

tl;dr
昨日 Elasticsearch 勉強会がこの福岡でも開催されるということで、喜び勇んで参加したので聴講メモ等を書きました。
elasticsearch.doorkeeper.jp
まずは、勉強会を主催して下さった @johtani さんをはじめ、場所を提供して下さった LINE 福岡様に感謝を申し上げたいと思います。そして、Amazon Elasticsearch Service の話をさせて頂くことを快く許して下さった @johtani さん、本当に有難うございました!
ということで、暫く Elasticsearch を触る機会が無かったので、記憶が薄れてしまっていた部分もあったので、改めて Elasticsearch や Logstash の復習をさせて頂く機会になった。そ、そして…空気を読まずに Amazon Elasticsearch Serivce についてお話させて頂いたので、そのあたりについてもメモります。
Elastic stack の紹介 in 福岡
資料
Elastic スタックの概要
- Elasticsearch / Logstatch or Beats / Kibana
- 従来は ELK スタックと呼んでいた
- beats が追加されたことで Elastic スタックという名前になった
- 有償の X-Pack を追加するとセキュリティ、アラート、監視等の機能が提供される
Elastic Cloud
- https://www.elastic.co/jp/cloud
- AWS 上に Elasticsearch クラスタを構築する Elasticsearch as a service
- Amazon ES と似たサービス
- 従来は Found
- Elasticsearch as a service
- プラグインの利用も可能
- アップグレードも簡単
- カスタム辞書、プラグインも利用可能
- 2w のお試し期間アリ
- バージョンが上げられる
- サブスクリプションを購入するとオリジナルのプラグインをアップロード出来る
- サブスクリプションは 30 分毎に、自分でレストア出来る
- sield でアクセス制限する
logstatsh
- ログ、データの収集
- beats も同様の機能を提供する
- input / filter / output
- JRuby で実装する
- @timestamp => 取り込んだ際のタイムスタンプ => Kibana のデフォルトの日付フィールドになる
- GeoIP => IP アドレスから地域情報を判定
Elasticsearch
- 検索エンジン
- Apache Lucene ベース
- github でもバックエンドの検索で利用している
- スキーマフリー、分散ドキュメントストア、REST & JSON
- Apache License 2.0
- Query DSL
- Elasticsearch 1 プロセス = 1 ノード
— シャード
— プライマリシャード
— レプリカシャード
— シャードの移動も自由
— 同一ノードにレプリカとシャードは同居しない - 全文検索とは
— インデックス => RDB で言うところのデータが保存されている DB
— ドキュメント => RDB で言うところのデータ
— フィールド => RDB で言うところのカラム
— 単語をどのように分割しているかが肝 - N-Gram と形態素解析
— 形態素解析 → 意味のある単語の切れ目、辞書ベースなので新語に弱い
— N-Gram → 機械的に 2 文字で分割する - Analysis
— Char Filter
— Tokenizer - Mapping
— インデックスの構造を定義 - Geo
- Percolator
- Snapshot / Restore
- Aggregation
- Elasticsearch The Definitive Guide を読みましょう(英語だけど)
— guide/en/elasticsearch/guide/current/index.html
Kibana4
- Elasticsearch のデータを可視化
- Node.js / Javascript
- Marvel / Sense
- Datadog も利用している
その他の Elastc スタック
- beats
- Packet Capture(Port Capture) MySQL / Postgresql / DNS / HTTP / Redis
- libbeat
- filebeat(ログファイルを tail する)
- winlogbeat
- elasticsearch-hadoop
商用プラグイン
- Shield
— 認証(LDAP / AD / ファイルベース)
— ロールベースの ACL
— インデックス毎アクション毎、フィールド毎
— セキュアな通信
— ノード間、クライアント - Watcher
— クエリによる Watch
— アラート通知(Slack 等に通知)
— 履歴の保存→ ES に
感想
進化
ELK スタックはバージョンアップを重ね、beats 等が加わり Elastic スタックに進化し、分析プラットフォームとして一貫したシステムを提供するように進化しているように感じました。
また、そろそろ Elasticsearch と言えば…「ログ」ではなく、検索エンジンとして利用出来るようになりたいと思った次第です。後、Elasticsearch のクラスタ管理(インデックスのシャード管理、JVM パラメータ等)についても興味があるので、今後も勉強していきたいと思います。
試したい
以下のツールについては近いうちに試してみたいと思います。
- Logstash
- beats
- Elastic Cloud
おまけ
Elastic Cloud 5 minutes
Elastic Cloud をホンの少しですが触ってみました。
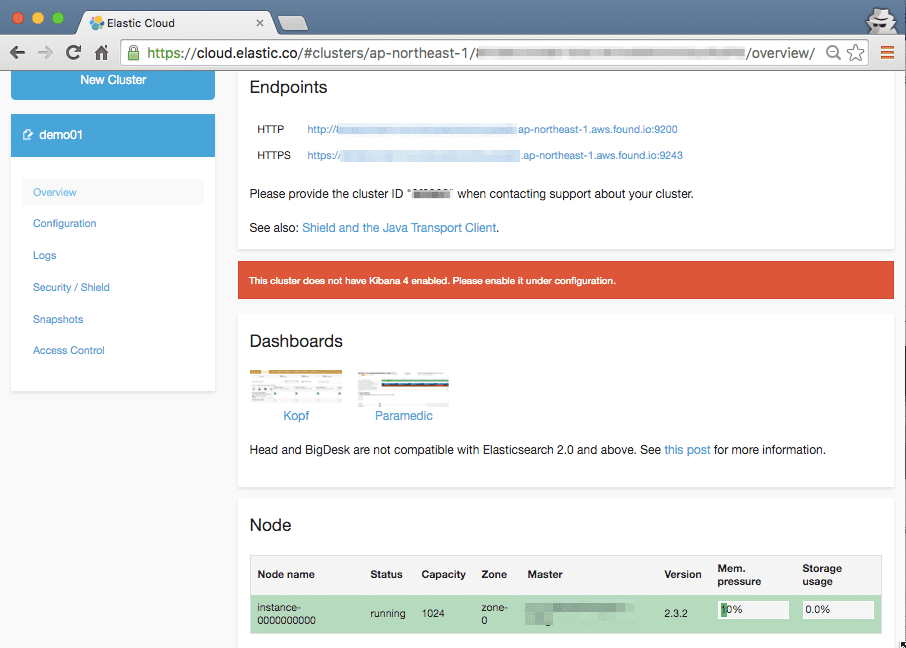
AWS の各リージョンに EC2 を起動して、任意のバージョンの Elasticsearch クラスタをわずかなステップと時間で利用出来るようになる Elasticsearch as a Serivce です。Amazon Elasticsearch Service のライバルです(笑)。
Amazon Elasticsearch Service と単純に比較は難しいと思いますが、以下のような特徴に違いがありました。
- 任意のバージョン(1.75 or 2.x 系)の Elasticsearch を選ぶことが出来る(現時点で Amazon ES は 1.5.2 固定)
- Elasticsearch API の制限は無い(Amazon ES は残念ながら利用出来ない API がある)
- プラグインはクラスタ構築時に選択することが出来る、サブスクリプションを購入することでオリジナルのプラグインをアップロード出来る(Amazon ES は残念ながらプラグインはインストール出来ない)
- アクセス制御は Shield を利用する(Amazon ES は IAM を利用する)
- Kopf や Marvel 等のクラスタ管理用ダッシュボードが利用出来る(Amazon ES は CloudWatch を利用する)
上記だけを見ると Amazon ES は Elasticsearch のバージョンが固定されているなどの注意点が必要ですが、AWS ならではの他の AWS サービスとのシームレスな連携や IAM による共通したインターフェースによるアクセス制御等、Amazon Elasticsearch Service でしか出来ないこともありますので、適宜、用途に応じて選択したいと思いました。
聴講メモ
## Elastic stack の紹介 in 福岡 ### elastic - 元々は Elasticsearch という名前だった - logstatsh / Kibana も扱う elastic ### オープンソース - Elasticsearch / Logstash / Kibana / Marvel / Sheild ### Elastic スタック - ELK スタック - beats が追加されたので elastic スタック - logstatsh と Beats が取り込み - X-Pack(有償製品) - セキュリティ - アラート - 監視 - グラフ - Elastic Cloud(https://www.elastic.co/jp/cloud) - Amazon ES と競合... ### Elastic stack によるデータ分析 - logstatsh - beats - input / filter / output - ログ、データの収集 - JRuby - 複数行等をどうするか - filter - @timestamp => 取り込んだ際のタイムスタンプ => Kibana のデフォルトの日付フィールド - GeoIP => IP アドレスから地域情報を判定 - elasticsearch - 検索エンジン - Apache ルシーン - github => バックエンドの検索で利用している - スキーマフリー、分散ドキュメントストア、REST & JSON - Apache License 2.0 - Query DSL - プロセス 1 ノード - シャード - プライマリシャード - レプリカシャード - シャードの移動も自由 - 同一ノードにレプリカとシャードは同居しない - 全文検索とは - インデックス => データが保存されている - ドキュメント => データ - フィールド => カラム - 単語をどのように分割しているかが肝 - N-Gram と形態素解析 - 形態素解析 → 意味のある単語の切れ目、辞書ベースなので新語に弱い - N-Gram → 機械的に 2 文字で分割する - Analysis - Char Filter - Tokenizer - Mapping - インデックスの構造を定義 - Geo - Percolator - Snapshot / Restore - Elasticsearch The Definitive Guide - guide/en/elasticsearch/guide/current/index.html - 検索エンジンとして elasticsearch - Aggregation - Kibana 4 - Elasticsearch のデータを可視化 - Node.js / Javascript - Marvel / Sense - Datadog も利用している - その他の Elastc スタック - beats - Packet Capture(Port Capture) MySQL / Postgresql / DNS / HTTP / Redis - libbeat - filebeat(ログファイルを tail する) - winlogbeat - elasticsearch-hadoop - 商用プラグイン - Shield - 認証(LDAP / AD / ファイルベース) - ロールベースの ACL - インデックス毎アクション毎、フィールド毎 - セキュアな通信 - ノード間、クライアント - Watcher - クエリによる Watch - アラート通知(Slack 等に通知) - 履歴の保存→ ES に - Cloud - 従来は Found - Elasticsearch as a service - プラグインの利用も可能 - アップグレードも簡単 - カスタム辞書、プラグインも利用可能 - 2w のお試し期間アリ - バージョンが上げられる - サブスクリプションを購入するとオリジナルのプラグインをアップロード出来る - サブスクリプションは 30 分毎に、自分でレストア出来る - sield で制限する - elastic.co/brand - Kibana が重いクエリを投げる - Elasticsearch 自体はキャッシュ的なものは利用していない - Kibana 5 からクエリキャッシュを有効活用 - Elasticsearch はディスクに対して検索を掛けている - 1.x から 2 にアップデート→メモリに優しくなっている - doc value を利用すると gc が起きにくい - 仮想メモリを利用しないようにする - サイジングは難しい - discuss を利用する
自分の発表
Amazon Elasticsearch Service についてお話をさせて頂く機会を頂きましたが、事前に Elastic Cloud の存在を知らなかったのが致命的でした。これは明らかに勉強不足…反省です。ただ、これを機会に改めて Amazon Elasticsearch Service について調べる機会になりましたし、Elastic Cloud というライバルにも出会うことが出来ました。
これからも Elasticsearch の理解を深めていきつつ、フィードバックが出来るようになりたいと思います。
