
ある数年分のデータがS3上に1つのファイルとして格納されている場合に、
EMRで年や月単位で分割したいという要望が一部であったため、やってみました。
例として、以下のようなCSVがあるとします。
○test.csv
2012,01,12,title1,body1
2012,01,22,title2,body2
2012,02,02,title3,body3
2012,03,01,title4,body4
2012,03,11,title5,body5
2012,03,18,title6,body6
2012,04,04,title7,body7
2012,05,02,title8,body8
2012,05,05,title9,body9
2012,06,13,title10,body10
2012,06,14,title11,body11
2012,06,29,title12,body12
2012,07,03,title13,body13
2012,07,05,title14,body14
2012,07,14,title15,body15
2012,07,30,title16,body16
2012,08,12,title17,body17
2012,09,23,title18,body18
2012,10,10,title19,body19
2012,11,23,title20,body20
2012,12,22,title21,body21
2013,01,04,title22,body22
2013,01,05,title23,body23
2013,01,06,title24,body24
2013,01,17,title25,body25
2013,01,18,title26,body26
2013,01,23,title27,body27
2013,02,03,title28,body28
2013,02,04,title29,body29
2013,02,05,title30,body30
2013,02,06,title31,body31
2013,03,03,title32,body32
2013,03,16,title33,body33
2013,04,03,title34,body34
2013,04,04,title35,body35
2013,04,09,title36,body36
2013,04,12,title37,body37
2013,04,14,title38,body38
2013,04,17,title39,body39
まず、入力用のバケットと出力用のバケットを用意します。
○入力
csv-origin(上記のtest.csvをアップしておきます。)
○出力
csv-archive (rsltというフォルダを作成しておきます。)
EMRでジョブフローを作成します。今回はインタラクティブジョブフローを使います。
これはEMRクラスタにSSHで入って、hiveコンソールで直接クエリを実行する方式です。
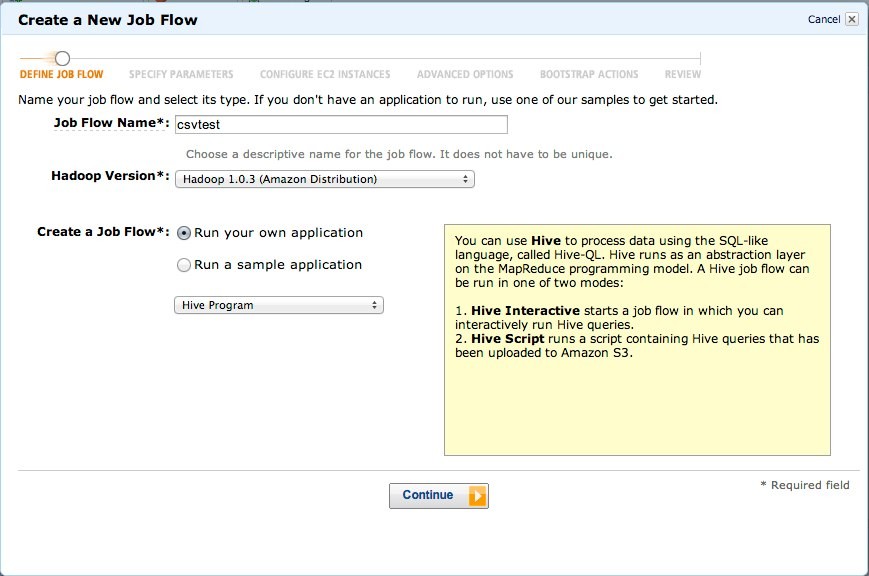
まず、EMRで「Create New Job Flow」をクリックします。
ダイアログが立ち上がるのでJob FlowにHive Programを選択します。
今回HiveScriptは使用せずインタラクティブなので、「Start as Interactive Hive Session」を選択します。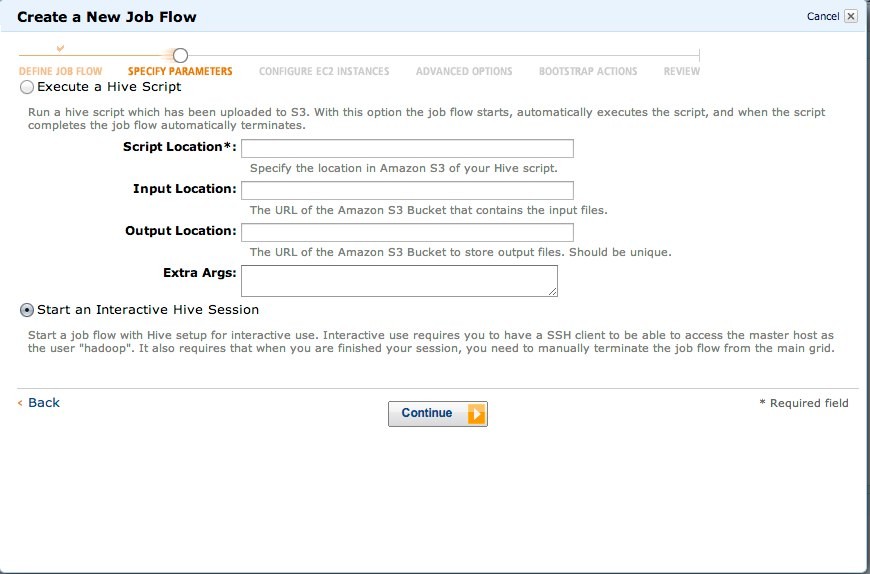
インスタンス数やサイズなどはとりあえずそのままでOKです。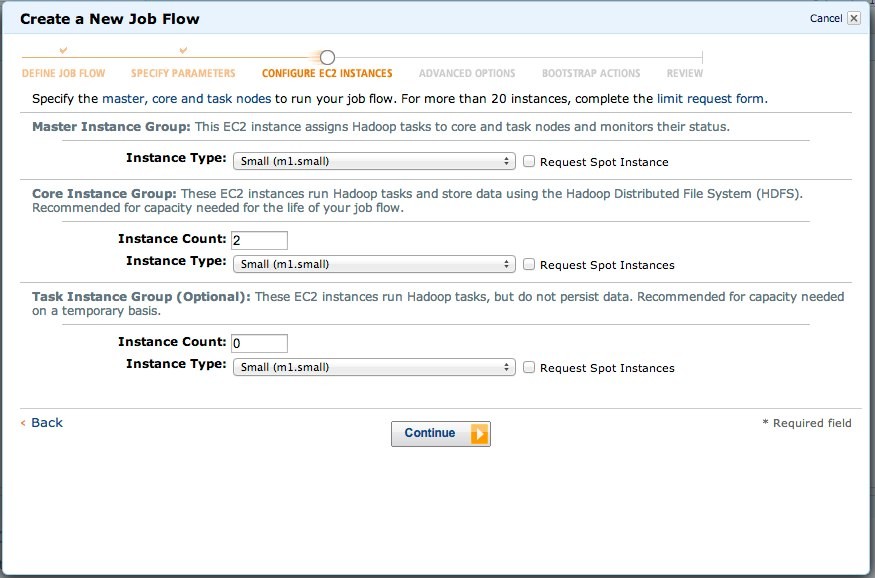
SSHでログインするときのキーを選択します。
以降はそのまま「Continue」を続けます。
すると、以下のようにジョブフローが起ち上がり、マスターノードのエンドポイントが記されます。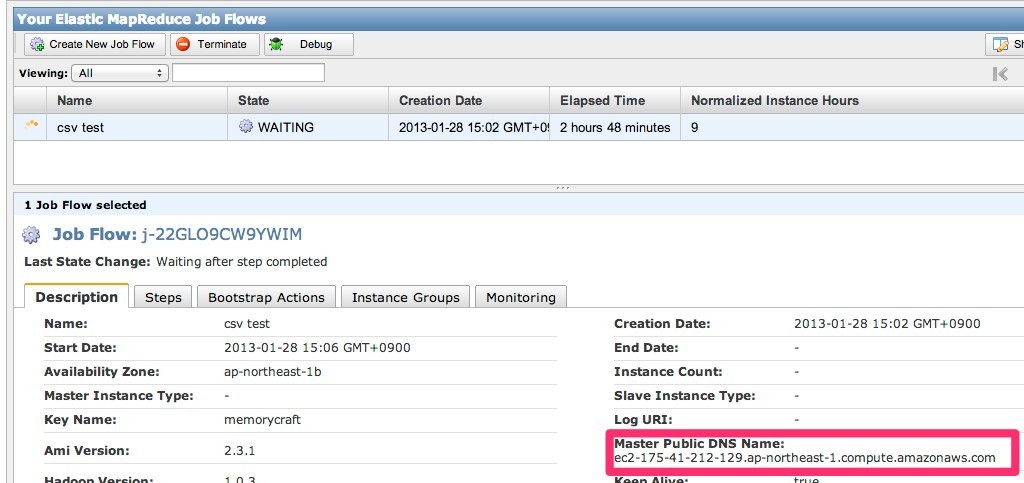
このエンドポイントに対して、指定したキーを使ってhadoopユーザーでSSHログインします。
ssh -i ./memorycraft.pem hadoop@ec2-175-41-212-129.ap-northeast-1.compute.amazonaws.com
hiveコマンドを打つとhiveコンソールに接続されます。
$ hive
Logging initialized using configuration in file:/home/hadoop/.versions/hive-0.8.1/conf/hive-log4j.properties
Hive history file=/mnt/var/lib/hive_081/tmp/history/hive_job_log_hadoop_201301280945_987980527.txt
hive>
ここでまず入力用バケットを表すテーブルを作成します。
- LOCATION句で入力用S3バケットのtest.csvのパスを指定します。
hive> CREATE EXTERNAL TABLE IF NOT EXISTS csv_origin (yyyy string, mm string, dd string, title string, body string)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY 'n'
> LOCATION 's3://csv-origin/test.csv';
次に、出力用のバケットを表すテーブルを作成します。
- 年ごと月ごとにフォルダ分けされるようにyyyyとmmでPARTITIONED BYを指定します。
- テーブルの項目にはyyyy, mm以外の項目を指定します。
- 出力ファイルがテキストファイルになるようSTORED AS TEXTFILEを指定します。
- LOCATION句で出力用S3バケットのパスを指定します。
hive> CREATE EXTERNAL TABLE IF NOT EXISTS csv_archive (dd string, title string, body string) PARTITIONED BY (yyyy string, mm string)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ',' LINES TERMINATED BY 'n'
> STORED AS TEXTFILE
> LOCATION 's3://csv-archive/rslt/';
あとはINSERT ~ SELECTなのですが、普通にやると、PARTITION(yyyy=’2012′, mm=’02’)のように
パーティションを決め打ちで指定しないといけなくなるため、DynamicPartitionというものを使います。
(通常のパーティションは別の記事で改めて書いてみたいと思います。)
DynamicPartitionを有効にするには、hive.exec.dynamic.partitionとhive.exec.dynamic.partition.mode
というパラメータをセットしつつ、以下の様な構文を使用します。
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> FROM csv_origin co
> INSERT OVERWRITE TABLE csv_archive PARTITION (yyyy, mm)
> SELECT
> co.dd,
> co.title,
> co.body,
> co.yyyy,
> co.mm
> DISTRIBUTE BY co.yyyy, co.mm;
このクエリにより、Map/Reduceが行われ、完了すると出力用のバケットに以下のようにフォルダが作成され、
それぞれのフォルダに該当データが集約されたファイルが出力されます。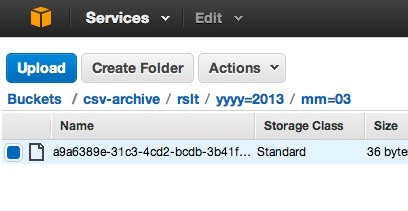
たとえば、yyyy=2013/mm=03というフォルダに出力されたファイルには
以下の様に2013/03のデータだけが記述されています。
03,titile32,body32
16,titile33,body33
無事に年月単位でデータが分割されるようになりました。
今回サンプルは数がすくないですが、
大量にバラバラなデータが入ったファイルを規則的に分割する場合はこういった方法が有効かもしれません。
こちらの記事はなかの人(memorycraft)監修のもと掲載しています。
元記事は、こちら