
loggly => Apache Kafka => Amazon Kinesis に流れ着いた、cloudpack の かっぱ(@inokara)です。どうも。
はじめに
Amazon Kinesis について以下の日本語資料を読ませて頂きましたのでそれをまとめました。
- Amazon kinesisで広がるリアルタイムデータプロセッシングとその未来
- AWS Black Belt Techシリーズ Amazon Kinesis
- [初音ミク] Kinesis でフリーザを撃て!
- Pythonでkinesis〜ぱいきね! in 第20回AWS User Group Japan 東京勉強会2014.04.11
Amazon Kinesis とは
一言で言うと
- フルマネージドリアルタイムデータ処理サービス
AWS での位置づけ
| サービス | 特徴 |
|---|---|
| kinesis | 半構造化データをストリームで処理、シンプルなデータ処理、他システムへのデータ転送 |
| EMR | 半構造化されたデータに対してデータ処理を数回実行、事前処理無しで実行 |
| RDS / DynamoDB / Redshift | 構造化されたデータに対してクエリ処理、大量データに対するインデックス処理を事前に行う |
kinesis の特徴はなんと言ってもストリームでデータを処理出来るということでしょうかね。
Amazon Kinesis の特徴
- フルマネージド
- リアルタイム処理
- 高スループット、伸縮自在
- インテグレーション
- アプリ開発 SDK
- 低コスト
- お手軽に始められる
ちょっと抽象的ですな…。
Amazon Kinesis の仕組み
[データ送信側] => [Kinesis(ストリーム)] => [Kinesis アプリケーション] => 各種サービス(Amazon S3 とか EMR とか Redshift とか、さらに Kinesis とか)
Kinesis のサービス単位は「ストリーム」となります。「データ送信側」から送られたデータは「ストリーム」を介して「Kinesis アプリケーション」で取り出されて各種サービスにパブリッシュされることになります…ん、ちょっと解りづらい(自分で書いていても…)ので以下のように整理。
| 用語 | 役割等 |
|---|---|
| ストリーム | Kinesis のサービス単位で 1 つ以上の Shard で構成される(Shard の増減によりスケール制御が可能) |
| Shard | データ入力 1MB/sec で 1000TPS、データ処理 2MB/sec で 5TPS のキャパシティを持つ |
| Data Record | データ送信側から送られてくる入力データで 24 時間且つ複数の AZ に保存される |
| Kinesis アプリケーション | Kinesis Client Library を使ったアプリケーション |
「データ送信側から送られた Data Record は一定ルールに基いてストリーム(土管)内のシャード(土管内の配管)に振り分けられて Kinesis アプリケーションで Data Record を取得する」と書くとちょっと解りやすくなりました。また、RabbitMQ 等の Pub/Sub モデルのアプリケーションで考えると…
- データ送信側 = Publisher(Producer)
- Kinesis アプリケーション = Subscriber(Consumer)
- Kinesis = Worker
というイメージでしょうか…。
Amazon Kinesis の課金
- シャード利用料($0.015/shard/時間)
- put トランザクション($0.028/1,000,000 PUT)
データの入力
- データの入力は API や各種言語の SDK から行うことが可能
- fluentd のプラグイン、Log4J のアウトプットでも入力することが出来る
- 受け取った Data Record を Shard に分配する
- Data Record の中身はデータブロブ(Max 50KB)とパーティションキー(Max 256B)で構成される(送信側で指定)
- Shard への分配はパーティションキーを MD5 でハッシュした値に合致した範囲の Shard に分配される
- Shard にはキャパがある→うまく分配得きるようにパーティションキーを設計する必要がある
- ストリームに入力された Data Record に Kinesis がユニークなシーケンス番号を付与(時間の経過と共に増加する)
- シーケンス番号は PutRecord API のレスポンスで取得可能
データの取り出し
- データの取り出しは API や 各種言語の SDK で実装可能
-
GetShardIteratorで Shard 内のポジションを取得、GetRecordsでデータ入力(取得)が可能 -
ShardIteratorTypeを指定してポジションを取得する(最新のデータ、最も古いデータ、指定シーケンス番号以降等)
Kinesis Client Library の基礎
- API や SDK の実装ではデータを処理する環境の耐障害性や Shard の分割やマージの追随等を自前で実装する必要がある
- Kinesis Client Library を用いることで上記のような処理を意識する必要が無くなる
- Kinesis Client Library は Java に対応
- Kinesis Client Library はチェックポイント(シーケンス番号)の管理を DynamoDB で管理している(初回起動時に DynamoDB のテーブルが生成される)
- Worker スレッドにて Kinesis からデータを取得する
- 設定された間隔で Worker の ID をキーにしてシーケンス番号を DynamoDB のテーブルに格納する
Kinesis Client Library の可用性と拡張性
- 複数の Kinesis Client Library で可用性を高める
- 1 つの Kinesis Client Library インスタンスがデータ取得が出来ない場合にもう 1 つの Kinesis Client Library が DynamoDB からシーケンス番号を取得してデータの取得する
- Shard が追加された場合、それを検知して DynamoDB に新しい Shard のチェックポイント情報を追加する
- 目的に応じた Kinesis アプリケーションの追加が可能
- 他の AWS サービスとのインテグレーションが容易
その他
- Kinesis Storm Spout
- EMR Connector は Hive や Pig 等から Kinesis Stream のデータを取得して Map Reduce の処理が可能
Amazon Kinesis の運用
CloudWatch によるメトリクス監視
| メトリクス | 監視内容 |
|---|---|
| GetRecords.Bytes | GetRecords で取得されたデータバイト数 |
| GetRecords.IteratorAge | GetShardIterator の有効時間 |
| GetRecords.Latency | GetRecords のレイテンシー |
| GetRecords.Success | GetRecords API の成功した数 |
| PutRecord.Byte | PutRecord で入力されたデータバイト数 |
| PutRecord.Latency | PutRecord のレイテンシー |
| PutRecord.Success | PutRecord API の成功した数 |
Shard 分割とマージ
- Shard のキャパシティと実際の利用に応じて Shard を分割又はマージしてサービスの拡張とコストの最適化が可能
-
SpritShardAPI で分割、MergeShardsAPI でマージすることが出来る - Shard は時間単位で課金される為、Split と Merge を行うことを推奨
Kinesis の使いドコロ
SQS と Kinesis
- Kinesis でも Pub/Sub メッセージモデルを構築出来る
- Stream 内でユニークなシーケンス番号が Data Record に付与される為、オーダー順に処理することが出来る
- SQS は単一のデータを複数の Worker が処理
- Kinesis は目的に応じた Worker(Kinesis アプリケーション)が同一のデータを利用して処理
リアルタイムダッシュボード
- Web ログ、センサーデータ等のリアルタイム情報の可視化
- 短期状況の可視化だけではなく長期分析にデータを流す
その他
- ETL 処理
- バッファ(大量データの一次バッファ、SQS でも同様の構成を構築可能、Kinesis アプリケーションを Storm に置き換える組み合わせも可能)
Amazon Kinesis を Ruby から使ってみよう
aws-sdk for Ruby を利用して Amazon Kinesis を利用してみようという算段です。こちらの RubyからAmazon Kinesisを操作する | Tech-Sketchの記事を参考にさせて頂きました。
ストリームを作る
以下のようなスクリプトでストリームを作成します。シャードは 1 つです。
#!/usr/bin/env ruby
require 'aws-sdk'
ACCESS_KEY_ID = "AKxxxxxxxxxxxxxxxxx"
SECRET_ACCESS_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
REGION = "ap-northeast-1"
#
client = AWS::Kinesis.new(
access_key_id: ACCESS_KEY_ID,
secret_access_key: SECRET_ACCESS_KEY,
region: REGION
).client
#
client.create_stream(
:stream_name => ARGV[0],
:shard_count => 1
)
#
stream = client.describe_stream(
:stream_name => ARGV[0]
)
#
p stream
以下のように実行します。
ruby create-stream.rb tsurupika
以下のように出力されます。
{:stream_description=>{:stream_name=>"tsurupika", :stream_arn=>"arn:aws:kinesis:ap-northeast-1:044703681656:stream/tsurupika", :stream_status=>"CREATING", :shards=>[], :has_more_shards=>false}}
put と get でストリーム感を…
以下はデータレコードを put するスクリプトの抜粋です。引数でストリームを指定してデータレコードを put します。
d = [ "aho", "bake", "hage" ]
p = [ "1","2","3","4","5" ]
#
loop do
t = Time.now
data_record = #{t} #{d.sample}"
partition_key = p.sample
response = client.put_record(
stream_name:ARGV[0],
data: data_record,
partition_key: partition_key
)
puts "Data : #{data_record}, Shard Id : #{response.shard_id}, Sequence Number : #{response.sequence_number}"
sleep (1)
end
データレコードの取得は以下のようなスクリプトです。
shards = client.describe_stream(stream_name: ARGV[0]).stream_description.shards
shards_ids = shards.map(&:shard_id)
loop do
shards_ids.each do |shard_id|
shard_iterator_info = client.get_shard_iterator(
stream_name: ARGV[0],
shard_id: shard_id ,
shard_iterator_type: 'TRIM_HORIZON'
)
shard_iterator = shard_iterator_info.shard_iterator
records_info = client.get_records(
shard_iterator: shard_iterator
)
records_info.records.each do |record|
puts "Data : #{record.data} Partition Key : #{record.partition_key}"
end
end
end
とりあえずデモ。
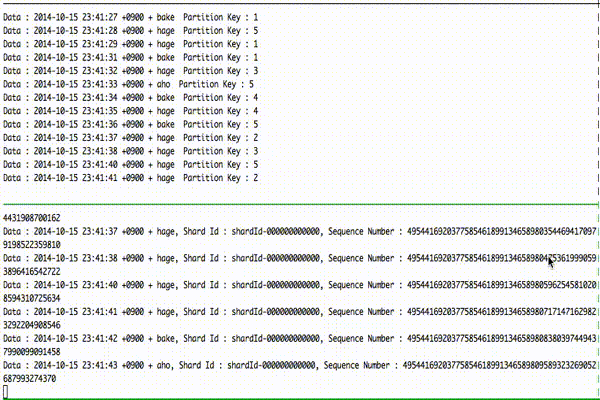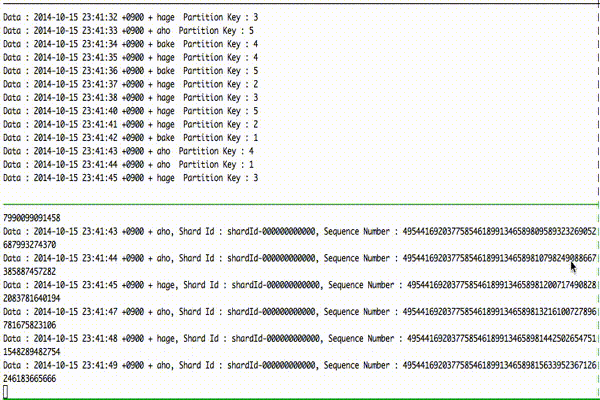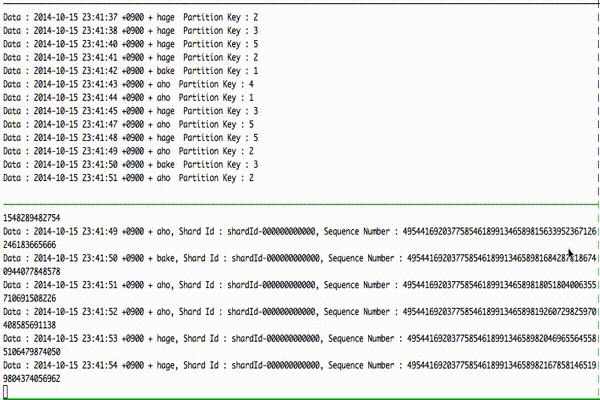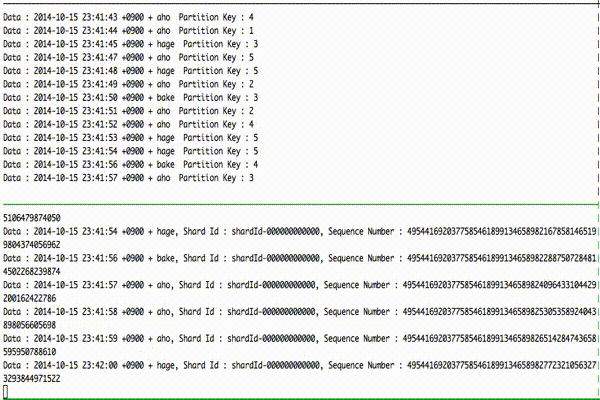
上がデータ get 側、下がデータ put 側となっています。
最後に
Amazon Kinesis を少しかじってみました。
当初は fluentd と似た印象を受けましたが、データを put する側として fluentd があることから、RabbitMQ 等のメッセージブローカーな側面を持ちながら AWS で動作しているというメリット(フルマネージド、容易なスケールイン、スケールアウト出来る)を生かしてログ等の大量データをリアルタイムにストリーム処理する為のツールの一つとして選択を検討出来るのではないかと思いました。
まだまだ「触ってみました」レベルなので明確なメリット・デメリットは解りませんが、引続き勉強していきたいと思います。多分、次回は fluentd 経由でデータを put してみたいと思います。
元記事はこちらです。
「AWS 白帯シリーズ(19)Amazon Kinesis メモ」


