
概要
セッション詳細: Claude 3 on Vertex AI: Implementation best practices
スピーカー:
Anusheel Pareek (Google Cloud Product Manager)
Maggie Vo (Anthropic Head of Technical Education & Enablement)

セッション内容
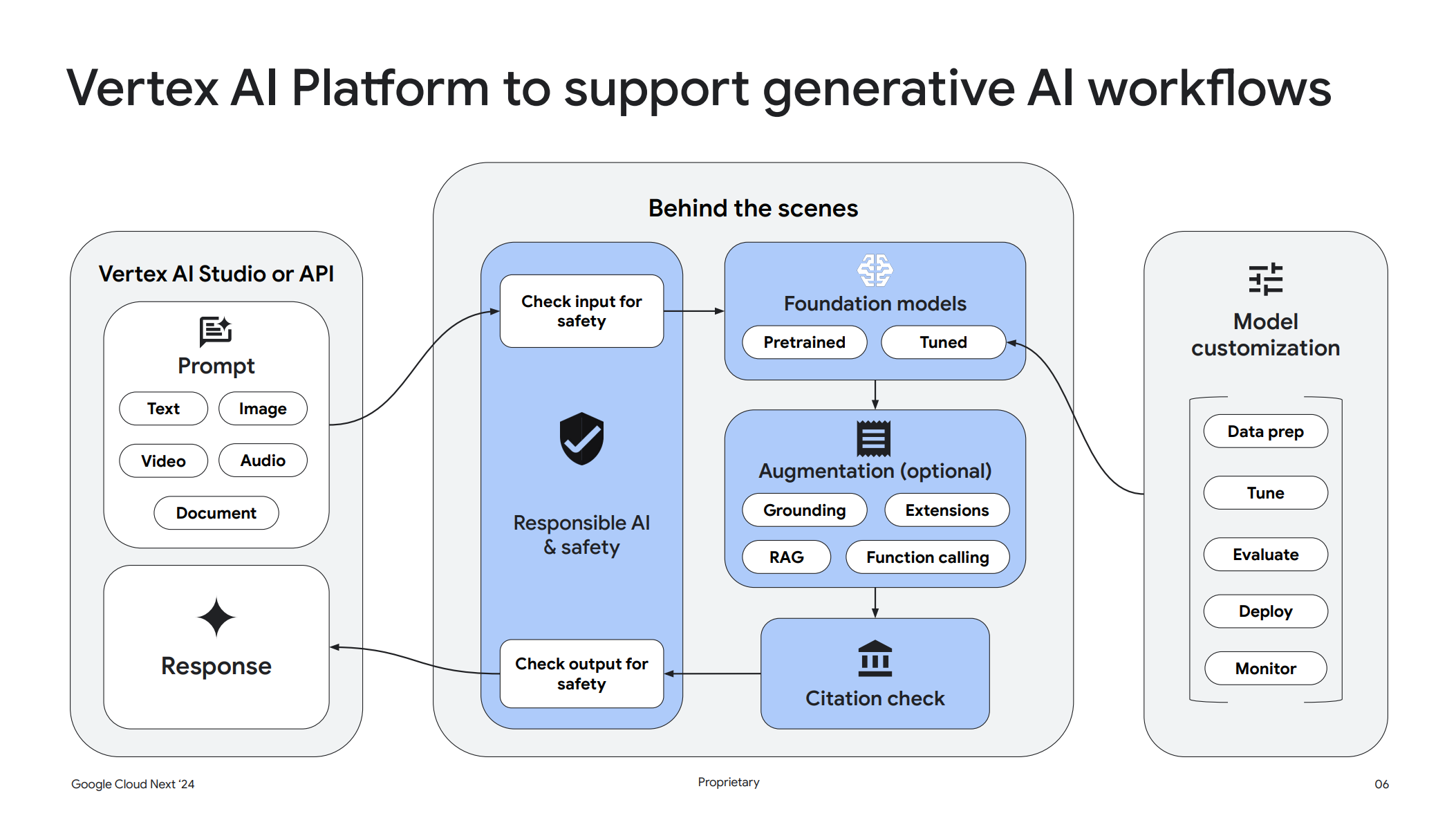
AI プラットフォームが必要な理由
生成AI 技術は日々進化しており、数ヶ月ごとに新しいモデルやツールが登場します。
基礎的なモデルを使い始めるのは簡単そうに見えるかもしれないですが、生成AI を活用したアプリケーションを本番環境にデプロイすることを考えると、とても複雑で難しくなってしまいます。
それはなぜかというと、モデルに限らずいくつかの異なるコンポーネントを組み合わせる必要があるからです。

そこで Vetex AI のような AI の統合プラットフォームが必要となってくるのです。
Vertex AI Studio ではエンジニアと対話し、複数の異なる基礎モデルを評価することができます。その後に Model Builder を利用してモデルをカスタマイズすることもできます。また、Agent Builder でグラウンディング技術を使ってハルシネーション (幻覚)を抑制しモデルを補強することもできます。
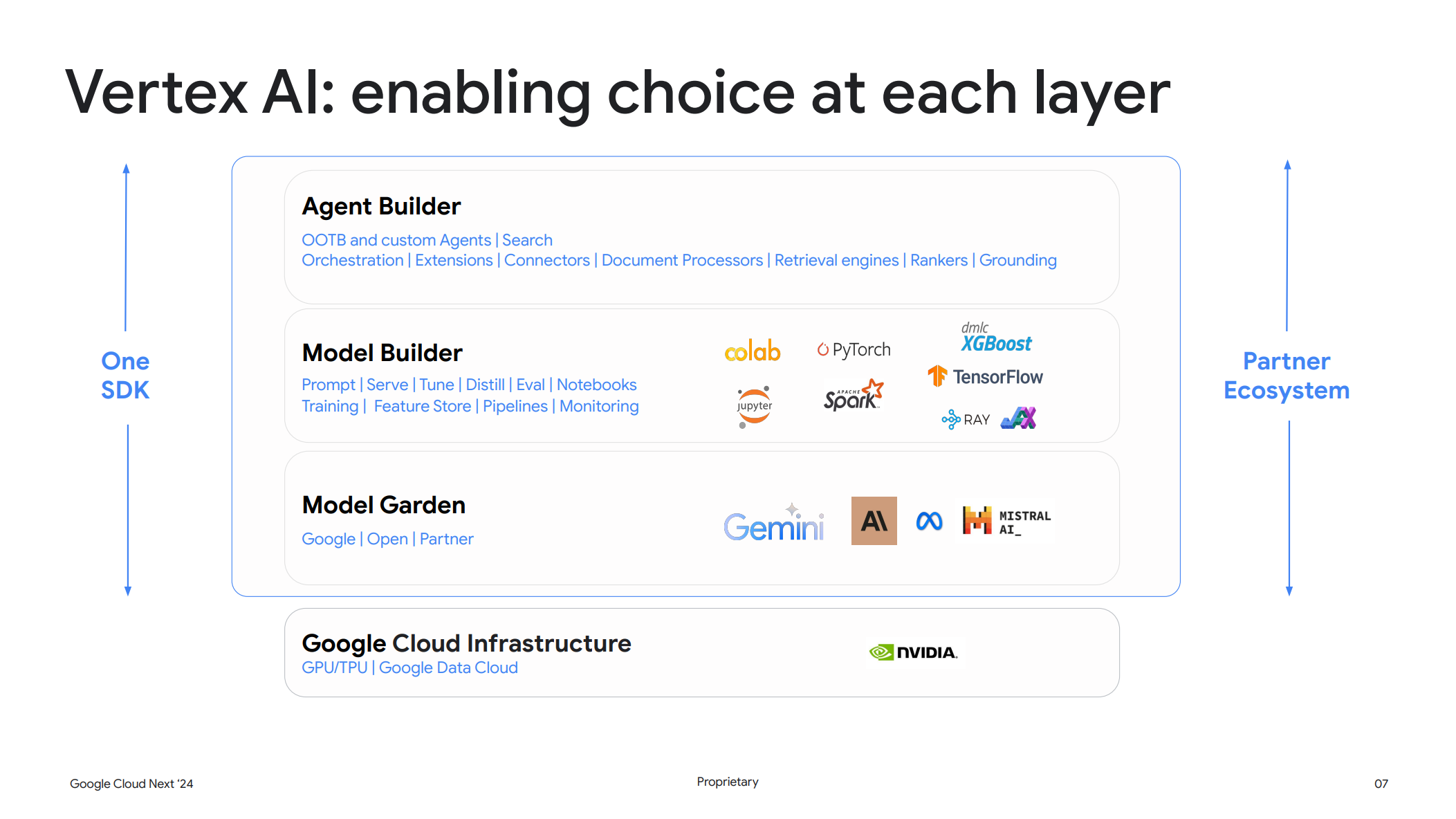
また AI モデルは130種類以上のモデルが存在し、これらは差別化されています。1つのモデルですべての AI ユースケースを解決することはできないと強く信じているとのことで、そのため Model Garden ではエンタープライズでも利用可能な AI モデルの幅広い選択肢が提供されています。

もちろん、今回紹介する Claude 3も Model Garden 内で選択可能です。
Claude 3のモデル
Claude は Anthropic社により開発、提供されている LLM モデルで以下の特徴があります。
- 他の最先端モデルに匹敵する品質を備えた最速のビジョンモデル
- 指示を行いやすい
- 正確で信頼できる

また、Claude 3には以下の3つのエディションが存在します。
- Opus
- Sonnet
- Haiku

上から順に精度とコストが高くなりますが、ただ興味深いのは最も処理が高速なのが一番低コストの Haiku で、2秒以内に3万5000単語を読み込むことができるとのこと。(Opus は2000単語)
なので、Haiku はチャットボットなど処理速度が重視されるような用途に向いており、Opus は複雑なタスク、Sonnet はやや複雑だが速度も重視される用途に適しているとのこと。
Opusは最小限のプロンプトで高精度の回答を行うことができる特徴もあります。

また、Claude 3の全体的な特徴として誤った回答を行うことが少なくなっており、かつ JSON の処理を得意としており、追加で補足しなくとも非常に複雑な JSON 構造を実行できるとのことです。

なぜプロンプトエンジニアリングが重要なのか
プロンプトは生成AI に実行したい処理を自然言語で指定するものですが、このプロンプトの内容次第で生成AI の回答精度は大きく異なります。
ですので、より高精度の回答を必要とする場合はこのプロンプト設計 = プロンプトエンジニアリングが重要となってくるのです。

以下は Maggie氏が提唱する高精度な回答を引き出すプロンプトの例です。

Task context
You will be acting as an AI career coach named Joe created by the company AdAstra Careers. Your goal is to give career advice to users. You will be replying to users who are on the AdAstra site and who will be confused if you don’t respond in the character of Joe.
あなたが演じるのは、アドアストラ社の AI キャリアコーチ、ジョーです。キャリア。あなたの目標は、ユーザーにキャリアアドバイスをすることです。あなたは、アドアストラのサイトにいるユーザーに返信することになりますが、ジョーのキャラクターで返信しないと、ユーザーは混乱してしまいます。
何かを与える前に、これから何をしようとしているのか、どんな種類の情報に遭遇しようとしているのかを理解させます。ここでは AI キャリアコーチであることを指定しています。
Tone context
You should maintain a friendly customer service tone.
フレンドリーな接客態度で接すること
Tone context ではフレンドリーなカスタマーサービスであることを伝えています。
Background data, documents, and images
Here is the career guidance document you should reference when answering the user: {{DOCUMENT}}
以下は、利用者に回答する際に参照すべき進路指導の文書です:
{{DOCUMENT}} です。
Background data では背景となるデータ、分析に使う本や画像から得たすべての情報を与えます。このような情報は、最後の方ではなく、最初の方に伝えるのが良いとのことです。また分析するための文章を必要な箇所のみではなく全てを渡してしまうとパフォーマンスが悪化してしまうとのこと。特に Claude ではその傾向が顕著とのことです。
Detailed task description & rules
Here are some important rules for the interaction:
– Always stay in character, as Joe, an AI from AdAstra careers
– If you are unsure how to respond, say “Sorry, I didn’t understand that. Could you repeat the question?”
– If someone asks something irrelevant, say, “Sorry, I am Joe and I give career advice. Do you have a career question today I can help you with?”
ここで、対話のための重要なルールをいくつか紹介しよう:
– 常に、アドアストラのAIであるジョーのキャラクターでいること。
– どう答えていいかわからない場合は、「すみません、理解できませんでした。もう一度と言ってください。
– 関係ないことを聞かれたら、「すみません、私はジョーで、キャリアアドバイスをしています。今日、私がお手伝いできるキャリアに関する質問はありますか?” と言ってください。
ここでは、このタスクの詳細と実行するために取るべきすべてのステップに関する指示を与えます。
Examples
Here is an example of how to respond in a standard interaction:
User: Hi, how were you created and what do you do?
Joe: Hello! My name is Joe, and I was created by AdAstra Careers to give career advice. What can I help you with today?
以下は、標準的なインタラクションでの応答方法の例である:
<例>
ユーザー:こんにちは。
ジョー:こんにちは!私はジョーです。アドアストラ・キャリアがキャリアアドバイスをするために作りました。今日はどんなご用件でしょうか?
Examples には何をすべきかをさらに強調するために、期待するプロンプトと回答の例を指定します。
Conversation history
Here is the conversation history (between the user and you) prior to the question. It could be empty if there is no history: {{HISTORY}} Here is the user’s question: {{QUESTION}}
質問の前の(ユーザーとあなたの)会話履歴です。履歴がない場合は空になります:
{{HISTORY}} です。
ここにユーザーの質問があります:{{質問}}です。
会話履歴がある場合、それをプロンプト内に含めるか、API コール時に別で指定することもできます。どちらの方法でも上手くいくようです。
Immediate task description or request
How do you respond to the user’s question?
ユーザーの質問にどう答えるか?
非常に長いプロンプトの場合、最後にタスクの説明をもう一度伝えると期待する形式での回答を得られる可能性が上がる場合があります。
Thinking step by step / take a deep breath と Output formatting
Think about your answer first before you respond. Put your response in
tags. 応答する前に、まず答えを考えてください。応答を
タグ内に記述します。
回答までに複数のステップがあり、それをすべて順に実施した後に回答を作成し、決められた箇所へレスポンスするように指示を行います。
Prefilled response (if any)
最後に Claude 独自のプレフィリングレスポンスと呼ばれるものがあり、この機能を利用することで出力形式を制御したり、ロールプレイシナリオ中に Claude がそのキャラクターを維持できるようにすることもできるとのことです。
プロンプトエンジニアリングの重要な7つのテクニック
続いてプロンプトエンジニアにおける重要な7つのテクニックを紹介していきます。
0. ユーザー/アシスタントの役割の形式

まず事前準備として、ユーザーと AI アシスタントのロールの定義と、コンテンツデータの構造化を行います。
1. 明確かつ直接的であること

1つ目のテクニックとして、明確で直接的な指示を与え、複雑な作業にはステップごとに番号を割り振りリスト化します。
2. ロールを割り当てる(別名ロールプロンプト)

2つ目のテクニックとして、Claude がどのような役割を担うべきかを指定します。これにより Claude は以下のように機能します。
- 指定された役割に合わせて Claude の口調や態度を変える
- 特定の状況(数学など)における Claude の正確さを向上させる
3. XML タグの使用

3つ目のテクニックとして、プロンプト内に XML タグである<>を利用することで、Claude がプロンプトの構造を理解するのに役立ちます。Claude は XML タグを学習していますが、他の区切り文字についても学習済みで同様のテクニックが使えるとのことです。
4. 構造化されたプロンプトテンプレートを使用する

4つ目のテクニックとして、プロンプトをプログラミング関数のように考えて変数と命令を分離します。具体的には変数を XML タグで囲み、テンプレートを構造化します。
これによりプロンプトの保守が容易になり、複数のデータセットの処理が高速化されます。
5. Claude の回答を事前に入力する

5つ目のテクニックとして、ロールで定義された Assistant (prefill) フィールドのコンテンツに、Claude に求めるレスポンスの最初の箇所を定義することで、Claude にその形式でレスポンスを行うように要求することができます。
この例でいうと、ユーザーが猫の俳句を句ごとに JSON 形式で出力するように要求しているので、{を入力することで生成AI はその続きを JSON 形式で返却します。
<br />"first_line": "Sleeping in the sun", "second_line": "Fluffy fur so warm and soft", "third_line": "Lazy cat's day dreams" }
6. Claude に段階的に考えさせる
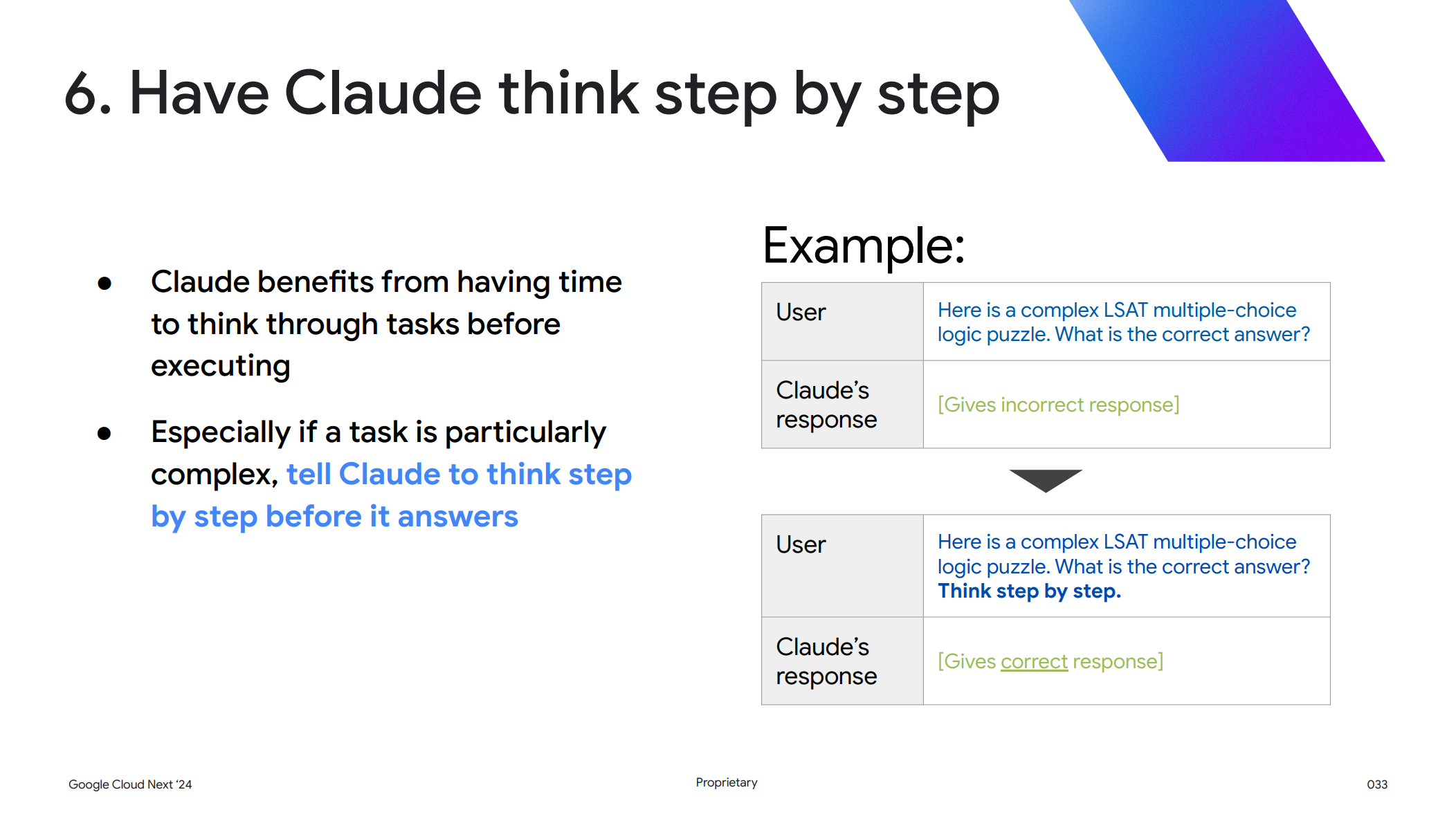

6つ目のテクニックとして、Claude が回答を作成する前に段階的に考えるように指定します。これは特に複雑なタスクの場合に有効で、
7. Examples を使う(別名 N ショットプロンプト)

7つ目のテクニックとして、これから行う質問と回答の例をプロンプト内で与えることで、回答の内容やフォーマットを期待通りに要求することができます。
ボーナス: 画像を含むプロンプト

最後のテクニックとして、画像をプロンプト内に含める場合はタスクの命令やユーザークエリの前に置き、さらに画像が複数ある場合は「画像1:」や「画像2:」のように書く画像を列挙します。これによりタスクの実行前に Claude に画像を理解させて詳細を抽出させることができ、パフォーマンスが向上するとのことです。
ハルシネーションへの対処
続いてハルシネーション (幻覚) の対策についてです。ハルシネーションとは生成AI が事実とは異なった回答をしてしまう問題のことです。その AI モデルが学習したデータがそれ以降に更新されているなど学習済みの情報が古い場合や、学習しておらず予測で回答を導き出した場合などにこの問題が発生してしまいます。

Magiee氏は Claude におけるハルシネーション対策としては以下の3つが有効とのことでした。
- 分からないなら Claude に「分からない」と言わせる
- Claude に、返答に自信がある場合のみ答えるよう伝える
- Claude に長い文書から関連する引用を探してもらい、引用を使って答えるように指示する
その他のベストプラクティス
その他のベストプラクティスとして、外部関数の呼び出しによる Claude が回答できない情報をグラウンディングする方法や、RAG によるハルシネーション対策や内部データに基づいた回答の生成の説明がありましが、特に Claude に特化した内容ではなく一般的な生成AI で言及されている内容と同一でしたので、ここでは詳細な説明は割愛します。
最後に
GPT-4や Gemini のライバルとして注目されている Claude 3の特徴やベストプラクティスを解説してきましたが、いかがでしたでしょうか。
私自身 Claude のエディションによって特性が変わり、コストや精度と処理の速さがトレードオフの関係にあるということは驚きでした。
またモデルによってプロンプトの設計方針や与える情報が変わってくるのも、モデルの特性が出て非常に興味深い発見でした。
Claude 3は Vertex AI や AWS の Amazon Bedrock でも利用可能なモデルですので、Gemini などで回答の精度が出ない場合などに使い分けていきたいですね。




