
演習3: Lambda + S3 バケットのread/write
- 1. はじめに
- 2.演習3 Lambda+S3のステップ1
— 2.1. 概要
— 2.2. システム構成
— 2.3. 構築してみる
— 2.4. テストしてみる - 3. 演習3 Lambda+S3のステップ2
— 3.1. 概要
— 3.2. システム構成
— 3.3. 構築してみる
— 3.4. テストしてみる - 4. 演習3 Lambda+S3のステップ
— 4.1. 概要
— 4.2. システム構成
— 4.3. 構築してみる
— 4.4. テストしてみる - 5. おさらい
— 5.1. バックナンバー - 6. 参考資料
はじめに
- Lambdaは、AWSが提供するサーバーレスのコンピューティングサービスです。前回に引き続き、Lambda を基礎から学習するための演習を発信します。Lambdaを初めて使う方は、演習1からお読みください。
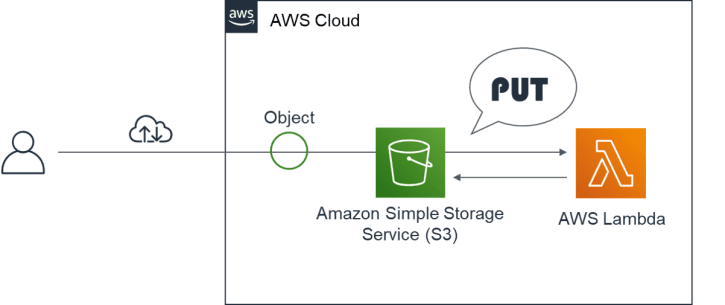
- 今回の演習は、Lambda のトリガにS3 イベントを使用します。今回のゴールを説明します。S3 バケットの指定フォルダにオブジェクトがアップロードされたら、S3 のイベントをトリガにLambdaが起動します。そして、アップロードされたオブジェクトからパスワード付きの暗号化ZIP ファイルを作成して、S3 バケットの別フォルダへアップロードする処理を行います。
- 初めて、LambdaからS3 へアクセスする方を想定して、ステップ1~3と順を追って理解を深める内容としております。ぜひ楽しんで、学んでください。
演習3 Lambda+S3のステップ1
概要
- ステップ1は、S3 バケットの “test1″フォルダにオブジェクトがアップロードされたらLambdaが起動し、イベントから取得したバケット名、キー名をCloudWatch Logs に記録するだけの処理です。S3のキー名とは、バケット内でオブジェクトを一意に識別するためのパスとオブジェクトの名前を表します。
- 前提条件として、事前にLambdaの実行ロールを準備します。ロールには、下記のポリシーをアタッチします。
- AWSLambdaBasicExecutionRole
- AmazonS3FullAccess(ステップ2,3 で使用)
システム構成
- 本演習のシステム構成は、下記の通りです。あらかじめ、S3バケットおよび “test1″フォルダを作成しておきます。
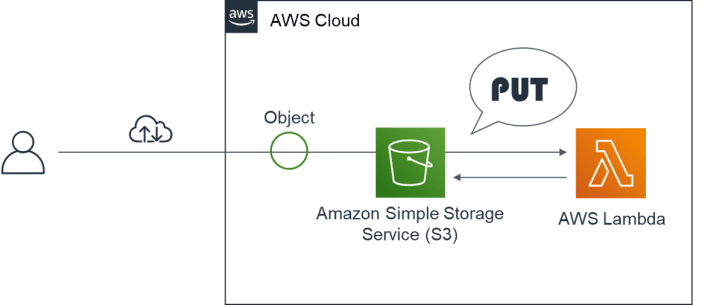
構築してみる
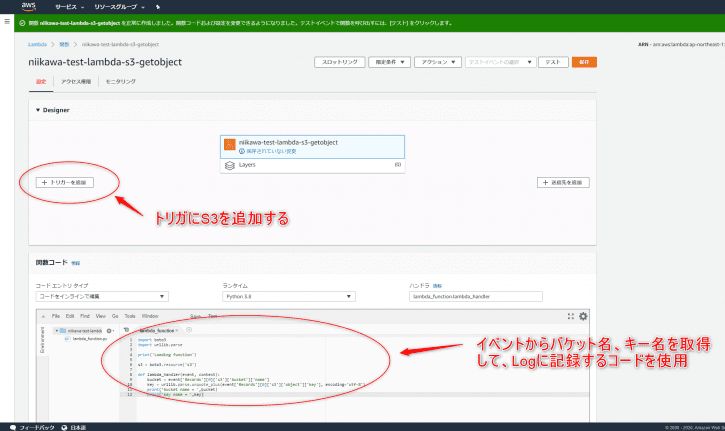
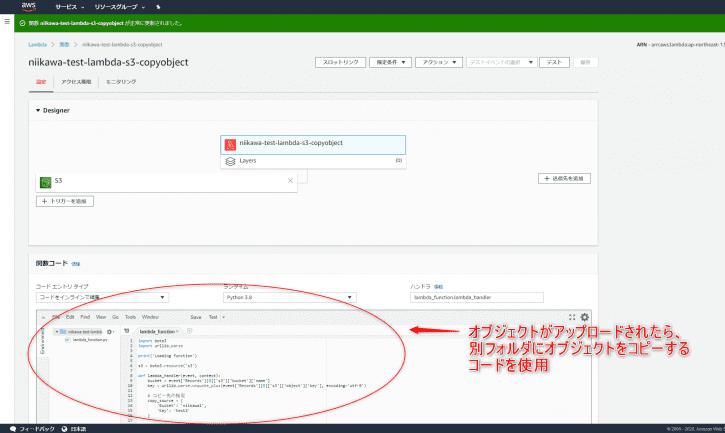
- Lambdaのコンソールを開き、一から作成します。関数名を入力、ランタイム(今回はPython 3.8とします)、実行ロールを選択します。
- Lambda関数が作成されたら、下記のコードを利用します。簡単ですが、処理の流れを説明します。
- lambda_handlerに渡されたイベントデータのバケット名を変数 bucket にセットし、オブジェクトのキーを変数 key にセットします。
- 後は変数を用いてバケット名、キー名を標準出力に出力するだけのシンプルな処理です。
- なお、ステップ1は、S3 へアクセスしていないため、ロールにAmazonS3FullAccessのポリシーがなくても動作します。
import boto3
import urllib.parse
print('Loading function')
s3 = boto3.resource('s3')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
print('bucket name = ',bucket)
print('key name = ',key)
- コードができたら、[Save]を押します。
- 次に、トリガを設定しましょう。[+ Add trigger]を押します。
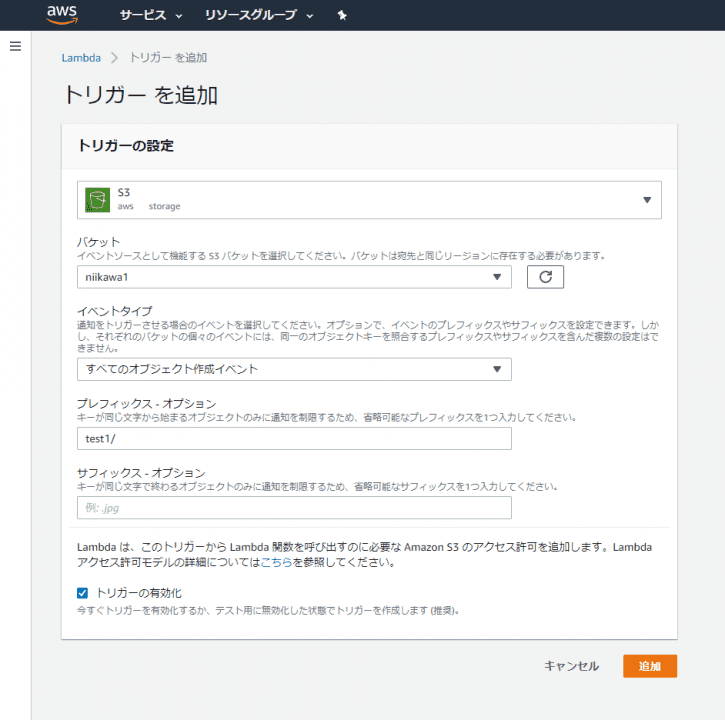
- Trigger configurationが開きます。先ず、Triggerから、[S3]を選択します。
- [Bucket]にトリガに使用したいバケット名を指定します。
- [Event type]にAll object create events(すべてのオブジェクト作成イベント)を指定します。
- [Prefix]に、今回は”test1/” フォルダを指定します。
- [Suffix]は省略します。拡張子などの指定が可能です。
- Enable triggerがチェックされていることを確認して、[Add]を押します。
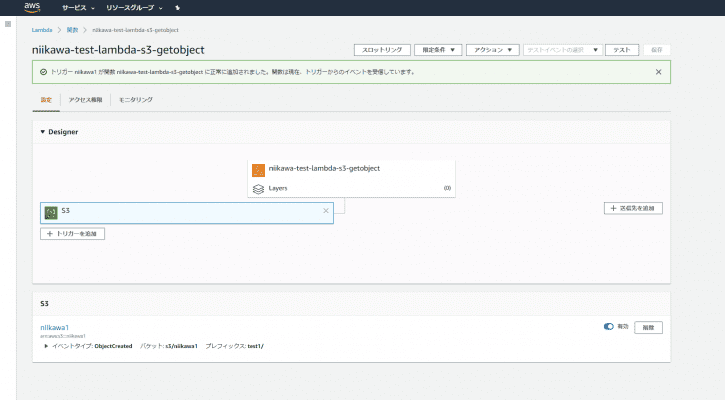
- Lambda関数にS3 のトリガが設定されました。
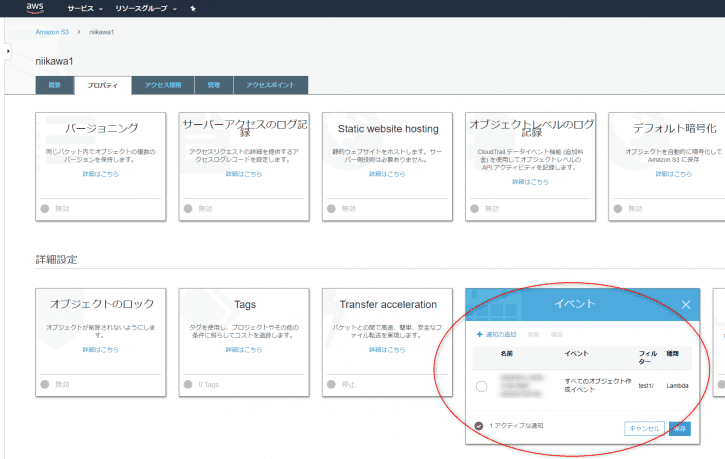
- 念のため、S3バケット側のプロパティを確認します。バケットのプロパティに先ほど設定したイベントが追加されたことが確認できます。
テストしてみる
- S3 バケットの “test1″フォルダにオブジェクト(適当なテキストファイルなど)をアップロードします。
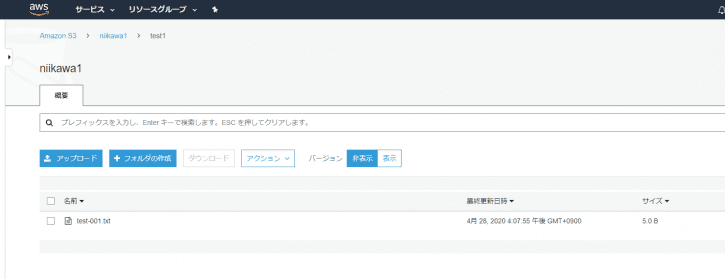
- CloudWatch Logs にバケット名、キー名が記録されたことを確認します。これで、ステップ1 は成功です。

演習3 Lambda+S3のステップ2
概要
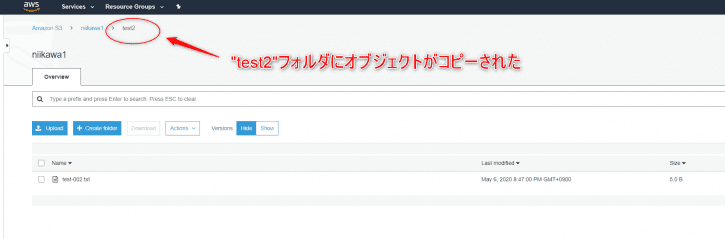
- ステップ2は、S3 バケットの “test1″フォルダにオブジェクトがアップロードされたらLambdaが起動し、同一バケットの “test2″フォルダにオブジェクトをコピーします。
- 前提条件として、事前にLambdaの実行ロールを準備します。ロールは、ステップ1 と同じです。
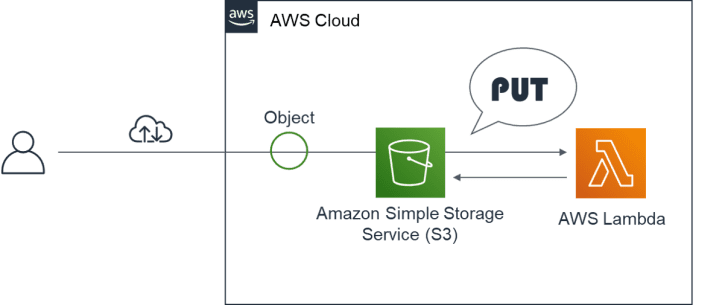
システム構成
- 本演習のシステム構成は、下記の通りです。あらかじめ、S3バケットおよび “test1″、”test2″フォルダを作成しておきます。
構築してみる
- Lambdaのコンソールを開き、一から作成します。関数名を入力、ランタイム(今回はPython 3.8とします)、実行ロールを選択します。
- Lambda関数が作成されたら、下記のコードを利用します。簡単ですが、処理の流れを説明します。
- 今回は、S3リソースを操作するAPIに、Resource API(高レベルAPI)を使用します。
- lambda_handlerに渡されたイベントデータのバケット名を変数 bucket にセットし、コピー元となるオブジェクトのキーを変数 key1 にセットします。
- オブジェクトのcopy() メソッドに使用するパラメータ copy_source を準備します。copy() メソッドのパラメータは、次の辞書型で指定する必要があります。但し、VersionIdは省略可。
- {‘Bucket’: ‘bucket’, ‘Key’: ‘key’, ‘VersionId’: ‘id’}
- コピー先となるオブジェクトのキー(”test2/オブジェクトの名前”)を準備します。
- copy() メソッドを使用して、オブジェクトをコピーします。
- 最後に、コピー元、コピー先の変数を用いてバケット名、キー名を標準出力に出力します。
import boto3
import urllib.parse
print('Loading function')
s3 = boto3.resource('s3')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key1 = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
# コピー元オブジェクトの指定
copy_source = {
'Bucket': bucket,
'Key': key1
}
# コピー先オブジェクトの指定
key2 = 'test2/'+key1.split("/")[1]
# オブジェクトのコピー
object = s3.Object(bucket,key2)
object.copy(copy_source)
print('src bucket name ='+bucket+' , key name ='+key1)
print('dst bucket name ='+bucket+' , key name ='+key2)
- コードができたら、[Save]を押します。
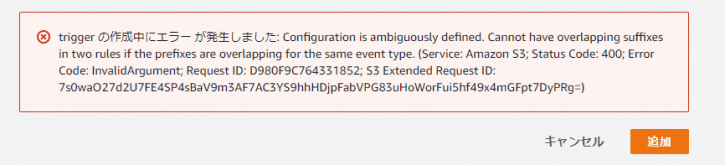
- 次に、トリガを設定します。トリガの作成方法はステップ1 と同じため説明は省略します。但し、注意事項が下記2つあります。
- 1つ目は、LambdaのトリガとなるS3 バケットとLambdaの実行結果となるオブジェクトを格納するS3 バケットが同一であるため、[Prefix]に”test1/” フォルダを指定する作業は必須です。この指定が抜けると無限ループとなり、課金が大変なことになります。ご注意ください。
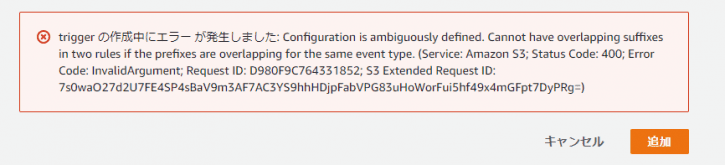
- 2つ目は、トリガが重複する場合に「Configuration is ambiguously defined」のエラーとなるため、あらかじめバケットのプロパティからステップ1で作成したイベントを削除しておきます。
- ステップ2 のLambda関数ができました。
テストしてみる
- 3 バケットの “test1″フォルダにオブジェクト(適当なテキストファイルなど)をアップロードします。
- “test2″フォルダにオブジェクトがコピーされたことを確認します。
- CloudWatch Logs にコピー元、コピー先のバケット名、キー名が記録されたことを確認します。これで、ステップ2は成功です。

演習3 Lambda+S3のステップ3
概要
- ステップ3は、S3 バケットの “test1″フォルダにオブジェクトがアップロードされたらLambdaが起動し、Lambda実行環境内でアップロードされたオブジェクトからパスワード付きの暗号化ZIP ファイルを作成します。最後に、同一バケットの “test2″フォルダへ作成した暗号化ZIP ファイルをアップロードします。
- 前提条件として、事前にLambdaの実行ロールを準備します。ロールは、ステップ1 と同じです。
システム構成
- 本演習のシステム構成は、下記の通りです。あらかじめ、S3バケットおよび “test1″、”test2″フォルダを作成しておきます。
構築してみる
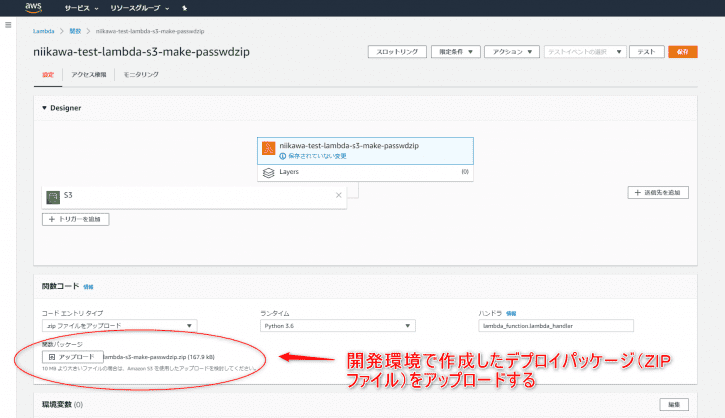
- Lambdaのコンソールを開き、一から作成します。関数名を入力、ランタイム(今回はPython 3.6とします)、実行ロールを選択します。
- Lambda関数が作成されたら、下記のコードを利用します。今回は、ステップ1, ステップ2 と異なり、コードの作成にコンソールエディタは使用しません。開発環境を使ってコードとデプロイパッケージの作成を行います。Lambdaの開発環境構築からLambda関数にデプロイパッケージをデプロイするまでの手順は、こちらの記事を参照ください。
- 各コードで行っている処理は、コメントを参照ください。
import boto3
import urllib.parse
import os
import tempfile
import pyminizip
print('Loading function')
s3 = boto3.resource('s3')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key1 = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
# ZIP圧縮前キー名の取得
key1_name = key1.split("/")[1]
# ZIP圧縮後キー名の準備
key2_name = key1_name+'.zip'
key2 = 'test2/'+key2_name
# tmpdirにオブジェクトをダウンロード、暗号化ZIPを作成してアップロードする
## S3からオブジェクトをGETする
object = s3.Object(bucket,key1)
response = object.get()
## 一時ディレクトリの作成
tmp_path = tempfile.TemporaryDirectory()
print('tmp_path: '+str(tmp_path))
## 一時ディレクトにオブジェクトをダウンロード
with open(tmp_path.name+'/'+key1_name, "w+b") as f:
f.write(response['Body'].read())
## カレントディレクトリを移動
os.chdir(tmp_path.name)
# オブジェクトをZIP圧縮する
pyminizip.compress(key1_name, '', key2_name, 'password1', 0)
## S3へオブジェクトをPUTする
object = s3.Object(bucket,key2)
response = object.put(
Body=open(key2_name, 'rb')
)
# 利用済みファイルの削除
os.unlink(key2_name)
# 一時ディレクトリの削除
tmp_path.cleanup()
- 出来たデプロイパッケージをLambda関数にアップロードします。10MBを超える場合は、S3 経由でアップロードが必要となります。
- コードができたら、[Save]を押します。
- 次に、トリガを設定します。トリガの作成方法はステップ1 と同じため説明は省略します。但し、注意事項が下記2つあります。
- 1つ目は、LambdaのトリガとなるS3 バケットとLambdaの実行結果となるオブジェクトを格納するS3 バケットが同一であるため、[Prefix]に”test1/” フォルダを指定する作業は必須です。この指定が抜けると無限ループとなり、課金が大変なことになります。ご注意ください。
- 2つ目は、トリガが重複する場合に「Configuration is ambiguously defined」のエラーとなるため、あらかじめバケットのプロパティからステップ1で作成したイベントを削除しておきます。
- ステップ3 のLambda関数ができました。
テストしてみる
- S3 バケットの “test1″フォルダにオブジェクト(適当なテキストファイルなど)をアップロードします。
- “test2″フォルダにZIP圧縮されたオブジェクトがアップロードされたことを確認します。
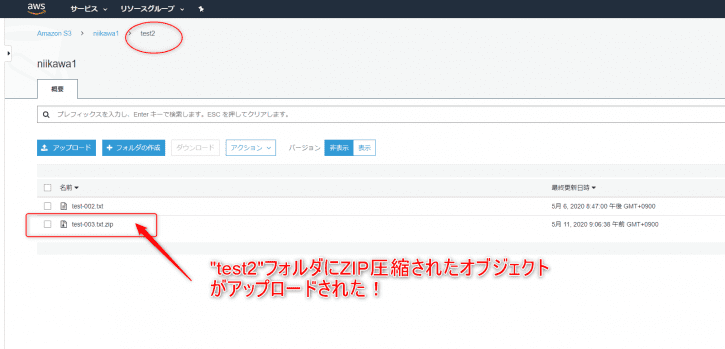
- CloudWatch Logs に特にエラーはなく、LambdaでZIP圧縮に使われた一時ディレクトリのpathが記録されたことを確認します。これで、ステップ2は成功です。

おさらい
- 今回の演習では、S3 をトリガに設定するLambdaの作成、LambdaからS3 バケットのオブジェクトをread/writeする方法、Lambdaの開発環境でデプロイパッケージを作成してデプロイする方法、pyminizipなどいくつかのライブラリをImportしてpythonの処理に使う事例などを学びました。これらの演習は頻繁に使うエッセンスだと思います。この機会に、ぜひ理解を深めて下さい。
- 次回は、DynamoDB を使ったLambda に挑戦です。以下バックナンバー。お楽しみに。
バックナンバー
- 【初学者向け】サーバーレスを学ぶための実践演習1
- 【初学者向け】サーバーレスを学ぶための実践演習2
参考資料
AWS Lambda実践ガイド (impress top gear) (日本語) 単行本(ソフトカバー) AMAZON JP

