
Treasure Dataはデータの収集、保存、管理、処理、可視化などを行えるログ解析の基盤サービスで、fluentdを使ってデータを収集し、hadoopで解析を行います。
自分も以前の記事で書きましたが、よくelasticsearch + kibanaや、splunkなどの部分がサービス化されているようなイメージです。
Treasure Dataについては、中の人が非常に詳しくブログで書かれています。
それでは実際に触ってみます。
ユーザー登録&ログイン
http://www.treasuredata.com/jp/products/try-it-now.php
にアクセスして、サインアップのリンクをクリックします。
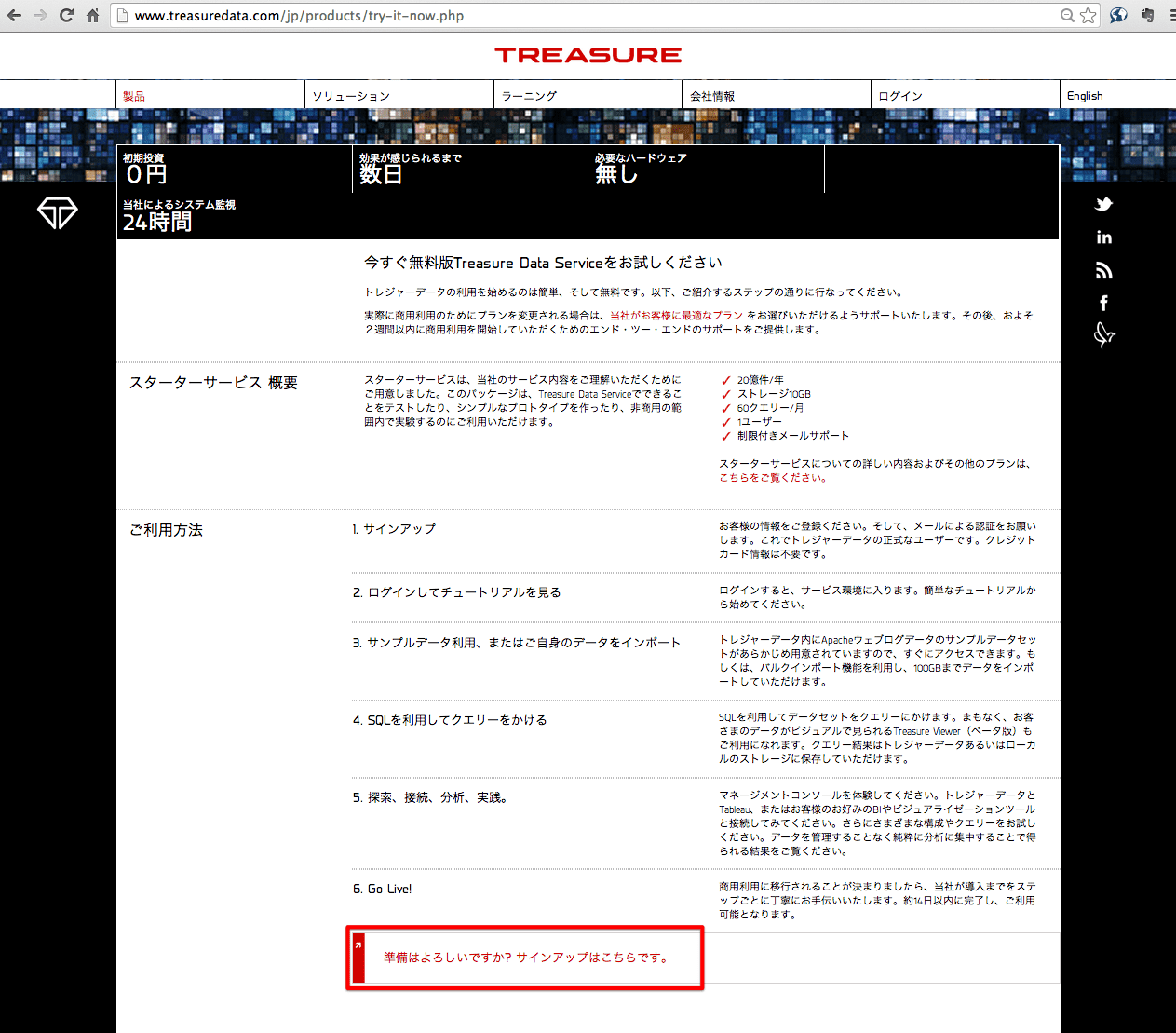
サインアップ画面が表示されるので、必要な情報を入力して登録します。
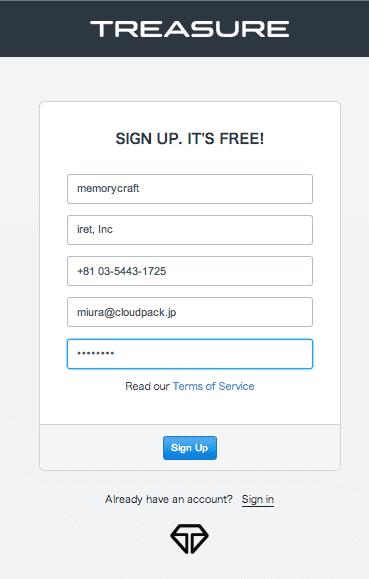
登録が終わると、確認メールが送られてくるので、確認リンクをクリックして登録完了です。
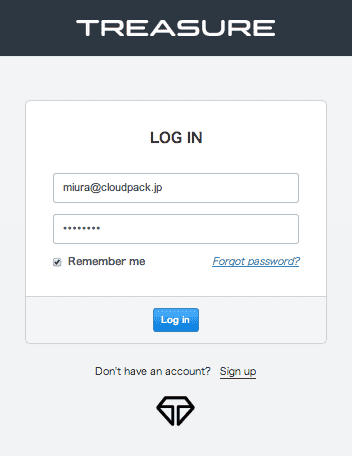
また、ログインする場合は、以下のような画面でログインすることになります。
ログの送信
ログの収集対象となるサーバーで、apacheのログデータをTreasure Dataに送信するように設定します。
まず、ログのあるサーバーでtd accountコマンドを使って先ほど登録したメールアドレスとパスワードを設定して、アカウントを紐付けます。
# td account
Enter your Treasure Data credentials.
Email: miura@cloudpack.jp
Password (typing will be hidden):
Authenticated successfully.
Use 'td db:create' to create a database.
次に、Treasure Dataに送信する時のAPIキーを取得するために、td apikey:showコマンドを実行します。
(APIキーは伏せてあります。)
# td apikey:show
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
次に、/etc/td-agent/td-agent.confで、sourceをapacheアクセスログのtailを、matchで今のAPIキーを使ったtdlogを設定します。tdlogがTreasure Dataにログを送信するためのプラグインになります。
auto_create_tableを設定しておくと、自動的にログ用のテーブルがTreasure Data側に用意されます。
type tail
format apache
path /var/log/httpd/access_log
pos_file /tmp/access.log.pos
tag td.apache.access
type tdlog
apikey XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
auto_create_table
buffer_type file
buffer_path /var/log/td-agent/buffer/td
use_ssl true
設定したら、td-agentを起動します。
/etc/init.d/td-agent start
ログ収集対象のサーバーの設定は以上です。
td tablesコマンドを使用すると、Treasure Data側で作成されたテーブルの一覧が表示されます。
# td tables;
+-----------+------------+------+-------+--------+---------------------------+---------------------------+----------------------------------------------------------------------------------------------------------+
| Database | Table | Type | Count | Size | Last import | Last log timestamp | Schema |
+-----------+------------+------+-------+--------+---------------------------+---------------------------+----------------------------------------------------------------------------------------------------------+
| apache | access | log | 26 | 0.0 GB | 2014-02-10 04:01:49 +0900 | 2014-02-10 04:00:17 +0900 | host:string, path:string, method:string, referer:string, code:long, agent:string, user:string, size:long |
| sample_db | www_access | log | 5,000 | 0.0 GB | 2014-01-30 16:43:07 +0900 | 2013-09-07 10:13:45 +0900 | host:string, path:string, method:string, referer:string, code:long, agent:string, user:string, size:long |
+-----------+------------+------+-------+--------+---------------------------+---------------------------+----------------------------------------------------------------------------------------------------------+
2 rows in set
Treasure Dataのアカウントを作成すると、デフォルトでsample_dbというデータベースが用意されていますが、ログが保存され始めると、apacheデータベースのaccessテーブルというのが作られています。
DB名、テーブル名はsourceのtagを元に作成されます。
Treasure Dataでの集計
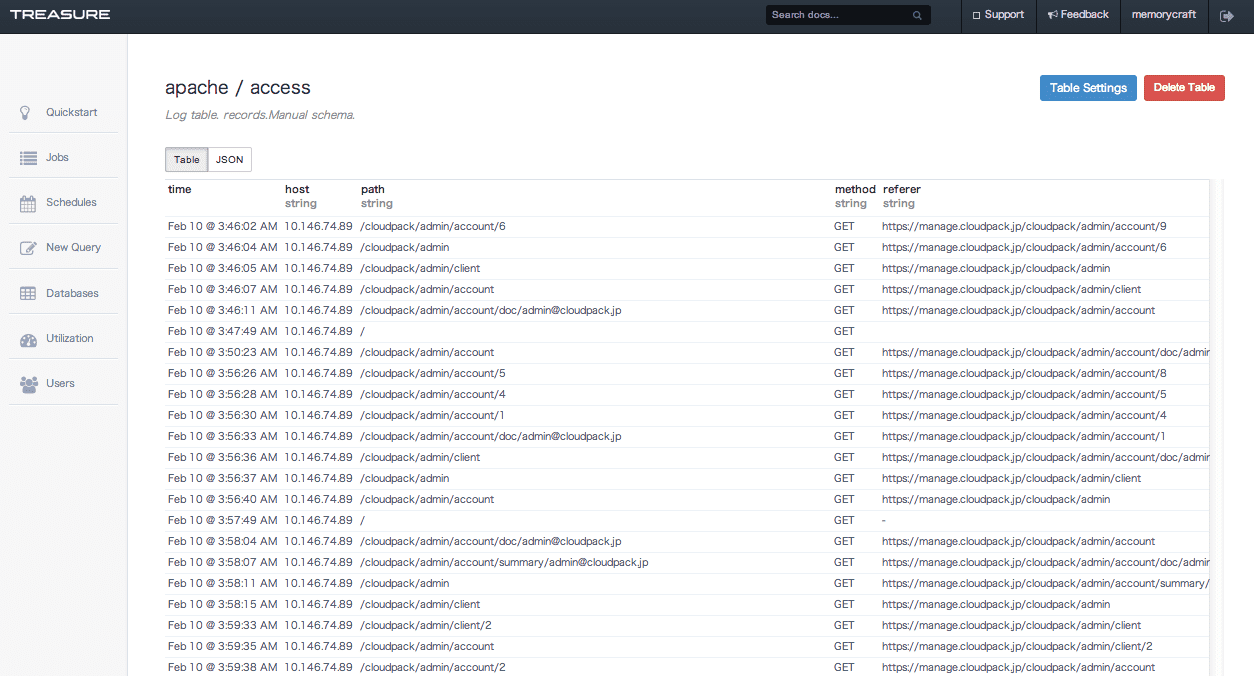
Treasure Dataの管理画面のDatabasesにも、apacheデータベースが追加されていることがわかります。
ドリルダウンしていくと、登録されているログデータが構造化されているのを見ることができます。
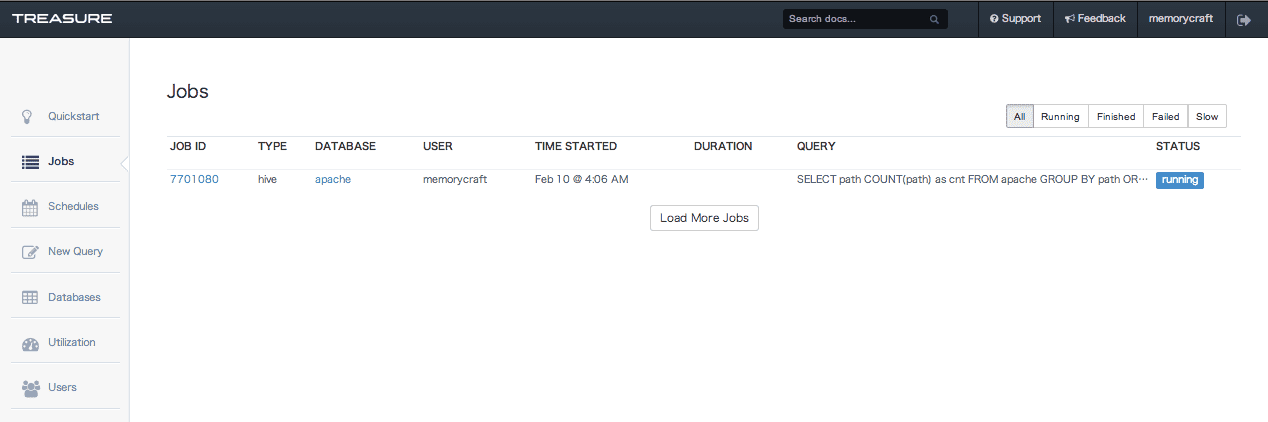
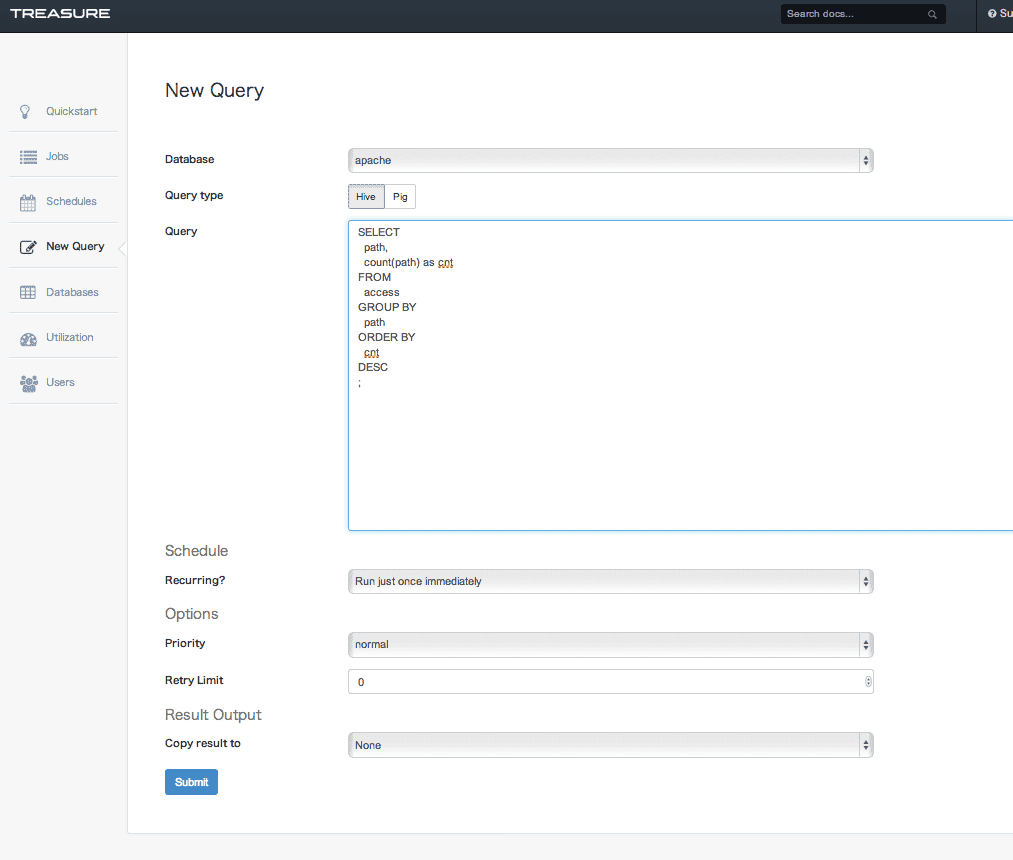
左ペインのNew Queryで集計の設定をおこないます。
データベースはapacheを選択し、今回はQuery typeはHiveを選択します。
Queryに集計するためのHiveクエリを書き、あとはそのままで「Submit」をクリックすると、Jobの実行が開始されます。Job実行はスケジューリングすることもできます。
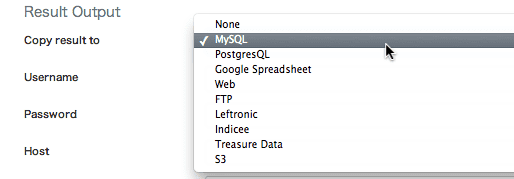
Copy result toでMySQLやS3など結果を保存する先を指定することもできます。
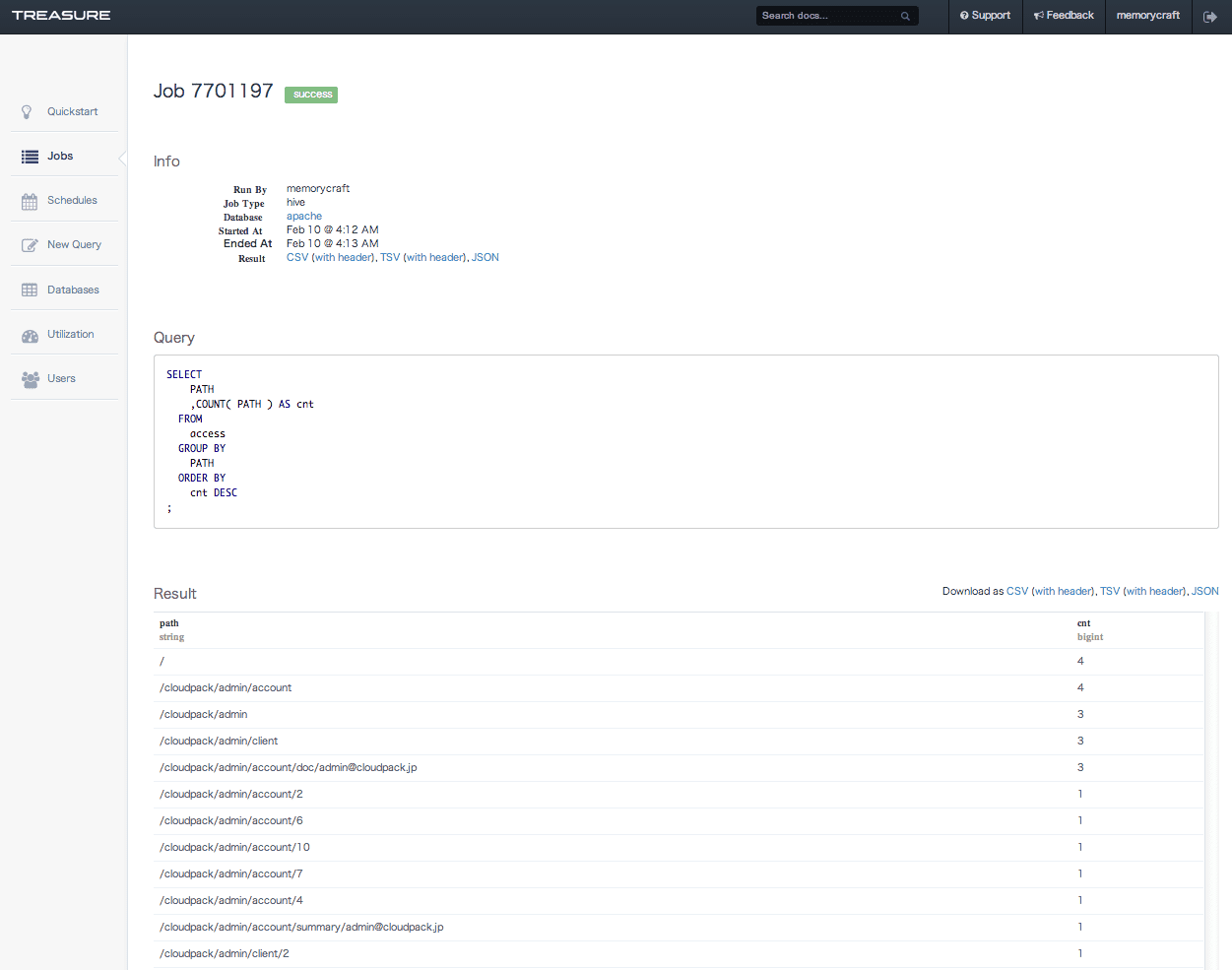
Jobの実行が終わると、Jobリストとして結果が表示されます。
今回は、結果の保存先を特に指定していないので、この結果画面にそのまま結果が表示されます。
ざっとですが、td-agentを使ったログの収集、Treasure Dataの管理コンソールでのログの確認、集計をさらってみました。
今回は以上です。
こちらの記事はなかの人(memorycraft)監修のもと掲載しています。
元記事は、こちら