
AWS Glueで自動生成されたETL処理のPySparkの開発について、AWSコンソール上で修正して実行確認は可能ですがかなり手間になります。
そこで開発エンドポイントを使って開発する方法が提供されており、Apache Zeppelinなどを使ってインタラクティブに開発することができます。公式ドキュメントによると、エンドポイントを利用して開発する方法としては大きく以下の4つの方法が提供されています。
① EC2上にApache Zeppelinを構築して開発エンドポイントへ接続
② ローカルマシンにApache Zeppelinを構築して開発エンドポイントへ接続
③ 開発エンドポイントへ直接sshしてREPL Shellを利用する
④ PyCharmのProfessional editionで開発エンドポイントへ接続
①の方法がコンソールからワンクリックで開発環境を構築することができるので簡単かつ便利に準備することができますが、EC2(m4.xlarge)が起動されるためかなりの費用がかかります。
今回は②の方法でかつローカルマシン上のDockerでApacheZeppelinを構築して開発環境を準備してみたいと思います。
手順
- 開発エンドポイントを作成
- コンテナイメージを取得
- 開発エンドポイントにsshフォワードで接続
- Apache/Zeppelinを起動&設定
- 動作確認
前提
リージョン:東京リージョン
ローカルマシン:Mac(Docker for Macインストール済み)
1. 開発エンドポイントを作成
事前に以下が対応されている前提とします
- 開発エンドポイントを作成するVPCにS3エンドポイントの作成
- Glue用サービスロールの作成
- 開発エンドポイント用のセキュリティグループの作成
- 開発エンドポイント用のssh鍵の作成
詳細は以下参照
docs.aws.amazon.com
開発エンドポイントについては、費用1DPUあたり0.44ドル/時で最低2DPUからとなりますので
できるだけこまめに消すことを想定してCloudFormationで作成します。
AWSTemplateFormatVersion: '2010-09-09'
Description: "Glue DevEndpoint"
Resources:
DevEndpoint:
Type: "AWS::Glue::DevEndpoint"
Properties:
EndpointName: "TestDevEndpoint"
NumberOfNodes: 2
PublicKey: "[ssh public key]"
RoleArn: "[Glue Service RoleのARN]"
SecurityGroupIds:
- [開発エンドポイント用のセキュリティグループ]
SubnetId: [開発エンドポイント用のサブネット]
上記を作成して保存後、コンソールもしくはcliから実行してください。
aws cloudformation create-stack --stack-name stack-dev-endpoint --region ap-northeast-1 --template-body file://dev_endpoint.yml
と思ったら、エラーが発生してうまく実行できませんでいた。
バージニアリージョンでは問題なく実行できましたので、おそらく現時点で東京リージョンではGlueのCloudFormationがまだ使えないようです。
仕方が無いのでcliで作成することにします。
以下のコマンドを実行して開発エンドポイントを作成します。
aws glue create-dev-endpoint \ --endpoint-name TestDevEndpoint \ --role-arn [Glue Service RoleのARN] \ --security-group-ids sg-866cdeff \ --subnet-id [開発エンドポイント用のセキュリティグループ] \ --public-key "[ssh public key]" \ --number-of-nodes 2
実行後しばらくしてstatusがREADYになれば準備完了です。
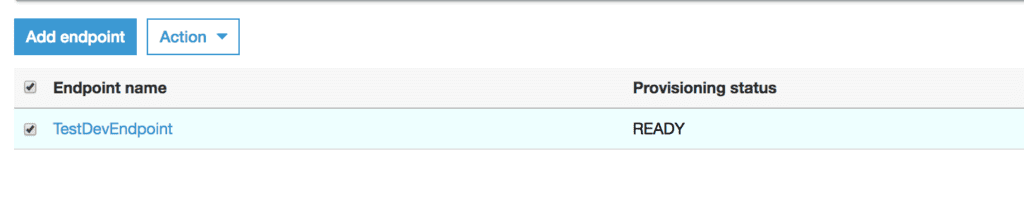
2. コンテナイメージの取得
以下のコマンドを実行してDockerHubからapache zeppelinのコンテナイメージ取得する
docker pull apache/zeppelin
3. 開発エンドポイントにsshフォワードで接続
コンソールから開発エンドポイントの詳細を開き「SSH tunnel to remote interpreter」に記載のある接続コマンドをコピーします。
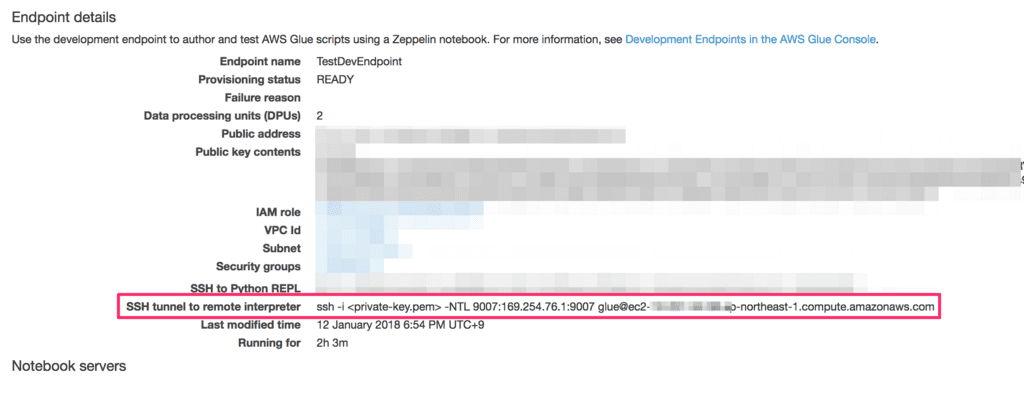
コピーしたコマンドに-gオプションを付与してMacからssh接続を行います
ssh -g -i <private-key.pem> -NTL 9007:169.254.76.1:9007 glue@ec2-xxx-xxx-xxx-xxx.ap-northeast-1.compute.amazonaws.com
※コンテナからトンネルを利用できるようにするためにgオプションを付与します
4. Apache/Zeppelinを起動&設定
docker run -p 8080:8080 apache/zeppelin:0.7.3
※タグは取得したバージョンをセットしてください
起動後以下のURLにアクセスします
http://localhost:8080.
画面右側からinterpreterを選択します
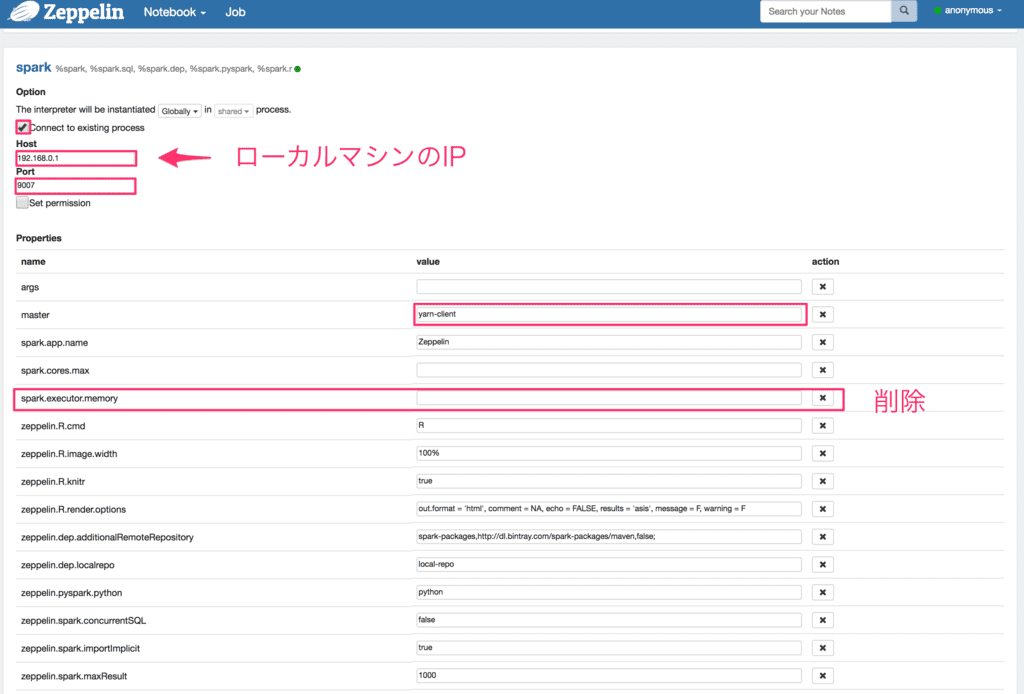
spark項目で以下のように設定します。
- Connect to existing processをチェック
- HostにローカルマシンのIP
- masterにyarn-clinet
- psark.executor.memoryを削除
設定後にrestartすれば完了です。
5. 動作確認
以下のサンプルコードを実行してスキーマ情報が出力されることを確認してください
DataBase、TableNameは実際に設定しているものを使用してください
%pyspark import sys from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.transforms import * # Create a Glue context glueContext = GlueContext(SparkContext.getOrCreate()) # Create a DynamicFrame using the 'persons_json' table persons_DyF = glueContext.create_dynamic_frame.from_catalog(database="legislators", table_name="persons_json") # Print out information about this data print "Count: ", persons_DyF.count() persons_DyF.printSchema()
これで気軽に試せる環境が整いました。
実際に使うにはコードのデータや設定データの永続化も考える必要がありますが、まずはこれで色々と試してみてください。
参考
docs.aws.amazon.com

