
JMeter を復習し始めているかっぱです。
tl;dr
JMeter が標準で出力する CSV ログを Embulk と Elasticsearch + Kibana で可視化してみようという考察です。
参考
- https://github.com/mitchellh/vagrant-aws
- https://github.com/edtoon/vagrant-rsync-pull
- http://ecmarchitect.com/archives/2014/09/09/3932
- http://d.hatena.ne.jp/shibainu55/20090418/1240105201
- http://jmeter.apache.org/usermanual/listeners.html#csvlogformat
- http://www.embulk.org/docs/built-in.html
考察
モチベーション
- JMeter の結果の見方をちゃんと理解したい
- 結果から何が読み取れるかを把握したい
- Backend Lister を利用して InfluxDB + Grafana で可視化することも出来るけど負荷が高く、本来の負荷試験に影響が出た思い出がある
環境
以下のバージョンを利用。
% sw_vers ProductName: Mac OS X ProductVersion: 10.11.4 BuildVersion: 15E65 % vagrant version Installed Version: 1.8.1 Latest Version: 1.8.1 $ ./apache-jmeter-2.13/bin/jmeter --version Copyright (c) 1998-2015 The Apache Software Foundation Version 2.13 r1665067
構成はざっくり以下のようなイメージ。
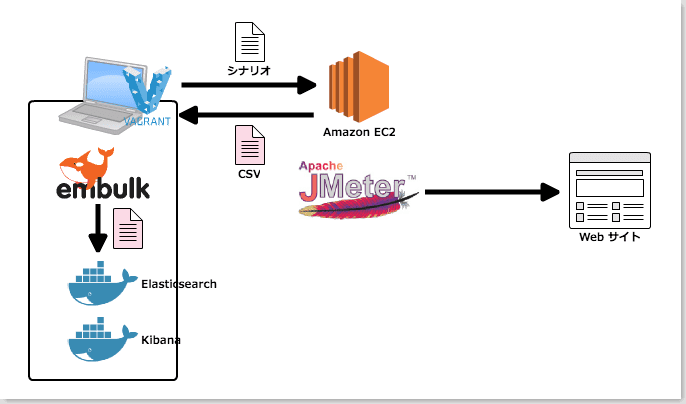
環境の構築
以下のように Vagrant を利用して JMeter を実行する環境を起動する。
#
Vagrant.configure(2) do |config|
config.vm.box = "dummy"
config.vm.box_url = "https://github.com/mitchellh/vagrant-aws/raw/master/dummy.box"
config.vm.provider :aws do |aws, override|
# aws.aws_dir = ENV['HOME'] + "/.aws/"
# aws.aws_profile = "default"
aws.access_key_id = ENV["AWS_ACCEESS_KEY_ID"]
aws.secret_access_key = ENV["AWS_SECRET_ACCESS_KEY"]
aws.region = "ap-northeast-1"
aws.keypair_name = "key-name"
aws.ami = "ami-29160d47"
override.ssh.username = "ec2-user"
override.ssh.private_key_path = ENV["HOME"] + "/.path/to/key.pem"
aws.security_groups = ["sg-xxxxxx0", "sg-xxxxxx1"]
aws.subnet_id = "subnet-xxxxxxxxx"
aws.instance_type = "t2.micro"
aws.tags = {
'Name' => 'Vagrant_EC2-01'
}
end
config.vm.provision :shell, :path => "bootstrap.sh"
config.vm.synced_folder "./jmx/", "/vagrant/jmx/", type: "rsync"
config.vm.synced_folder "./result/", "/vagrant/result/", type: "rsync_pull"
end
事前に vagrant-aws と vagrant-rsync-pull をインストールしておく。
% vagrant plugin install vagrant-aws % vagrant plugin install vagrant-rsync-pull
シナリオ作りは ruby-jmeter
シナリオは ruby-jmeter を利用して Ruby DSL で記載する。
% cat plan.rb
require 'rubygems'
require 'ruby-jmeter'
test do
threads count: 10 do
visit name: 'kome.inokara.com', url: 'http://kome.inokara.com'
end
end.jmx(file: "./jmx/plan.jmx")
以下のようにシナリオを生成する。
% bundle exec ruby plan.rb
シナリオはカレントディレクトリの jmx ディレクトリ以下に保存される。
% ls -l ./jmx total 8 -rw-r--r-- 1 username staff 3327 May 10 16:43 plan.jmx
シナリオの転送は vagrant sync を利用することでちょっと手軽に…
% vagrant rsync ==> default: Rsyncing folder: /Users/username/path/to/vagrant-ec2-jmeter/jmx/ => /vagrant/jmx ==> default: Rsyncing folder: /Users/username/path/to/vagrant-ec2-jmeter/ => /vagrant
JMeter を実行する
起動したインスタンスにログインして JMeter を実行する。
% vagrant ssh
JMeter を実行する前に結果の CSV ファイルを少しだけカスタマイズしたいので ${JMETER_HOME}/bin/user.properties に以下を追記する。
jmeter.save.saveservice.output_format=csv jmeter.save.saveservice.data_type=false jmeter.save.saveservice.label=true jmeter.save.saveservice.response_code=true jmeter.save.saveservice.response_data.on_error=false jmeter.save.saveservice.response_message=false jmeter.save.saveservice.successful=true jmeter.save.saveservice.thread_name=true jmeter.save.saveservice.time=true jmeter.save.saveservice.subresults=false jmeter.save.saveservice.assertions=false jmeter.save.saveservice.latency=true jmeter.save.saveservice.bytes=true jmeter.save.saveservice.hostname=true jmeter.save.saveservice.thread_counts=true jmeter.save.saveservice.sample_count=true jmeter.save.saveservice.response_message=false jmeter.save.saveservice.assertion_results_failure_message=false jmeter.save.saveservice.timestamp_format=yyyy-MM-dd'T'HH:mm:ss.SSSZ jmeter.save.saveservice.default_delimiter=, jmeter.save.saveservice.print_field_names=true
CSV のヘッダを出力する、タイムスタンプのフォーマットを変更する等のカスタマイズを加えている。
以下のように JMeter を起動して負荷を掛ける。
$ ${JMETER_HOME}/bin/jmeter --nongui --testfile /vagrant/jmx/plan.jmx --logfile /vagrant/result/result.csv
結果の収集
JMeter の結果をローカルにダウンロードしてくる必要があるが、これも vagrant コマンドで少し手軽に。
% vagrant rsync-pull ==> default: Rsyncing folder: /Users/username/path/to/vagrant-ec2-jmeter/result/ => /vagrant/result/ ==> default: - Exclude: [".vagrant/", "Vagrantfile"] % ls -l ./result/ total 5672 -rw-rw-r-- 1 username staff 2904000 May 10 18:09 result.csv
中身は以下のような CSV ファイルになっている。
timeStamp,elapsed,label,responseCode,threadName,success,bytes,grpThreads,allThreads,Latency,SampleCount,ErrorCount,Hostname 2016-05-10T09:08:18.858+0000,233,kome.inokara.com,200,ThreadGroup 1-1,true,4307,1,1,233,1,0,ip-xxx-xx-xx-xxx 2016-05-10T09:08:19.092+0000,27,kome.inokara.com,200,ThreadGroup 1-1,true,4307,2,2,27,1,0,ip-xxx-xx-xx-xxx 2016-05-10T09:08:19.120+0000,32,kome.inokara.com,200,ThreadGroup 1-1,true,4307,2,2,32,1,0,ip-xxx-xx-xx-xxx 2016-05-10T09:08:19.102+0000,57,kome.inokara.com,200,ThreadGroup 1-2,true,4307,2,2,57,1,0,ip-xxx-xx-xx-xxx
| csv ヘッダ | 詳細 |
|---|---|
| timeStamp | 開始時刻 |
| elapsed | リクエストを送出してからレスポンスが終了するまでの経過時間(ms) |
| responseCode | HTTPレスポンスコード |
| threadName | JMeter スレッド名 |
| success | リクエストに対して結果が返ってきたかどうか |
| bytes | 送受信バイト数 |
| grpThreads | そのスレッドグループ内でアクティブなスレッド数 |
| allThreads | 全てのスレッドグループのトータルアクティブスレッド数 |
| Latency | リクエストを送出してから最初の 1 バイトが帰ってくるまでの経過時間(ms) |
| SampleCount | サンプル数 |
| ErrorCount | エラー数 |
| Hostname | サンプルが生成されたホスト |
embulk で Elasticsearch に結果を放り込む
embulk のインストール方法等は割愛。また、 embulk-output-elasticsearch プラグインは導入済み、Elasticsearch + Kibana は起動済みという前提で…以下のような設定ファイルを作成する。
in:
type: file
path_prefix: "./result/result.csv"
parser:
type: csv
charset: UTF-8
newline: CRLF
delimiter: ","
quote: '"'
escape: '"'
null_string: 'NULL'
skip_header_lines: 1
comment_line_marker: '#'
columns:
- {name: timeStamp, type: timestamp, format: '%Y-%m-%dT%H:%M:%S'}
- {name: elapsed, type: long}
- {name: label, type: string}
- {name: responseCode, type: string}
- {name: threadName, type: string}
- {name: success, type: boolean}
- {name: bytes, type: long}
- {name: grpThreads, type: long}
- {name: allThreads, type: long}
- {name: Latency, type: long}
- {name: SampleCount, type: long}
- {name: ErrorCount, type: long}
- {name: Hostname, type: string}
out:
type: elasticsearch
index: jmeter
index_type: result
nodes:
- host: ${elasticsearch-host}
ファイル名は config.yml で保存して preview で確認
% embulk preview config.yml -b bundle
以下のように出力される。
2016-05-10 23:34:07.390 +0900: Embulk v0.8.8 2016-05-10 23:34:08.271 +0900 [INFO] (0001:preview): Listing local files at directory 'result' filtering filename by prefix 'result.csv' 2016-05-10 23:34:08.276 +0900 [INFO] (0001:preview): Loading files [result/result.csv] - |timeStamp:timestamp|elapsed:long |label:string|responseCode:string|threadName:string|success:boolean | bytes:long |grpThreads:long |allThreads:long|Latency:long|SampleCount:long |ErrorCount:long |Hostname:string| - (snip) |2016-05-10 09:08:21 UTC|40|kome.inokara.com|200|ThreadGroup1-6|rue |4,307|6|6|40|1|0|ip-xxx-xx-x-xxx| |2016-05-10 09:08:21 UTC|30|kome.inokara.com|200|ThreadGroup1-3|true|4,307|6|6|30|1|0|ip-xxx-xx-x-xxx| -
あとはよしなに可視化
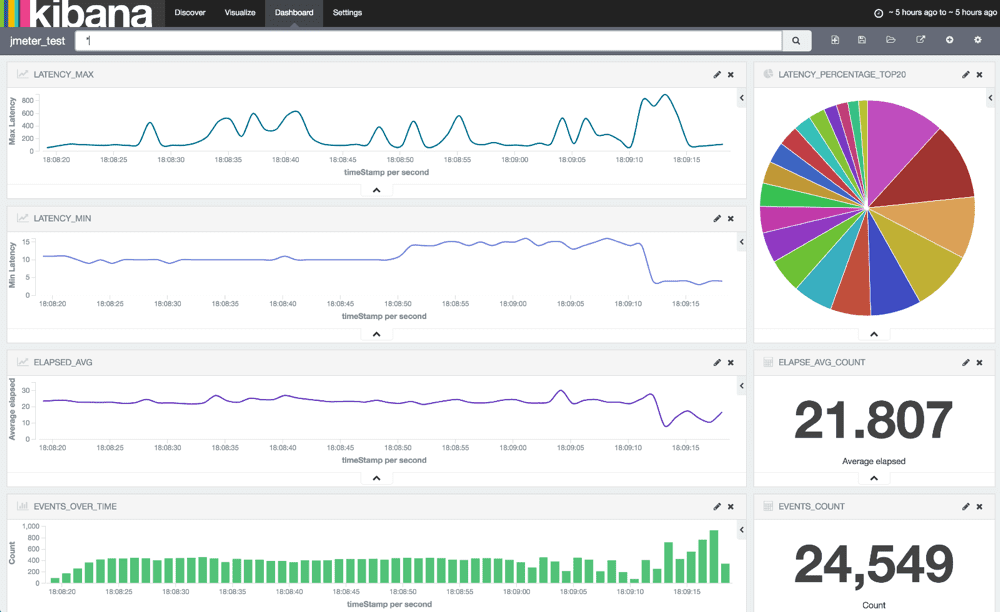
Visualize の設定を書き込んでみた。
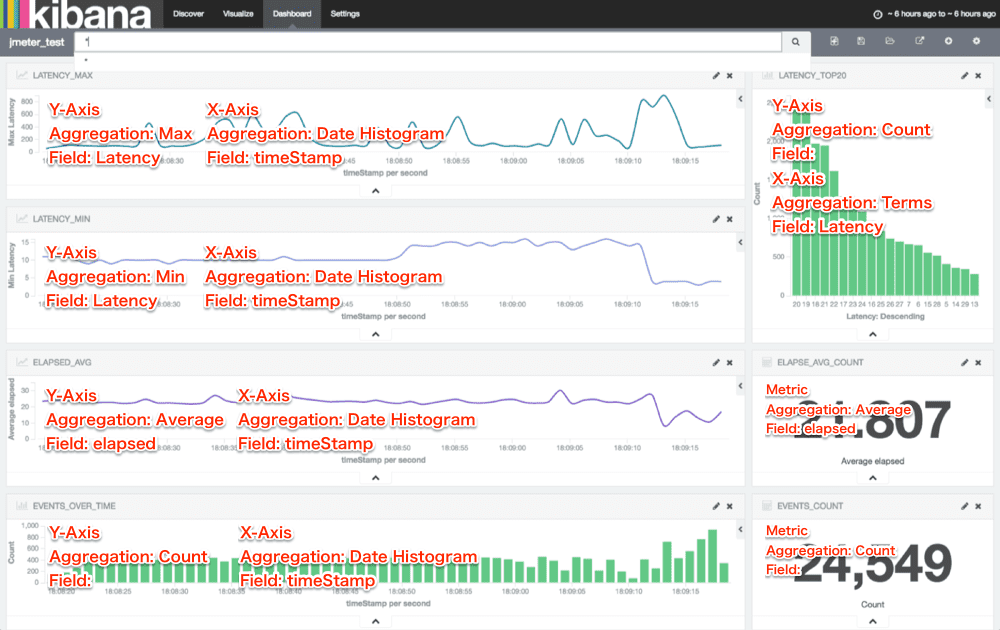
以上
JMeter の結果は csv で
なんとかなるので無理して Backend Listener とかを利用する必要は無い気がする。
embulk アリガタヤ
カラムの定義は必要になるが、それさえ頑張れば簡単に Elasticsearch に放り込めるのは素晴らしい!
Kibana をちゃんと使えれば
それなりの分析基盤になると思う(今回の考察はあくまでも「使ってみたレベル」)
ということで…
考察でした。
appendix
embulk のインストール
% curl --create-dirs -o ~/.embulk/bin/embulk -L "http://dl.embulk.org/embulk-latest.jar" % chmod +x ~/.embulk/bin/embulk % echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.zshrc % source ~/.zshrc
embulk のプラグインインストール
% embulk mkbundle bundle % vim bundle/Gemfile gem 'embulk-output-elasticsearch' % cd bundle % embulk bundle
Elasticsearch + Kibana を立ち上げる docker-compose.yml
elasticsearch:
image: elasticsearch
ports:
- 9200:9200
- 9300:9300
kibana:
image: kibana
ports:
- 5601:5601
links:
- elasticsearch
以下のように起動する。
% docker-compose up -d
元記事はこちら
「JMeter の CSV 結果を eEK Stack(embulk + Elasticserach + Kibana) で可視化する考察 」

