
ログ解析システムにもいろいろなものがあるようですが、今回はsumologicを試してみました。
sumologicはサービス型のログ解析システムです。
このサービスについて、また、ログ解析システムが何故必要とされているかは、以下AWS荒木さんのスライドが
わかりやすいです。
今までと同じようにfluentdでデータを入れ込みたいのですが、Sumologic用のPluginはないようです。
そこで、ログ収集基盤としてfluentdで統一させたい場合もあるので、今回はSumologic用のプラグインも
作ってみます。
○Sumologicへの登録と設定
まず、会員登録して、ログインします。
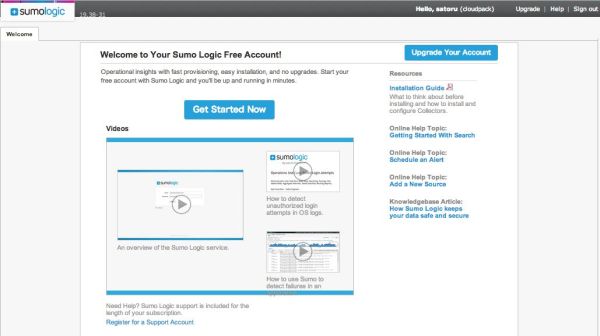
「Get Started Now」をクリックします。
次にCollectorを追加します。
Collectorはログ収集コンポーネントです。
Collectorにはログがあるサーバー側にモジュールをインストールすることもできますし、ログサーバー側で
待ち受けることもできます。
今回は後者を選択します。
「Add Collector」の画面で「Hosted Collector」を選択します。
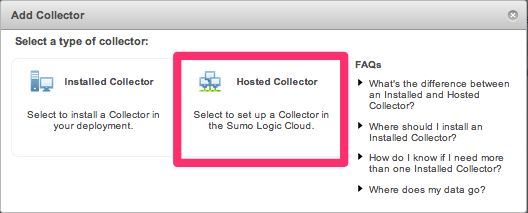
ここでは仮に「testhost」という名前で登録します。
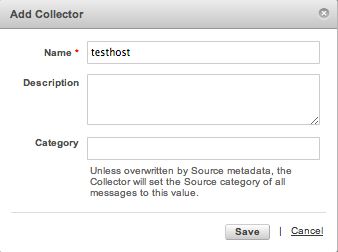
次に、作成されたtesthostの「Add Source」をクリックします。

そうすると、入力ソースの選択画面が表示されるので、S3のデータがある場合はS3の場所を設定します。
今回は、fluentでログを送るので、HTTPタイプを選択します。
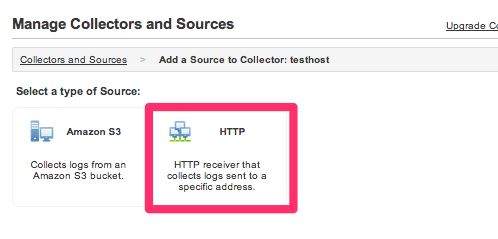
詳細な設定画面が表示されますが、とりあえずNameだけ入力して「Save」します。
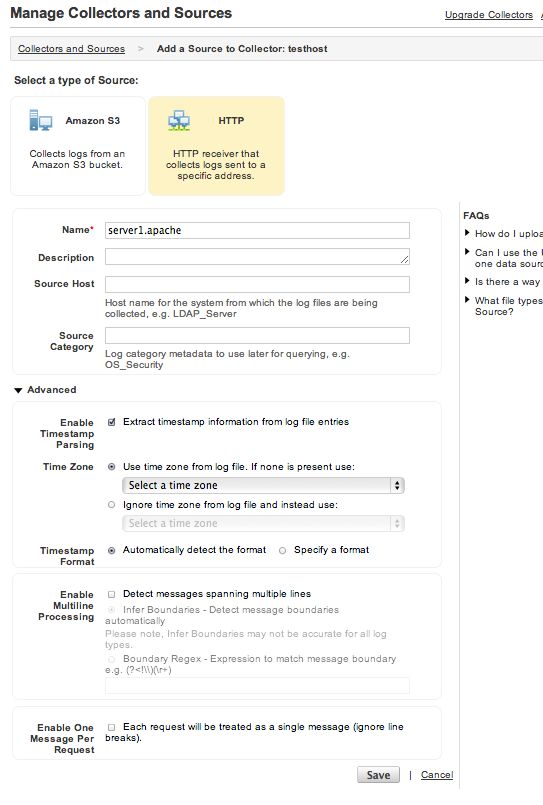
後程、fluentdのエンドポイント設定に使用するため、ソースの「Show URL」で表示されるURLを
コピーしておきます。
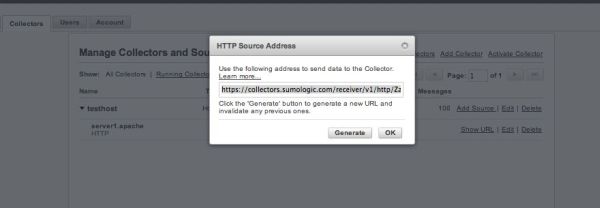
○Fluentdの設定
次に、fluentdの設定です。
sumologic用のプラグインがなかったので作ってみました。
テストコードはスタブのままです。
○fluent-plugin-sumologic
GitHub : luent-plugin-sumologic
RubyGems.org : fluent-plugin-sumologic
作成手順は、tagomorisさんの記事が非常に参考になります。
これをtd-agentにインストールします。
# /usr/lib64/fluent/ruby/bin/fluent-gem install fluent-plugin-sumologic
sumologicはjsonのパースが大変そうなため、今回は素のテキストのまま送り、プリセットのapacheフォーマットで
パースさせます。
そのため、apacheログのinputには普通のtailではなく、生のフォーマットでtailできるtail_asisを使用しました。
# /usr/lib64/fluent/ruby/bin/fluent-gem install fluent-plugin-tail-asis
次に設定ファイルです。
sumologicの設定では、host、port、pathは先程コピーしたURLを分解したものをそれぞれに設定します。
type tail_asis
format apache
path /var/log/httpd/access_log
tag server1.apache.access
type sumologic
host collectors.sumologic.com
port 443
format json
path /receiver/v1/http/XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX==
まずは、formatをjsonに設定した状態で、使用してみます。
# /etc/init.d/td-agent start
しばらくしてログが溜まっていくのがわかります。
また、ログの内容を見ると、messageがJSONになっているのが分かります。
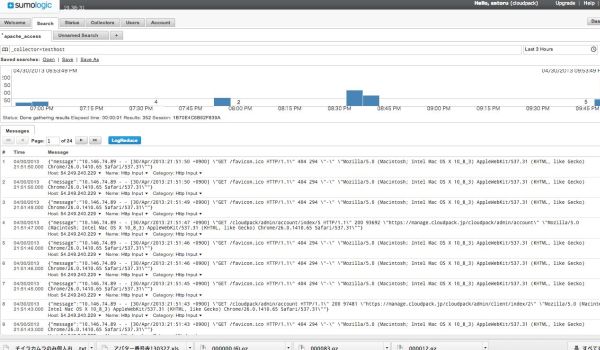
これも使い道がある場合もありますが、sumologicはJSONのパースに長い正規表現を使用しないといけない
ようなので、format textにしてみます。
type sumologic
host collectors.sumologic.com
port 443
format text
path /receiver/v1/http/XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX==
その後のログはクエリ欄に以下のように入力すると、カラム毎に項目がわかれて表示されます。
_collector=testhost | parse using public/apache/access
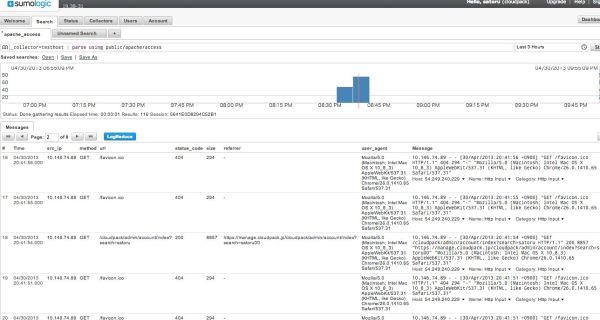
このようにすることで、集計も以下のようなクエリで簡単にレポートを作ることができます。
_collector=testhost | parse using public/apache/access | count by status_code
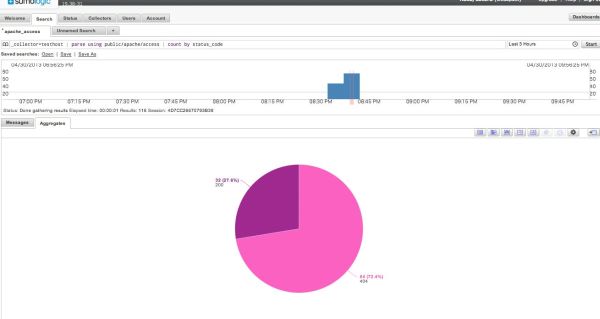
料金は、無料版は1日500MBまでで、データ保持期間は7日間、トータルで3.5GBまでのデータが保持可能です。
有償の場合は1日5GBから1TB以上までの段階型のプランで、データ保持期間によっても価格が異なります。
(→ 料金表)
あくまで無料枠での体感ですが、同じサービス型のSplunkStormよりも動作は軽快なようです。
また、Splunkと同じくユーザーとロールを追加できるのでプロジェクト毎の設定などもできそうです。
こちらの記事はなかの人(memorycraft)監修のもと掲載しています。
元記事は、こちら