
Mahoutとは、Javaで記述された機械学習ライブラリで、リコメンデーション処理などをHadoop上で実行することもできます。
Hadoop上でということなら、当たり前ですが、AWSのElastic MapReduceでも実行することができると思います。
ということで、実際にMahoutを使って、Elastic MapReduceでリコメンデーションをしてみました。
尚、Mahoutのリコメンデーションに関しては、@daisuke_mさんのブログ(都元ダイスケ IT-PRESS)で丁寧に紹介されています。
特に、レコメンデーションの簡単な原理を視覚的に把握してから実際に計算してみるの記事は、リコメンデーションのイメージを掴むのに最適です!
それでは実際に試してみたいと思います。
まずはじめに、S3の適当な場所にMahoutのJarとリコメンデーションに利用するデータを
配置します。
配置するJarは、Index of /infosystems/apache//mahout/0.5からダウンロードした
mahout-core-0.5-job.jarとなります。
下記のようなデータが、リコメンデーションに利用するデータで、ユーザーIDとそのユーザーが購入した商品をカンマで区切って、並べた形になっています。
▼ vote.txt
1,1 1,2 1,3 1,4 1,5 2,2 2,4 2,6 2,8 3,3 3,6 3,9 4,4 4,8 5,5 6,2 6,4 6,6 6,8 6,10 7,4 7,8 7,2 7,6 8,6 8,2 8,8 9,8 9,6 10,10
必要なファイルをS3に配置したら、実際にAWS Management ConsoleでElastic MapReduceを利用します。
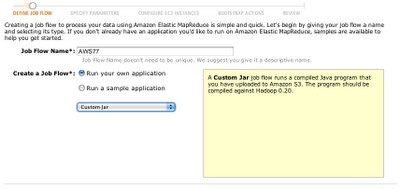
そして、リコメンデーションで使うクラスや引数などをS3に配置したファイルを指定する形で指定します。
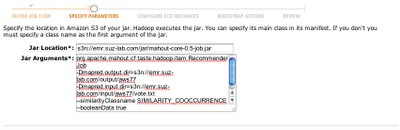
入力項目は下記の通りです。
Jar Location
s3n://emr.suz-lab.com/jar/mahout-core-0.5-job.jar
Jar Arguments
org.apache.mahout.cf.taste.hadoop.item.RecommenderJob -Dmapred.output.dir=s3n://emr.suz-lab.com/output/aws77 -Dmapred.input.dir=s3n://emr.suz-lab.com/input/aws77/vote.txt –similarityClassname SIMILARITY_COOCCURRENCE –booleanData true
基本的には、Hadoopを利用するときと同様で、ファイルの入出力部分の対象がS3になっているので、注意してください。
今回は、–similarityClassnameにSIMILARITY_COOCCURRENCEを利用しましたが、他にも、
SIMILARITY_COOCCURRENCE
SIMILARITY_EUCLIDEAN_DISTANCE
SIMILARITY_LOGLIKELIHOOD
SIMILARITY_PEARSON_CORRELATION
SIMILARITY_TANIMOTO_COEFFICIENT
SIMILARITY_UNCENTERED_COSINE
SIMILARITY_UNCENTERED_ZERO_ASSUMING_COSINE
SIMILARITY_CITY_BLOCK
と指定します。
(現時点で違いは全くわかってないため、どこかでまとめて勉強しておきます。)
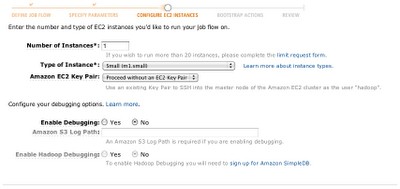
そして、実際に起動するインスタンスのタイプや数を指定して実行します。

実行結果は、出力先(s3n://emr.suz-lab.com/output/aws77)に
part-r-00000というファイル名で、書き出されました。
(データが多く、インスタンスも複数起動していると、複数ファイル書き出されると思います。)
▼ part-r-00000
1 [6:8.0,8:8.0,10:2.0,9:1.0] 2 [10:4.0,3:3.0,1:2.0,5:2.0,9:1.0] 3 [2:5.0,8:5.0,4:4.0,1:1.0,5:1.0,10:1.0] 4 [2:8.0,6:8.0,10:2.0,1:1.0,5:1.0,3:1.0] 5 [1:1.0,2:1.0,3:1.0,4:1.0] 6 [3:3.0,1:2.0,5:2.0,9:1.0] 7 [10:4.0,3:3.0,1:2.0,5:2.0,9:1.0] 8 [4:11.0,10:3.0,3:2.0,1:1.0,5:1.0,9:1.0] 9 [2:8.0,4:7.0,10:2.0,3:1.0,9:1.0] 10 [2:1.0,4:1.0,6:1.0,8:1.0]
以上のことから、他のユーザーの購入動向より、おすすめ商品が計算されているのが、
何となくわかるのではないかと思います。
ユーザー 購入済み商品 おすすめ商品 おすすめ度 1 : 1,2,3,4,5 -> 6,8 ( 8.0) 2 : 2,4,6,8 -> 10 ( 4.0) 3 : 3,6,9 -> 2,5 ( 5.0) 4 : 4,8 -> 2,6 ( 8.0) 5 : 5 -> 1,2,3,4 ( 1.0) 6 : 2,4,6,8,10 -> 3 ( 3.0) 7 : 2,4,6,8 -> 10 ( 4.0) 8 : 2,6,8 -> 4 (11.0) 9 : 6,8 -> 2 ( 8.0) 10 : 10 -> 2,4,6,8 ( 1.0)