
以前紹介した記事「splunkってなんじゃ?(splunk enterpriseを使ってみる)」にて
splunk enterpriseを利用しましたが、今回はsplunk stormを使用してみます。
また今回はsplunkのfluentプラグインがあるので、ログをfluentでstormに投げてみたいと思います。
尚、enterpriseはインストール型でしたが、stormはサービス型となっており、
stormの無料枠は、データストレージが1GBまでとなっています。
splunk stormに登録して、プロジェクトを作ります。
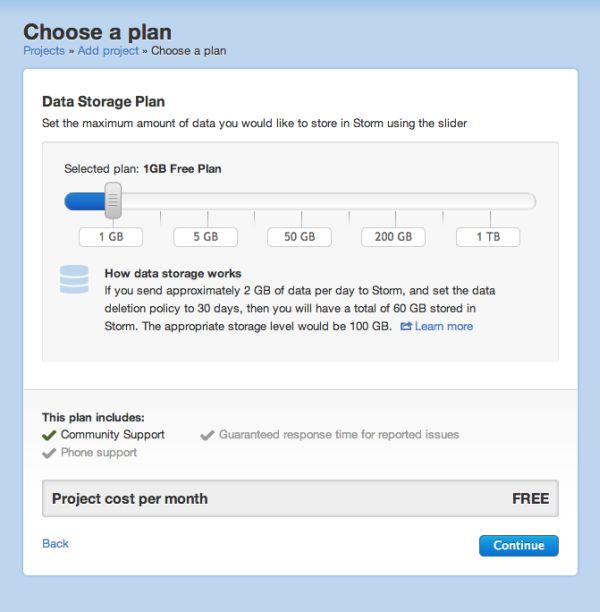
ストレージ容量を決めます。
1GBまでは無料です。
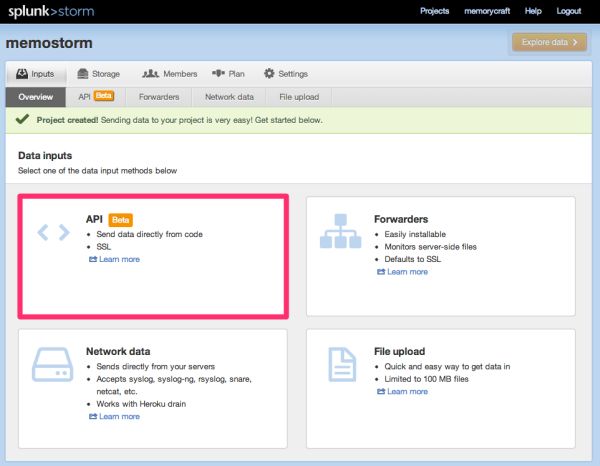
データの入力を設定します。
ここではAPIを利用するように設定します。
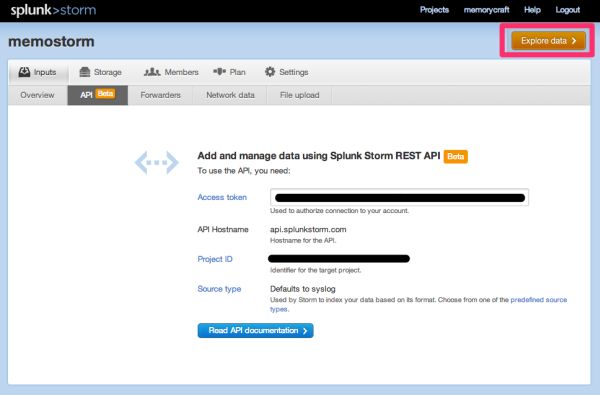
APIのリンクをクリックすると、APIの認証とエンドポイントの情報が表示されます。
- AccessToken
- API Hostname
- ProjectID
次に、fluentdの設定です。
splunkのAPIに対してログを送信するBufferedOutputプラグインを作成している方がいらっしゃいましたので、
そちらを利用してみます。
GitHub K24d : fluent-plugin-splunkapi
# /usr/lib64/fluent/ruby/bin/fluent-gem install fluent-plugin-splunkapi
ソースやドキュメントを見ながらstorm用の設定を行います。
今回もapacheのログを送信します。
# vi /etc/td-agent/td-agent.conf
type tail
format apache
path /var/log/httpd/access_log
tag server1.apache.access
type splunkapi
access_token xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
project_id yyyyyyyyyyyyyyyyyyyyyyy
protocol storm
sourcetype fluent
format text
flush_interval 10s
buffer_type memory
buffer_queue_limit 16
access_tokenとproject_idには、上述のAPIの情報画面の情報を設定します。
そして、fluentdを起動します。
# /etc/init.d/td-agent start
上の画像の「Explore data」をクリックすると、ログデータのサマリーが表示されます。
ソース欄に、fluentで設定したタグ名が表示されています。
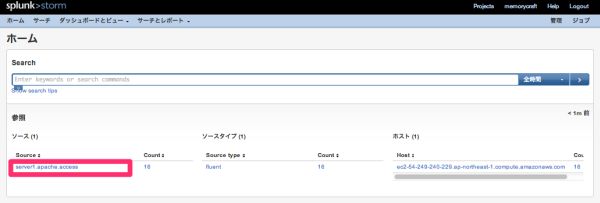
このリンクをクリックすると、収集されたログデータの一覧が表示されます。
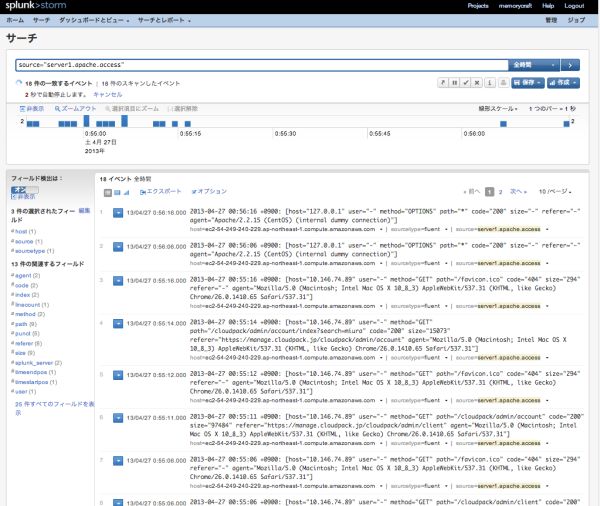
enterprise版と同様に、レポートを作成することもできますし、ダッシュボードに各種グラフを表示することも
可能です。
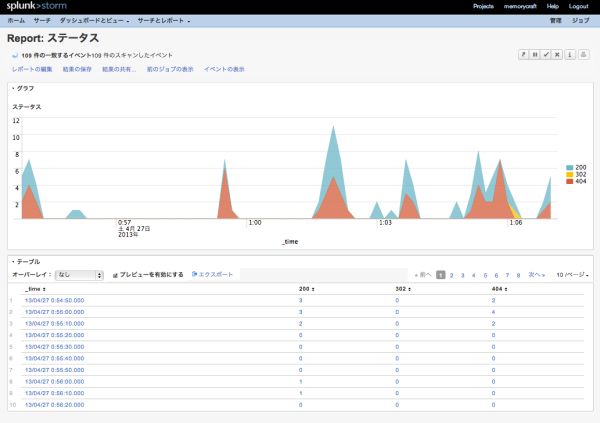
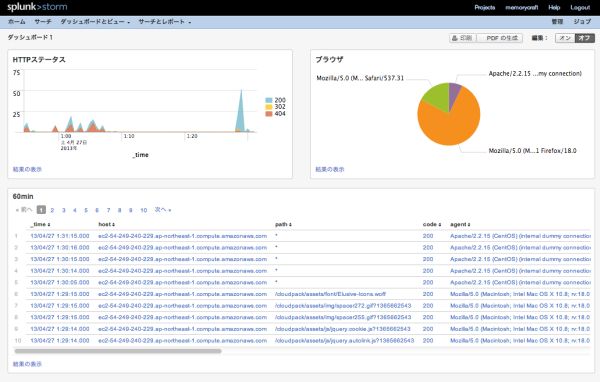
splunk stormの無料枠は1GB制限の他、1プロジェクトまでしか登録できないようです。
サービス型のためサーバーメンテナンスが必要ないのは良い点ですが、基本的に反応が鈍いです。
尚、Plan選択画面で2GB以上の有料枠に「Guaranteed response time for reported issues」と
あるので有料だとパフォーマンスが改善するのかもしれません。
自社でインフラを持つことなく、カスタマイズもあまり必要ではないという場合は、このようなサービス型の
プロダクトは有効かと思われます。
こちらの記事はなかの人(memorycraft)監修のもと掲載しています。
元記事は、こちら