットを提供するだけで済み、残りはすべて Vertex AI が処理してくれます。
最後に
Vertex AI におけるモデルのカスタマイズを紹介してきましたが、いかがでしたでしょうか。生成AI はそのままの状態でもかなり複雑なタスクもこなすことができますが、独自のデータを与えてチューニングすることで、よりそのタスクに特化した回答を行えるようにすることができます。
生成AI に使われる LLM モデル自体、すでに大量のデータとコストをかけてトレーニングされているので、そこから+αで特定のタスクに特化させるチューニングを行えることはかなりコスト効率が良いですよね。
私自身お客様のプロジェクトで Gemini を用いた開発をしていますが、テキストのデータセットと合わせて画像や動画をインプットデータセットとしてチューニングできるようになると、更に生成AI 活用の幅が広がりそうですので、今後のアップデートを期待したいですね。
また、Gemini モデルをカスタマイズした検証ブログも書きたいと思いますので、楽しみにしていただけると幸いです。




