
以前紹介した記事「splunkってなんじゃ?(splunk enterpriseを使ってみる)」では splunk enterpriseを
使ってみました。
今回もログ解析プラットホームである、Kibanaを使ってみます。
Kibanaは検索などにElasticsearchを利用します。
またKibanaはデータの収集にLogstashの利用を推奨しています。
それぞれ以下のようなプロダクトです。
○Logstash
ログデータを収集し、解析して保存します。
この組み合わせで使用する場合、保存先はelasticsearchになります。
○Elasticsearch
リアルタイムデータの全文検索や統計などをRestfulインターフェースで提供します。
○Kibana
データの情報を描画し、検索したりドリルダウンで情報をたどれるGUIアプリケーションです。
この3つを組み合わせて使用すると便利なログ解析プラットホームが作れるのがKibanaの売りです。
データの収集や解析を行うLogstashは、入力、フィルタ、出力のプラグインを組み合わせて使うようになっている
ようです。
こう見るとfluentdを思い出さずにはいられません。
そこでElasticsearchにfluentdでOUTできればLogstashの替わりにfluentdを使うことができ、より便利そうです。
念のため探してみたところ、elasticsearchプラグインを作っている方がやはりいらっしゃいました。
uken / fluent-plugin-elasticsearch : fluent-plugin-elasticsearch
○fluentd
ログデータを収集し、解析して保存します。
この組み合わせで使用する場合、保存先はelasticsearchになります。
そういったわけで、Logstashを置き換えられそうです。
早速インストールしてみました。
# cd ~/
# mkdir app
# cd app/
# curl -OL https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-0.20.6.tar.gz
# tar xzvf elasticsearch-0.20.6.tar.gz
# cd elasticsearch-0.20.6
# ./bin/elasticsearch -f
フロントで起動されました。
今回はこのまま使います。
別のターミナルで同じマシンにログインします。
# cd ~/app
# yum -y install gcc ruby ruby-devel rubygems rdoc
# git clone --branch=kibana-ruby https://github.com/rashidkpc/Kibana.git
# cd Kibana/
# gem install bundler
# gem install eventmachine -v '1.0.3'
# bundle install
設定ファイルを以下のように編集します。
# vim ./KibanaConfig.rb
~略~
Elasticsearch = "localhost:9200"
#Set the Net::HTTP read/open timeouts for the connection to the ES backend
ElasticsearchTimeout = 500
# The port Kibana should listen on
KibanaPort = 5601
# The adress ip Kibana should listen on. Comment out or set to
# 0.0.0.0 to listen on all interfaces.
#KibanaHost = '127.0.0.1'
KibanaHost = '0.0.0.0'
~略~
それでは起動してみます。
# ruby kibana.rb
これでKibanaとElasticsearchが起ち上がりました。
Kibanaはデフォルト5601ポートで起動するため、 http://xxx.xxx.xxx.xxx:5601/ にブラウザでアクセスします。
何もデータがないので、データを用意してみます。
データは別のサーバーからfluentdで送信します。
apacheを稼動しているサーバーでfluentdを起動し、プラグインをインストールします。
# vim /etc/yum.repos.d/td.repo
[treasuredata]
name=TreasureData
baseurl=http://packages.treasure-data.com/redhat/$basearch
gpgcheck=0
# yum install td-agent -y
次に、プラグインをインストールします。
/usr/lib64/fluent/ruby/bin/fluent-gem install fluent-plugin-elasticsearch
そして、設定ファイルを作ります。
今回は、apacheのaccess_logをtailしてelasticsearchに送信します。
# vim /etc/td-agent/td-agent.conf
type tail
format apache
path /var/log/httpd/access_log
tag server1.apache.access
index_name adminpack
type_name apache
type elasticsearch
include_tag_key true
tag_key @log_name
host 54.248.82.123
port 9200
logstash_format true
flush_interval 10s
ここで、ポイントはsourceのtagにサーバー名.apache.accessとしたことです。
matchディレクティブでtag_key @log_nameとすると、Kibanaに送られた後にこの名前で絞込みができ、
別サーバーや別のタイプのログなどと区別できます。
それではfluentdを起動します。
# /etc/init.d/td-agent start
これで準備は整ったので、このサーバーのコンテンツにアクセスしてアクセスログを発生させます。
その後、Kibanaの画面を再度確認すると
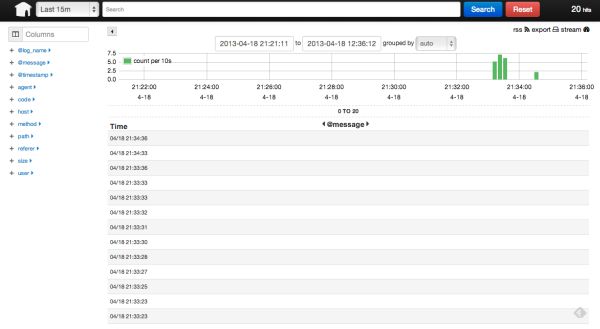
ログのデータが表示されています。
左側のペインで一覧にカラム表示する項目を+押下して選択します。
ヘッダ中央のキーワード入力欄にcode:404などとすると404レスポンスを返したログだけを絞り込めます。
また、@log_nameという項目が、先ほどのtagになるので、キーワード入力欄に
@log_name:”server1.apache.access”
と入力すると、サーバーやログの種類で絞りこまれます。
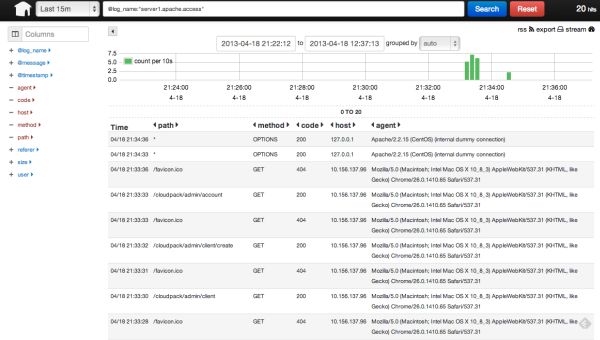
現在Kibanaは複数ログに対応する機能がないようなので、このようにしてログ毎の集計をとる形になりそうです。
やはりsplunkと比べると機能面では物足りませんが、用途によってはこれで十分な場合もありますので、選択肢の
一つとして覚えておきたいと思います。
こちらの記事はなかの人(memorycraft)監修のもと掲載しています。
元記事は、こちら