
この記事はアイレット25卒社員によるAWSブログリレーのAmazon CloudWatch(以後CloudWatch)編です。
この記事はJapan AWS Top Engineersのクラウドインテグレーション事業部 セキュリティセクション 田所 隆之さんの監修の下、執筆をしました。
AWSブログリレーでは初学者や営業職の方などのこれからAWSについて学習する方向けに1記事1AWSサービスの概要やユースケースを解説するブログリレーとなっております。
AWSブログリレーについてはこちらの記事で詳しく記載しておりますので、よろしければご覧ください!
CloudWatchの概要
CloudWatchは、AWSリソースとAWSで実行するアプリケーションのモニタリング(既知の問題の監視)とオブザーバビリティ(可観測性)ができるサービスです。
CloudWatchを利用することで、システム全体が正常に稼働しているか、パフォーマンスに問題はないか、予期せぬエラーは起きていないか、といった状態をリアルタイムで把握し、問題が発生した際には自動的にアクションを起こすことができます。
CloudWatch以外にもサードパーティ製の監視ツールは存在しますが、CloudWatchは他のAWSサービスとの連携が容易で主要なAWSサービスはエージェントの導入が必要ないサービスが多いことが差別化ポイントだと思います。
そういったAWSシステムとのネイティブ統合やAWSに特化したモニタリングが実現できるのが特徴的です。
また、CloudWatchを通して他のAWSサービス(LambdaやEventBridge)と連携して容易に一次運用の自動化やログ分析を実現できます。
CloudWatchの機能は他のサービスと比べても内容量が多く、一つの記事で全ての機能を紹介すると情報量が多くなってしまいます。
そのため、今回はCloudWatchの主要機能であるアラーム・ログ・メトリクスを紹介します。
どんな機能があるのか
アラーム(CloudWatch Alarms)
アラームは、AWSリソースの状態を監視し、事前に定義したルールに基づいて自動的にアクションを実行する機能です。
この機能を活用することで、誰よりも早くインシデントや状態変化に対してアクションを起こすことができるので、緊急時の応急処置を即座に実施できます。
アラームは常に以下の3つの状態の中のどれかになっています。
OK:監視対象のメトリクスが閾値の範囲内で、正常な状態
ALARM:監視対象のメトリクスが閾値の範囲を超過している状態。この状態の時に自動的に設定していたアクションが実行されます(通知やLambdaの実行など)
INSUFFICIENT_DATA:メトリクスデータが不足している状態で、アラームの状態を判別できない状態です。この状態になる原因は様々ですが、リソースが停止していたり、ネットワークの問題があったりします。
アラームを構成する要素
メトリクス
何を監視するかの定義
例
EC2のCPUUtilization(CPU使用率)
RDSのFreeStorageSpace(空きストレージ容量)
ELBのHealthyHostCount(正常なホストの数)
統計
一定期間内のメトリクスデータをどのように集計するかの定義
例
・Average(平均)
・Maximum(最大)
・Sum(合計)
・SampleCount(サンプル数)
期間
メトリクスを評価するための時間の単位です。10秒から1日の範囲で設定します。
イメージとしては、「5分ごと」にCPU使用率の平均値を一つのデータポイントとして評価するといったイメージです。
閾値
正常か異常かを判断するためのボーダーの値です
イメージとしては、CPU使用率が80%を超えたらアクションを実行するとした場合、ここでいう閾値は80%になります。
評価期間 (Evaluation Period) と 評価データポイント (Datapoints to Alarm)
アラーム状態へ移行するための条件の厳しさを定義する、非常に重要な設定です。
評価期間: アラームがメトリクスを評価する直近の期間の数です。「直近3期間」のように設定します。
評価データポイント: 評価期間内で、しきい値を超えているデータポイントがいくつあればアラーム状態に移行するかの数です。「2個以上」のように設定します。
具体例:
・期間: 5分
・評価期間: 3
・評価データポイント: 2
この設定値の意味としては、 「直近3つの5分間のデータポイントのうち、2つ以上でしきい値を超えていたら、アラーム状態に移行する」になります。
ログ(CloudWatch Logs)
ログはAWS環境におけるあらゆるログデータを一元的に集約し、保存、監視、分析するためのサービスです。
AWS環境を活用したシステムの運用では多種多様なログが日々大量に生成されます。
活用例としては、アプリケーションが出力するログを保存すること等があります
これらのログがそれぞれのサーバーごとに別々で管理されていると、障害発生時や開発時のエラーの原因調査が非常に手間になると考えられます。
ログはこれらの別々で管理されているログを一つの場所に集約し、強力なツールで分析できるようにすることができます。
ログは 「ログイベント」「ログストリーム」「ロググループ」の3つの要素から構成されています。
ログイベント
ログイベントは一言でいうとログ一行分のことです。
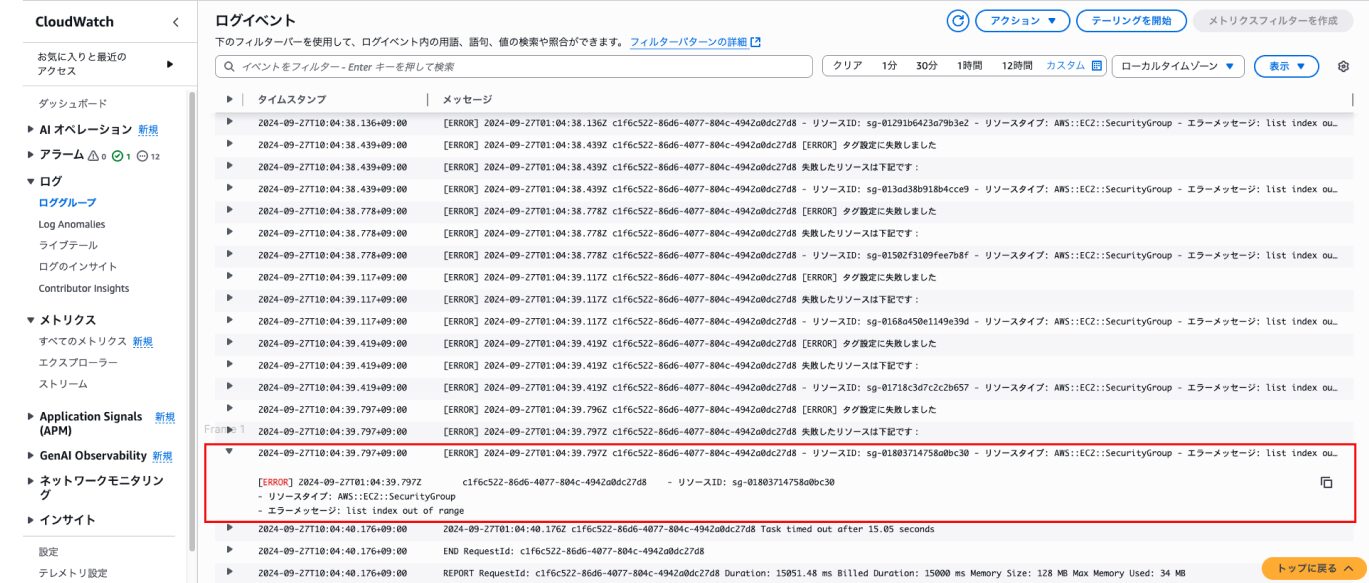
このスクリーンショットの何十行もある一つ一つがログイベントです。
トグルを開くことで、詳細なログ内容を確認することができます。この画面からログを確認することで、システム障害やエラーの原因調査を行うことができます。
ログストリーム
ログストリームは一言でいうとログの発生源ごとの入れ物のことです。
同じソースから時系列に流れ込んでくるログイベントの流れをグループ化しています。
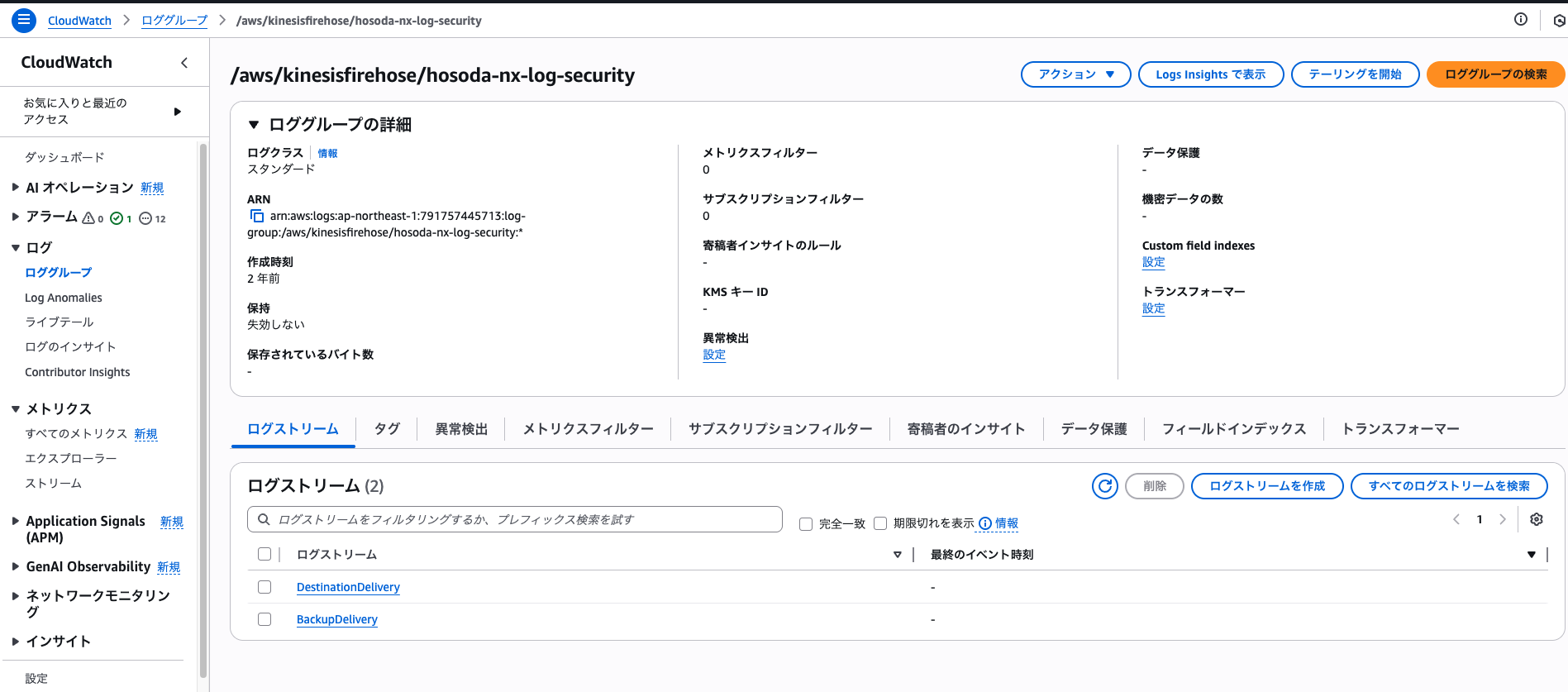
このスクリーンショットは後述するロググループの中のkinesisfirehoseというロググループの中身です。
このようにロググループの中にログストリームが存在します
ロググループ
ロググループは上記のログストリームをまとめる大きなフォルダです。
同じアプリケーションやサービスに関連するログストリームをまとめています。
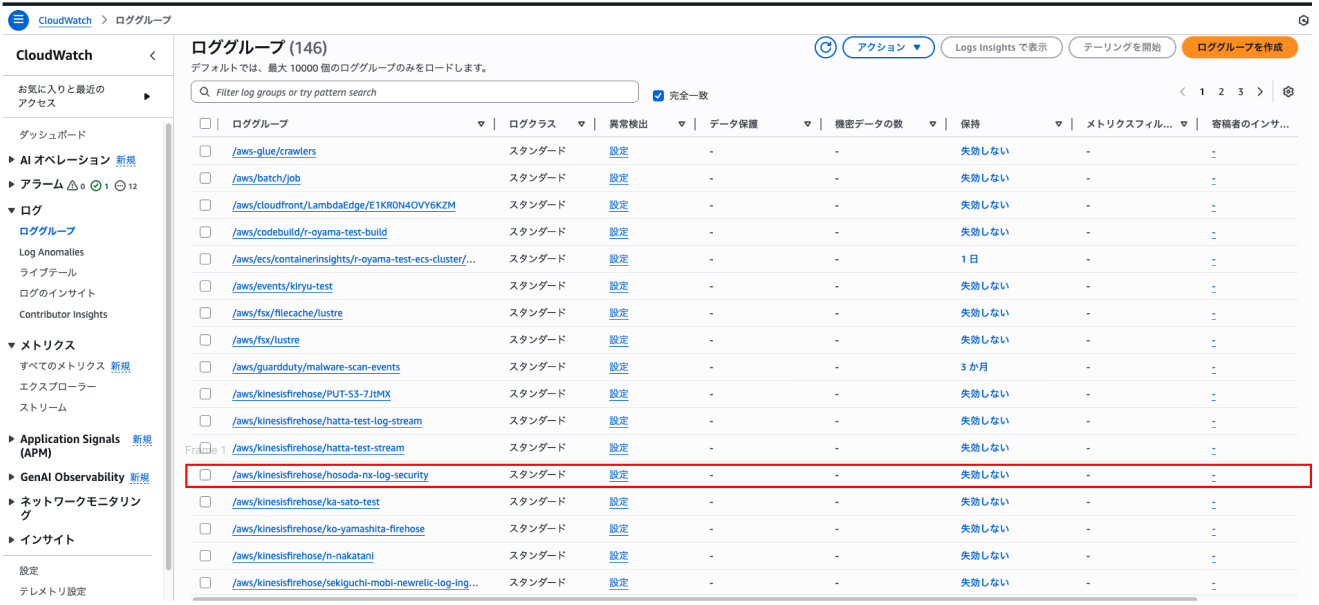
このスクリーンショットは先程説明した、ログストリームがまとめて管理されているロググループが一覧となって表示されている様子です。
赤く囲っているロググループが先程のログストリームで紹介したkinesisfirehoseのロググループです。
CloudWatchのメリット
・AWSサービスとの統合性が高い
AWSサービスの一つとして、CloudWatchがAWS上の監視を提供していることから、設定不要で監視が開始されることが一つの利点だと感じます。
例えば他の監視ツールでは、情報を取得するための「エージェント」をリソースにインストールしたり、タグ付けで情報を連携したりする設定が必要です。しかし、CloudWatchはネイティブな統合を実現しているので、そういった運用オーバーヘッドが削減されます。
・監視データの一元管理
システムが複雑になり、活用するAWSサービスの種類やリソースの数が増えたとしても、一つのコンソール上から監視データをモニタリングすることができます。
また、マルチアカウント・マルチリージョンに対応していることから、CloudWatchダッシュボードは複数のAWSアカウントや異なるリージョンにまたがるメトリクスとログを一つの画面でまとめて可視化することができる点が利点の一つだと感じます。
・自動化アクションの実行
アラームを活用することで、閾値を超えたことをトリガーに、AutoScalingやSNS通知、Lambda実行などの自動アクションを起こすことができます。
これにより、障害発生時の一次対応が迅速に行われます。こういったモニタリングだけでなく、一次対応を実現できることが、利点の一つだと感じます。
・AmazonQ developerとの統合や新しい機能の追加が進んできている
Amazon Q Developerとの統合が急速に進んでいる点が挙げられます。これにより、従来は専門知識が必要だったログの分析やメトリクスの相関関係の特定が、AIのサポートによって容易になりました。単にデータを収集・可視化するだけでなく、「データから何を読み解くか」をAIが支援してくれるため、トラブルシューティングの迅速化や運用負荷の軽減に直結します。
CloudWatchの料金
CloudWatchの料金体系は利用する機能とデータ量に応じた従量課金制になっています。
CloudWatchには下記の毎月の無料利用枠が用意されています。
- メトリクス: 10件のカスタムメトリクス、または詳細モニタリング(EC2など)メトリクス
- アラーム: 10件のアラーム(標準解像度)
- ログ: 5GBのデータ取り込み(Ingestion)とアーカイブ(Storage)
- APIコール: 100万件のAPIリクエスト
- ダッシュボード: 3つのダッシュボード(最大50メトリクス/ダッシュボード)
この無料枠を超えた分だけが課金対象となります。
メトリクス
メトリクスは種類によって料金形態が変わります。
標準メトリクス:無料
詳細モニタリングメトリクス:EC2などの詳細モニタリング(1分間隔など)を有効にすると、有効にしたメトリクス数に応じて課金されます
カスタムメトリクス:APIで自ら送信するメトリクスです。保存されるメトリクスの数とAPIリクエスト回数に基づいて課金されます
ログ(CloudWatchLogs)
ログの料金は、大きく3つの要素で構成されます。
- ① データ取り込み (Ingestion):
- CloudWatch Logsに送信(書き込み)したデータ量に応じて課金されます。
- 料金: GB単位(例: $0.76 / GB)
- ② データストレージ (Storage):
- CloudWatch Logsに保存しているデータ量に応じて課金されます。
- 料金: GB/月単位(例: $0.033 / GB-Month)
- ※ログクラス(標準、低頻度アクセス)によって単価が異なります。
- ③ データ分析 (Logs Insights):
- Logs Insightsでクエリを実行し、スキャンしたデータ量に応じて課金されます。
- 料金: スキャンしたGB単位(例: $0.0067 / GB)
アラーム(Alarms)
無料枠(10件)を超えた分のアラームに対して課金されます。料金は「解像度」によって異なります。
- 標準解像度アラーム:
- 1分間隔でメトリクスを評価するアラームです。
- 料金: アラームメトリクス 1 件あたり(例: $0.10 / 月)
- 高解像度アラーム:
- 10秒または30秒間隔で評価する、より詳細なアラームです。
- 料金: アラームメトリクス 1 件あたり(例: $0.30 / 月)
注意点
・これは2025年10月17日現在のCloudWatchの利用料金です。料金は記事を読んでいただく際には変更されている可能性がございます。ご了承よろしくお願いします。
・料金はリージョンによって異なる場合があります。
・最新の正確な単価については下記の公式ページの料金表からご確認ください
https://aws.amazon.com/jp/cloudwatch/pricing/
まとめ
CloudWatchはAWSでのシステム構築を行う際には、切っても切り離せないサービスだと思います。
なぜなら、AWSリソースを活用したシステム構築は、構築して終わりではなく、必ず監視・運用保守を行う必要があるからです。
監視・運用保守を行わなければ、システムの安定稼働を維持することはできないからです。
本記事を通して、CloudWatchを活用することによる監視・運用保守におけるメリットや仕組みについてを少しでも理解していただけたら幸いです。

