
日次でも月次でも、まず殆どのシステムで何かしらのバッチジョブというものを動かしていると思いますが、 そのバッチが確かに実行されたことを保証・監視することは結構難しいです。ジョブが起動しましたのタイミングでログを書き、終わってもログを書くとすれば、ジョブが成功したか失敗したかはわかりますが、そもそもジョブが着火すらしかなったはわかりません。*1
例えば、「このジョブが終わるとここにファイルが出ているはずだ!このDBのレコードが更新されているはずだ!」などと、そのジョブ固有の結果を観測して判定することはできますが、汎用的な手法ではありません。
私は詳しくはないですが、商用のジョブ管理ツールはそれぐらいは見てくれるのかもしれませんが、もっと簡単にこれを実現できます、しかも今風に。
Healthcheckesとは

ググりにくく、ネーミングセンスとしては最悪ですが、上記に挙げたような機能を実現するSaaSはもう結構あります。が、私が 2017年頃に一通り評価したところ、healthchecks.io に勝るものはありませんでした。
healthchecks.io
SaaSとして提供していて、価格もかなり安いのですが、OSSでも公開されており、IaaSなどで動かすことも可能です。今回はOSS版を動かします。
OSS版の動かし方
Healthchecksを選んだ理由はOSS版があることと、Python製であったことも一員です。ただデプロイ方法は結構複雑で、Djangoをそこそこわかってないと難しいです。じゃあSaaSを使えばいいんですが。。
実はこれを見つけた当初、こいつをDocker化するのは手頃でそこそこ複雑で丁度いいと思い、いつかやると心に決めていましたが、2019年の今、世界のすごく優秀な人がCoolなDocker Imageを作ってくれていました。今回はここは深く触れませんが、このイメージに気づくまで自分なりに結構な時間、試行錯誤しましたがここで得たものは大きかった。
必要なもの
ローカル環境(クライアントPC)のDocker
とりあえず入れてください。docker-compose も入れておくこと。ちなみに私のようにLinuxをDesktopとして使っている人は知っていると思いますが念の為 docker-composeはdockerパッケージに同梱じゃないです。別途いれてください。
Outbound Port 25が許可されているネットワーク
Healthchecksを使うには、メールアドレスが必要です。メールでユーザー登録するというアクションが、OSS版でも必要になります。このときに、受信できるメールアドレスはないという人は居ないと思いますが、メールを送信する機能が必要となり、OP25が遮断されているAzureやGCPでは動かせません(もちろん回避方法はあります)、AWSはOP25が許可されていますが、理由は割愛しますがおすすめしません。 OP25を切っているクライアントPCはそうそう無いと思いますが、一応。まず普段お使いの自宅用PCとネット回線を使えばまず問題ないはず
gmailアカウント
インフラの説明がメインじゃないので、SMTPサーバとしては gmailを使います。G Suiteじゃなくて無料の方でOKです。わかる人はアレンジしてください。
構築手順
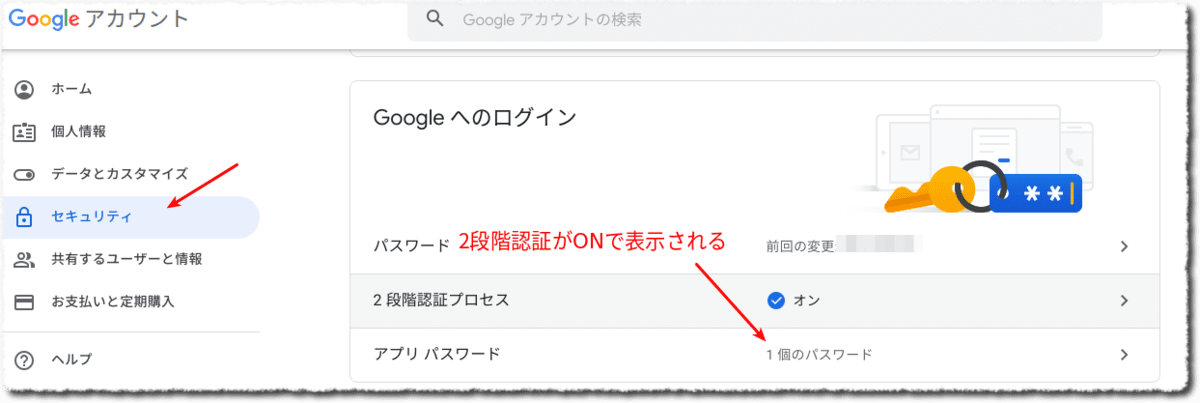
Gmail のアプリケーションパスワードを取得する
account.google.comへアクセスして取得します。2段階認証が設定されていないと取得できません。ここでアプリケーションパスワードを取得
docker pull する
飛ばしてもOKですが、Dockerイメージが玉石混在なので、イケてるやつをポイントします。
https://hub.docker.com/r/linuxserver/healthchecks
github.com
DockerHubでDownload数最大のやつはあきまへん。
docker-compose.ymlを書いて動かす
version: '3'
services:
hc:
image: linuxserver/healthchecks
environment:
- PUID=1000
- PGID=1000
- SITE_ROOT=http://localhost:8000
- SITE_NAME=test-hc
- EMAIL_HOST=smtp.gmail.com
- EMAIL_PORT=587
- EMAIL_HOST_USER=<あなたのGmailアドレス>
- EMAIL_HOST_PASSWORD=<上記で取得したアプリケーションパスワード>
- EMAIL_USE_TLS=True
ports:
- "8000:8000"
で docker-compose up -d
ユーザー登録
ユーザー登録とはいうもののSaaS版とは関係ありません、OSS版で動かしているものに対して登録が必要です。 早速http://localhost:8000/ を開きましょう そこから sign up ボタンを押して、メールアドレスを入れます。メアドは何でもOKです、composeファイルに書いたgmailのメアドでもOK。メールが届くので本文中のリンクからサクッと飛んでログイン完了。
いよいよ使ってみる
使うだけならSaaSのほうがいいかもな、とここまで書いて思いました。結構簡単になったとは思うけど、メールがやっぱ面倒だよな。。
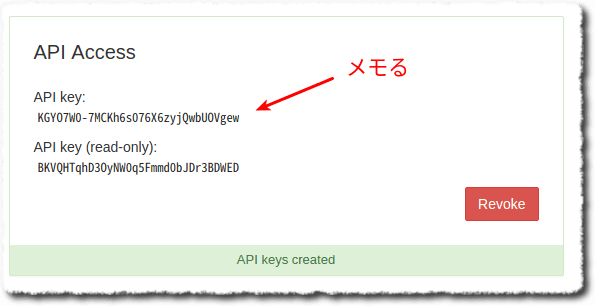
まず、APIキーを発行します。これがないとどうにもならない。
次にcheckを登録します。この処理はAPI Keyが必要です。 詳細はDocsのリンクから見てください。すぐわかると思います。timeout/grace については解ると思いますが、channels はアラート判定時もしくはOK判定時にどのIntegrationに送信するかのコントロールに使います。ここでは “*” を指定することにより、定義済みIntegration全部に対してアラート発砲します。
$ curl -H "X-Api-Key: KGYO7W0-7MCKh6s076X6zyjQwbUOVgew" \
http://localhost:8000/api/v1/checks/ \
--data '{"name": "test", "tags": "test", "timeout": 60, "grace": 60, "channels": "*"}' | jq .
{
"name": "test",
"ping_url": "http://localhost:8000/ping/8f894e90-cb77-45e7-971b-a8a8639edc68",
"update_url": "http://localhost:8000/api/v1/checks/8f894e90-cb77-45e7-971b-a8a8639edc68",
"pause_url": "http://localhost:8000/api/v1/checks/8f894e90-cb77-45e7-971b-a8a8639edc68/pause",
"tags": "test",
"grace": 60,
"n_pings": 0,
"status": "new",
"channels": "81281b62-2619-42e2-84fc-8ae2801659c9",
"last_ping": null,
"next_ping": null,
"timeout": 60
}
ブラウザでchecks一覧を確認するとこんな感じ
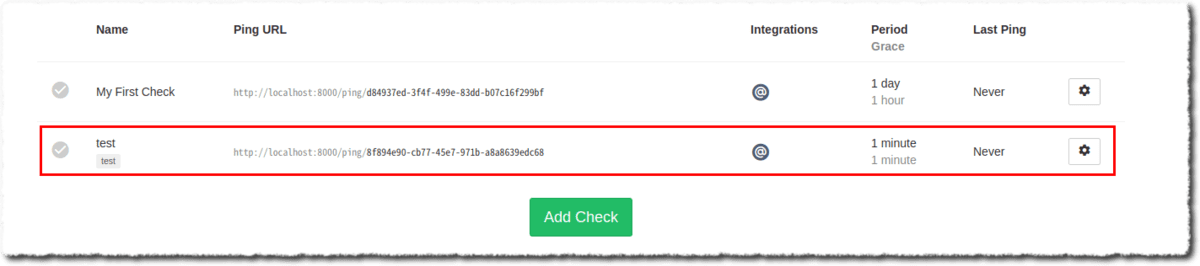
上のHTTPリクエストの戻りにあるping_url を叩きます。こちらは API-Keyは不要です。
curl http://localhost:8000/ping/8f894e90-cb77-45e7-971b-a8a8639edc68
そうすると下記のようにWebインターフェースに表示されます。
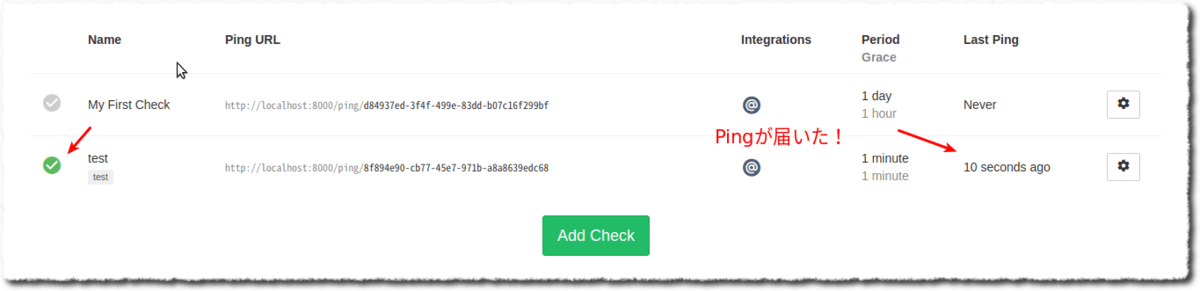
このまま timeout および grace の時間が経過する2分経過まで放置しましょう。そうすると
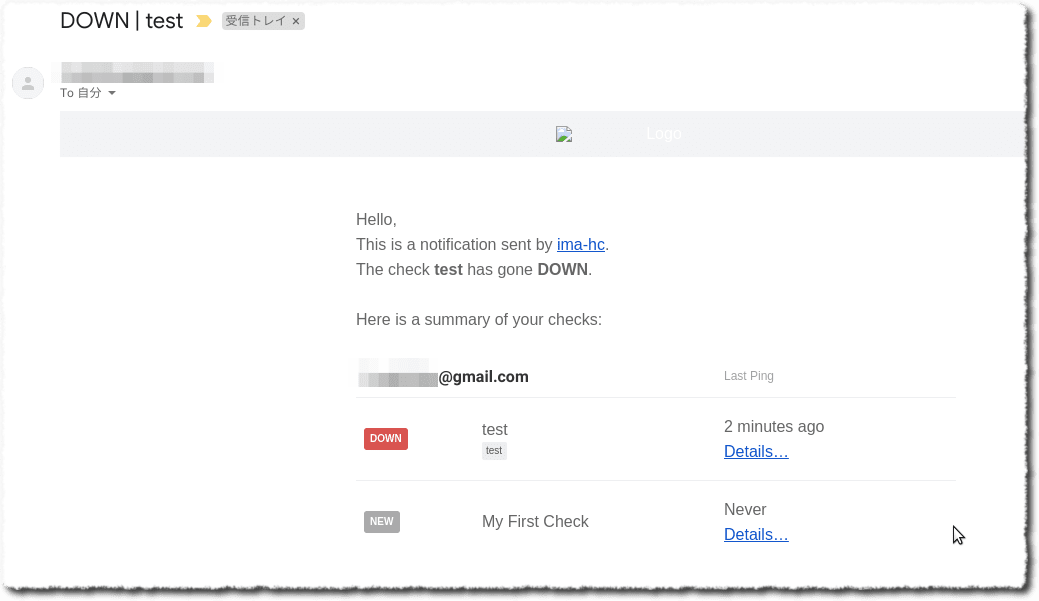
アラートが発砲されました!
実践でどう使うのか
順番が逆になりますが、そもそもこれをどう実践で使うかについて。 具体的にバックアップジョブを監視したいとします。仮にこれは1日1回、昼の12時に実行しているとします。このジョブの実行方法自体は変わりません、CronならCronで他のJob管理ツールならそれで良いです。変更するのは、バッチジョブ完了時に ping_url を叩くだけです、http(s) クライアントであれば何で叩いてもOK。
Healthcheckの動きに準じて説明します
1.ジョブの定期実行頻度など仕様にあわせて check を create する APIを叩きます。timeout: 1 日 grace: 半日などで
2. ping_url が払い出されるのでメモる
3.バックアップジョブの処理の最後に ping_url を叩く
4.仮に次の日にバックアップジョブが走ったら、そのpingからまた1日延長(猶予)される
5.その次の日にもしもバックアップジョブが失敗したら・それどころか何かが原因でcronすらコケていたら1日と半日経過した時点でアラート発砲
優れている点
なんと言ってもAPIで全部完結している点です。AutoScalingなどでインスタンスが複数立ち上がったり消えたりする、それらすべてで定期実行ジョブがあるのを見張るとなったとき、
- 起動(Scale-Out)時に監視対象として追加する
- 削除(Scale-In)時に監視対象から削除する
までを簡単にコントロールできる点です。その他Integration(= alart の発砲先)の多さ・グループ機能・タグ付けなど これぐらい常識だよねな機能は全部入っています。まあ、四の五の言わずに使えばわかります、それぐらいシンプルです。
感想
汎用的な手法で、この「ジョブは確かに実行された」を保証するには、必ず何らかの外部の観測者が必要となります。ジョブが走るサーバで自己完結してしまうとこの主題である「そもそも着火してないやん!」を見つけることはできない。この観測者の実装ですが、簡単そうで意外と難しい。
類似するSaaSは実は結構ありますが、私が数年前に一通り使ったところ healthchecks が最善手でした。他のものはAPIでのコントロール域が狭かったり、柔軟性が乏しかったり。
そもそも、第一感として、こんなのサーバーレスでやればいいやん! だったんですが、NG判定時に即座にアラートを飛ばすことが重要なのでDaemon化が必ずどこかに必要、よってコスト度外視しない限りサーバーレス(FaaS)での実装は理論的に無理。
あと、インフラについてですが、上で紹介したDockerイメージ(のDockerfile)はかなり良いです。勉強になるので興味がある人は見てみて。インフラ視点だと実は結構難しいことがわかり、気付きもたくさんあったので、そのうち書くかもしれない。
*1:ログの突き合わせをやるにしても、さらに定期実行ジョブを足すことになり、またそのジョブがちゃんと着火したかを誰かが見張らなければならないという無間地獄に陥ります。

