
明けましておめでとうございます!ナスです。
今年も適度に頑張って記事を書いていきます。
今日は Auto Scaling でヒヤリとしたことを書きます。
事の発端
とある作業で、Auto Scaling グループ内の EC2 インスタンスを再起動しないといけなくなりました。Auto Scaling とは関係なければ普通に再起動して終わりですが、Auto Scaling グループに入っている EC2 インスタンスを再起動すると、タイミングによっては ELB のヘルスチェックに引っかかって Terminate されてしまう可能性があります。
私がやったこと
手順は前もって調べて作業に着手したので問題はない、はずでした…
やった作業は以下の通り。
Auto Scaling グループのコンソールのインスタンスタブから、対象の EC2 インスタンスを「スタンバイに設定」にする。(もう存在しない EC2 インスタンス ID なのでモザイク無しで)
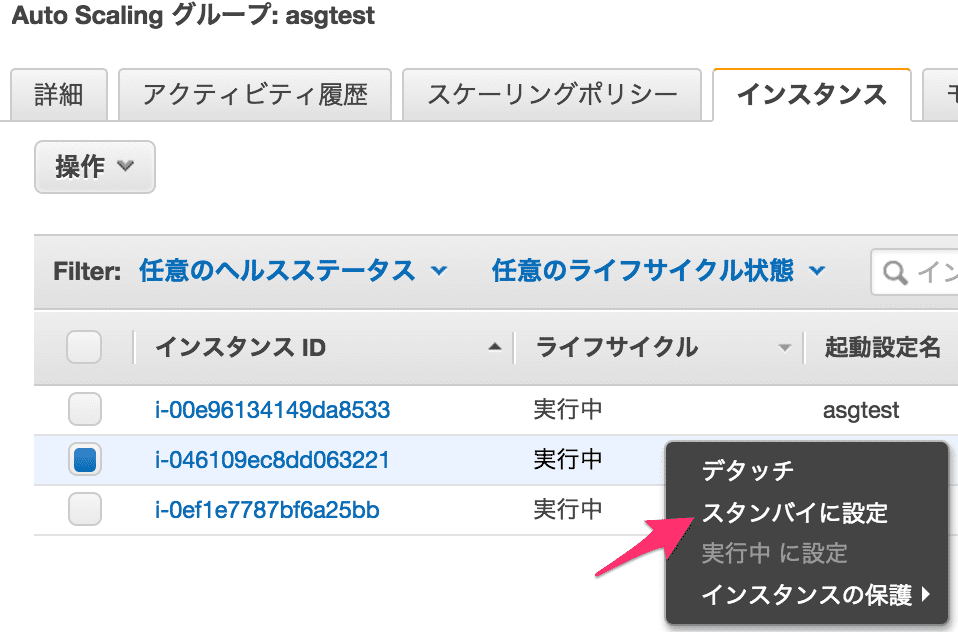
スタンバイ状態になったことを確認して、EC2 インスタンスを再起動し、再び「実行中に設定」にする。
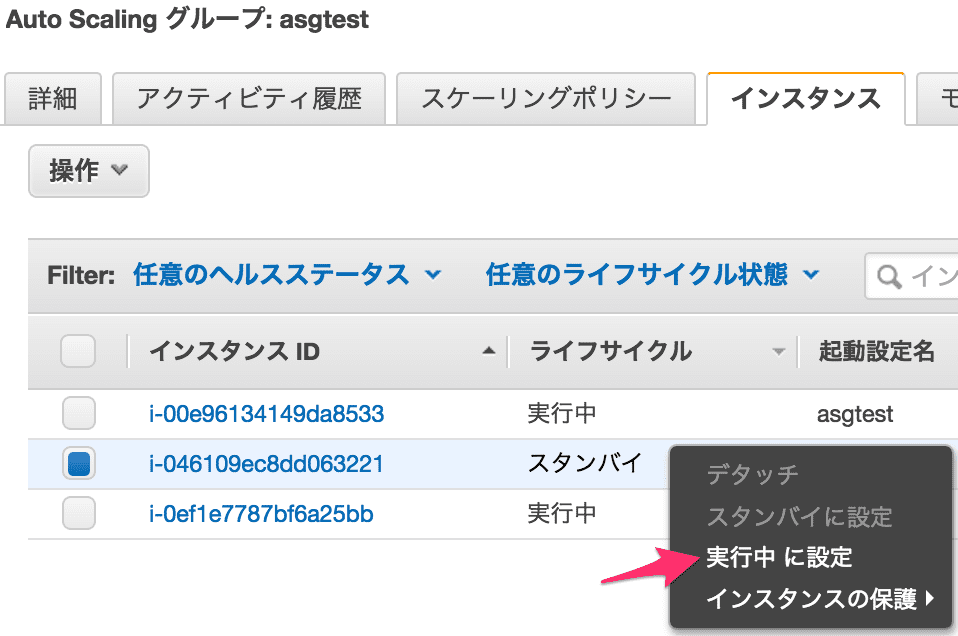
たったこれだけです。
何が起こったのか?
作業完了してしばらく Auto Scaling グループの EC2 インスタンスの1つが Terminate されました。もうちょっとしたパニック状態です。こう言うのをテンパるというのでしょうか。
原因は何だったのか?
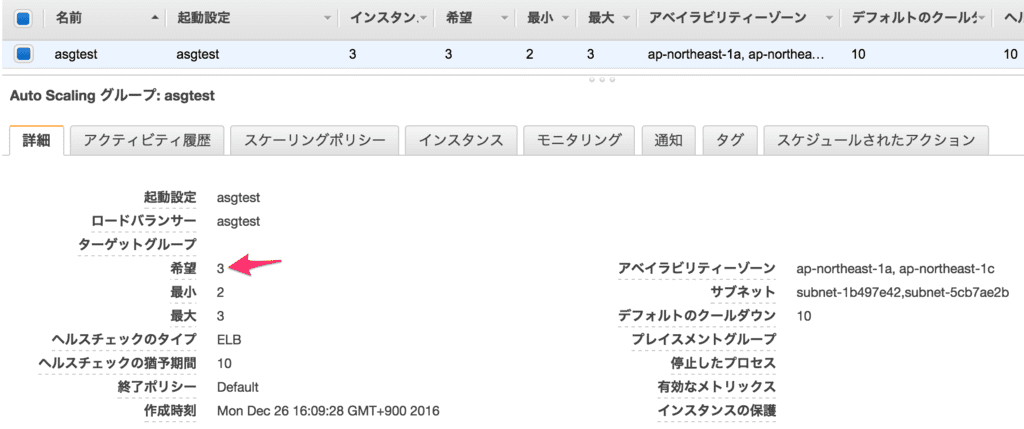
よくよく Auto Scaling グループの設定を見ると、希望インスタンス数が1つ減ったままになっていました。
スタンバイに設定すると、希望インスタンス数が1つ減らされます。下図はもともとの設定です。(もう存在しないサブネット ID なのでモザイク無しで)
スタンバイにするとこうなります。
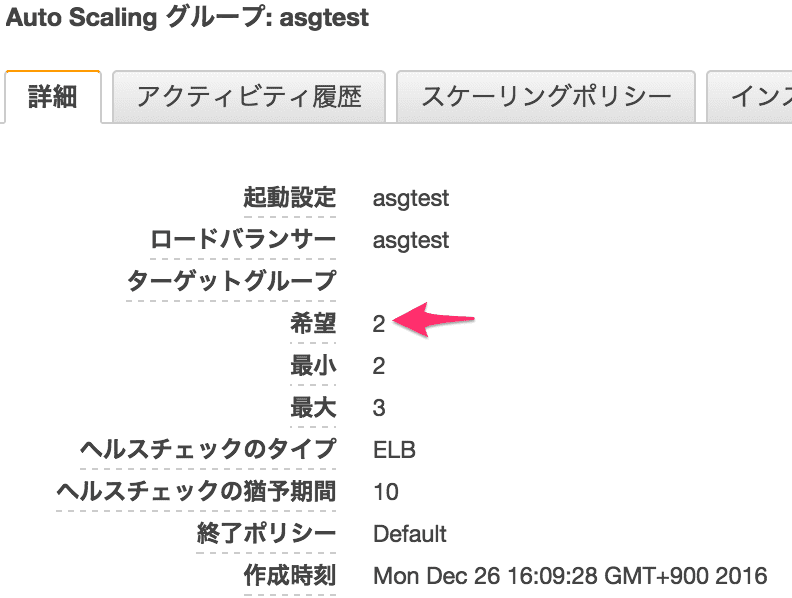
また実行中に戻すと3に戻るんですが、作業した AWS アカウントでは2のままになっていました。
そうすると、スタンバイから実行中になってインスタンスは3台になったのに、希望インスタンス数が2のままなので、Auto Scaling が1台多いなって思って余分な EC2 インスタンスを削除した、というわけです。
どうすればいいのか?
私の検証用 AWS アカウントでは同じ事象は発生しないので、何か気づいてない条件があるのか、AWS アカウント固有の問題なのか、Auto Scaling のバグなのかはわかりません。が、とりあえず暫定策として、停止したプロセスに Terminate を追加することにしました。

これで希望インスタンス数が戻らなくても、突然 Terminate されるなんてことは起こりません。
AWS のサービスがいろいろやってくれるとはいえ、過信しちゃダメなんだなと思いました。というか、同じ作業して 2つの AWS アカウントで結果が違うってなかなかキツイ…
2017.01.12 追記
続編書きました。
nasrinjp1.hatenablog.com
元記事はこちら
「Auto Scaling で EC2 インスタンスをメンテナンスする時の注意点 [cloudpack OSAKA blog]」

