
Aurora Serverlessが一般リリースされましたね。みなさん色々ブログを書かれていますので流行りにのってGlueからもAurora Serverlessを利用できるか検証してみました。
検証構成
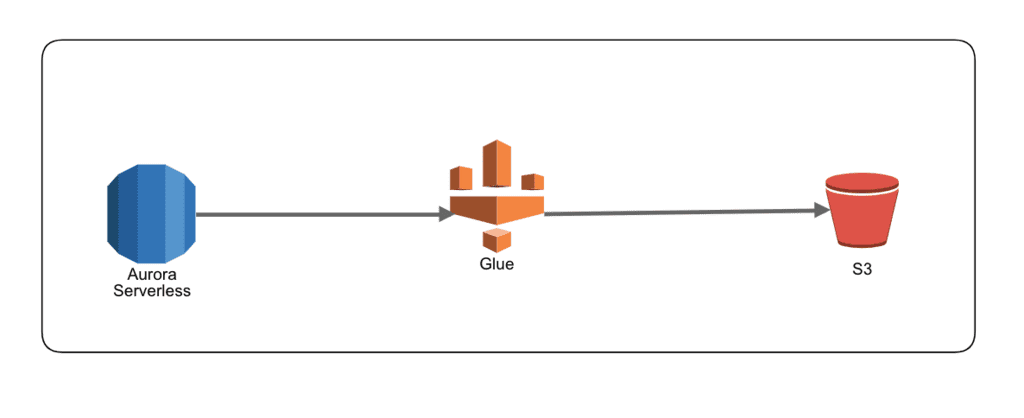
今回は上記のような構成で、Auroraからデータ取得してS3に出力してみました。
Aurora ServerlessにはMySQLで提供されているサンプルデータのworldデータベースを取り込んで試してみたいと思います。
Aurora Serverlessの準備
起動
Aurora Serverlessの起動方法は、以下のブログなどを参照して作成してください。
また、他にも色々と情報がでていますので、ググってみてください。
aws.amazon.com
データ準備
Aurora Serverlessはパブリック接続ができないようなので、VPC内にEC2を立ててそこからサンプルデータを取り込みます。
wget http://downloads.mysql.com/docs/world.sql.zip unzip world.sql.zip mysql -u ユーザー名 -p -h クラスターエンドポイント < world.sql #データが作成されているか確認。以下のテーブルが作成されていればOKです。 mysql -u ユーザー名 -p -h クラスターエンドポイント < world.sql mysql> use world; mysql> show tables; +-----------------+ | Tables_in_world | +-----------------+ | city | | country | | countrylanguage | +-----------------+
Glueの設定
接続設定
左メニューの「接続」→「接続の追加」をクリックし、以下の設定で接続を作成します。
| 接続名 | 任意(aurora-jdbc) |
|---|---|
| 接続タイプ | JDBC |
Aurora Serverlessは接続タイプ「Amazon RDS」からはまだ選択できないのでJDBCを利用します。
「次へ」をクリック
| JDBC URL | jdbc:mysql://[クラスターエンドポイント]:3306/world |
|---|---|
| ユーザー名 | Auroraで設定したユーザー名 |
| パスワード | Auroraで設定したパスワード |
| VPC | Auroraと同じVPCを設定 |
| サブネット | Auroraと通信が可能なサブネットを設定 |
| セキュリティグループ | JDBC用のセキュリティグループを作成して割当 |
確認画面で設定内容が問題ないか確認し「完了」ボタンをクリックしてください。
※上記のセキュリティグループからAurora Serverlessへ3306ポートで通信が可能なようにAurora Serverless側のセキュリティグループを設定しておいてください。
クローラー設定
左メニューの「クローラー」→「クローラの追加」をクリックし、以下の設定でクローラーを追加してください。
| クローラの名前 | 任意(aurora-serverless-crawler) |
|---|
「次へ」をクリック
| Choose a data store | JDBC |
|---|---|
| 接続 | 上記で設定した接続名を選択(aurora-jdbc) |
| インクルードパス | world/% |
「次へ」をクリック
「別のデータストアの追加」はそのままで次へ
| IAMロール | Glue用のロールを指定 |
|---|
※事前に作成していなければ、 こちらを参照し作成してください。
「このクローラのスケジュールを設定する」もそのままで次へ
「データベースの追加」をクリックし
| データベース名 | 任意の名前(world_out) |
|---|---|
| テーブルに追加されたプレフィックス | 入力しない |
入力内容を確認し「完了」をクリックします。
クローラーを実行
クローラーが作成されたらクローラーを実行します。
正常終了すると作成したデータベースに以下のテーブルが追加されているはずです。
- world_city
- world_country
- world_countrylanguage
エラーとなる場合は、Auroraへの疎通設定がうまくできていないためだと思いますのでセキュリティグループなどの設定を見直して再実行してください。
ジョブ設定
左メニューの「ジョブ」→「ジョブの追加」をクリックし、以下の設定でジョブを追加してください。
| 名前 | 任意(aurora-serverless-job) |
|---|---|
| IAMロール | Glue用のロールを指定 |
※事前に作成していなければ、 こちらを参照し作成してください。
他はデフォルトのままで「次へ」をクリック
| データソース | world_city |
|---|
「次へ」をクリック
「データターゲットでテーブルを作成する」をチェックし
| データストア | Amazon S3 |
|---|---|
| 形式 | CSV |
| ターゲットパス | 任意のS3のパス |
「次へ」をクリック
「ソース列をターゲット列にマッピングします」もデフォルトのまま「次へ」をクリック
確認画面で設定内容を確認し「ジョブを保存してスクリプトを編集する」をクリックします。
スクリプトについては特に編集は行いません。
実行確認
左メニューの「ジョブ」を選択し、上記で作成したジョブを選択します。
選択後に「アクション」メニューから「ジョブの実行」をクリックしジョブが終了するのを待ちます。
正常に実行されれば実行ステータスが「Succeeded」となりますので、S3にファイルが出力されていることを確認してください。
まとめ
実際のケースではGlueからAurora Serverlessを利用することはあまりないかもしれませんが、問題なく利用できることは分かりましたので何か機会があれば利用してみたいと思います。


