
これは何?
マルチアカウント環境で Systems Manager インベントリ と Athena を使って EC2 インスタンスの OS 情報を一覧化する方法を試したのでその手順を記載した記事です!
Amazon Linux 2 が 2025 年 6 月 30 日 に EOL を迎えるため、リプレース対応の一環として棚卸しをするケースなどに役に立つかもしれません!
https://aws.amazon.com/jp/amazon-linux-2/faqs/
Amazon Linux 2 のサポート終了日 (EOL、End of Life) は、次のバージョンへの移行に十分な時間を提供するために、2023 年 6 月 30 日から 2025 年 6 月 30 日に 2 年間延長されました。
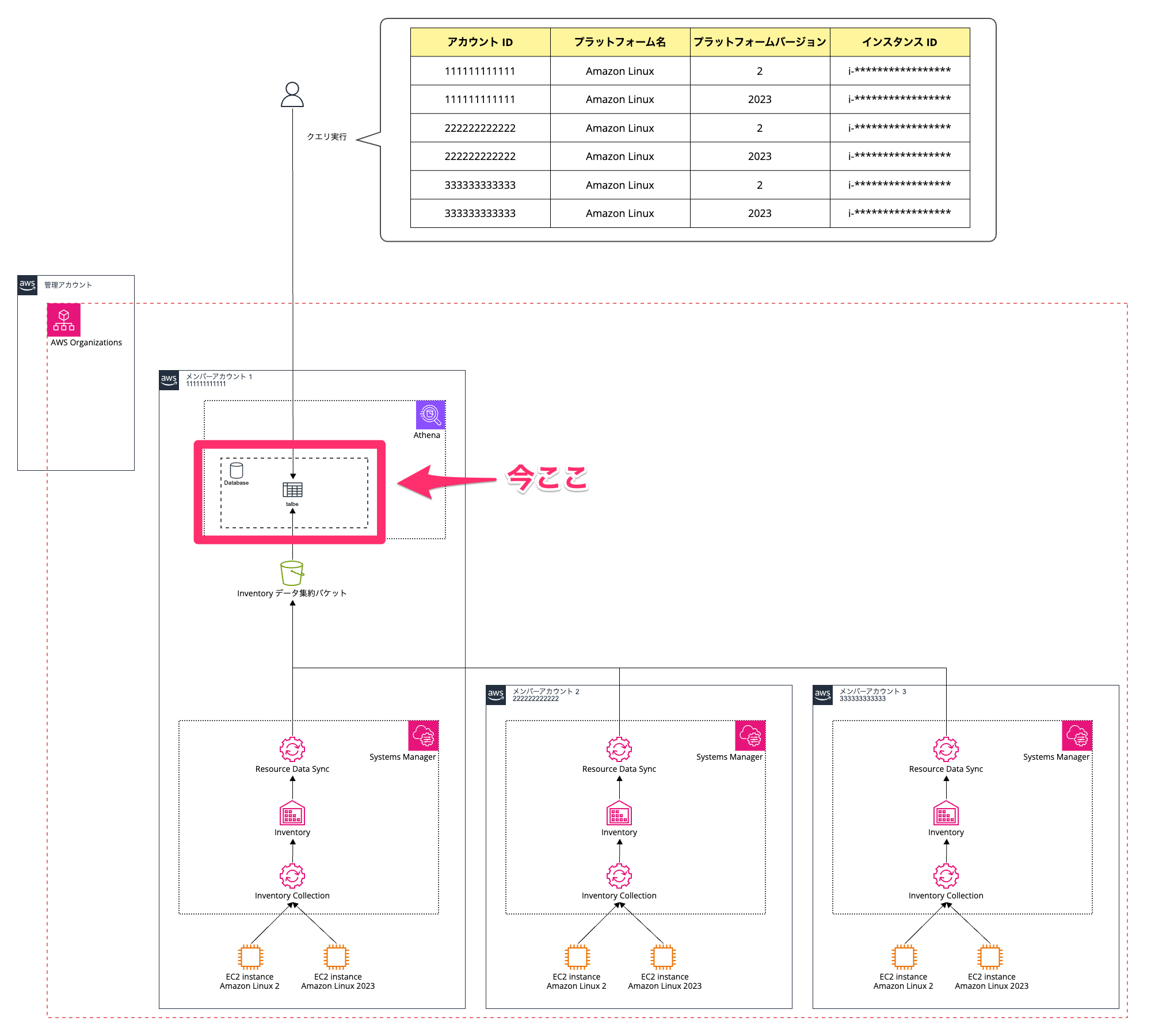
構成図
理解しやすくなると思うので最終的な状態の構成図を先に見ていただきます😌
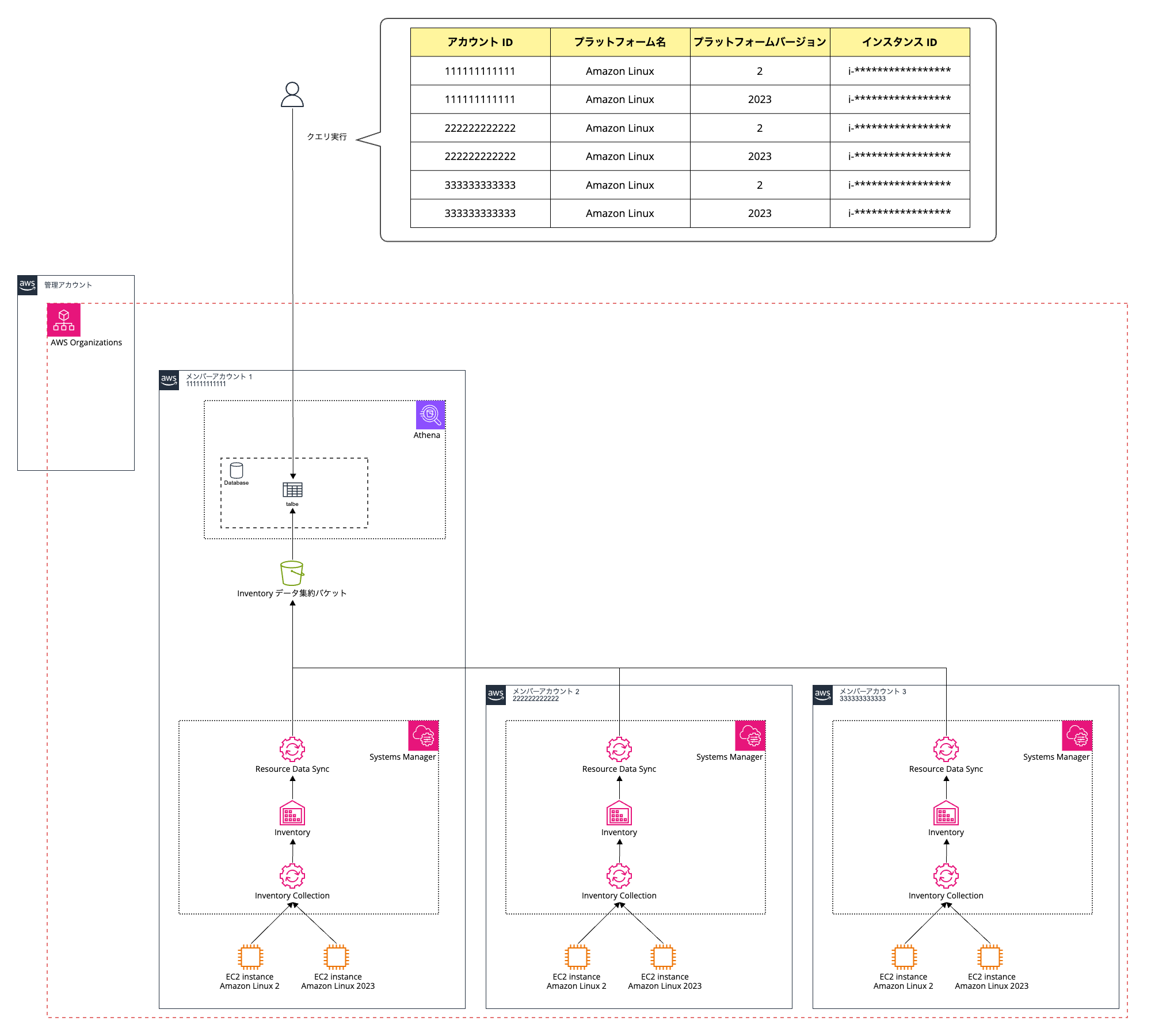
登場する主な AWS サービスについて
- AWS Systems Manager インベントリ
- Amazon Athena
- Amazon EC2
- AWS Organizations
手順について説明
登場人物となる AWS アカウント
⓪ 管理アカウント
① メンバーアカウント 1
② メンバーアカウント 2
③ メンバーアカウント 3
前提
- AWS Organizations がすでに利用されている前提です
- ① ~ ③ の各メンバーアカウントで Amazon Linux 2 と Amazon Linux 2023 の EC2 インスタンスが 1 つずつ存在する前提です
- EC2 インスタンスは AWS Systems Manager でマネージドインスタンスとして登録されている前提です
手順
Systems Manager インベントリ のデータを集約する S3 バケットを作成する
① メンバーアカウント 1 で Systems Manager インベントリ のデータを集約する S3 バケットを作成します。
S3 バケットの作成方法については割愛します。
バケットポリシーについては以下の AWS 公式ドキュメントを参考にして設定しています。
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-inventory-datasync.html
バケットポリシーの例は以下です。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SSMBucketPermissionsCheck",
"Effect": "Allow",
"Principal": {
"Service": "ssm.amazonaws.com"
},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::[Inventory データ集約バケット]"
},
{
"Sid": " SSMBucketDelivery",
"Effect": "Allow",
"Principal": {
"Service": "ssm.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": [
"arn:aws:s3:::[Inventory データ集約バケット]/accountid=*/*"
],
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control",
"aws:SourceOrgID": "[AWS Organizations 組織 ID]"
}
}
},
{
"Sid": " SSMBucketDeliveryTagging",
"Effect": "Allow",
"Principal": {
"Service": "ssm.amazonaws.com"
},
"Action": "s3:PutObjectTagging",
"Resource": [
"arn:aws:s3:::[Inventory データ集約バケット]/accountid=*/*"
]
}
]
}
[Inventory データ集約バケット]には今回作成する Inventory データ集約バケットのバケット名を記載してください[AWS Organizations 組織 ID]については AWS Organizations の組織 ID を入力してください- 組織 ID については
⓪ 管理アカウントから確認してください
- 組織 ID については
各メンバーアカウントで AWS Systems Manager インベントリ の インベントリの関連付け を設定
AWS Systems Manager インベントリ の インベントリの関連付け (Inventory Collection) を設定します。
今回は各メンバーアカウントで AWS CLI を使って設定を行います。
以下のコマンドを各メンバーアカウントで実行します。
aws ssm create-association \ --association-name [関連付けの名前] \ --name AWS-GatherSoftwareInventory \ --targets Key=InstanceIds,Values=* \ --schedule-expression "rate(1 day)" \ --parameters applications=Enabled,awsComponents=Enabled,customInventory=Enabled,instanceDetailedInformation=Enabled,networkConfig=Enabled,services=Enabled,windowsRoles=Enabled,windowsUpdates=Enabled
[関連付けの名前]には任意の名前を入れてください--schedule-expressionのオプションでインベントリが保存される周期を設定します。上記のコマンドでは 1 日毎になっています
※コマンドの詳細については こちらの公式ドキュメント を参照ください
もし関連付けをすぐに実行したい場合は以下のどちらかを実行してください。
- AWS マネジメントコンソールから作成した
インベントリの関連付けで [Apply association now] (関連付けを今すぐ適用) を押下 - こちらの公式ドキュメント を参考に AWS CLI で「関連付けを今すぐ適用」を実行
各メンバーアカウントで AWS Systems Manager インベントリ の リソースデータの同期 を設定
AWS Systems Manager インベントリ の リソースデータの同期 (Resource Data Sync) を設定します。
以下のコマンドを各メンバーアカウントで実行します。
aws ssm create-resource-data-sync --sync-name "[リソースデータの同期]" --s3-destination '{"BucketName":"[Inventory データ集約バケット]","Region":"ap-northeast-1","SyncFormat":"JsonSerDe"}' --region ap-northeast-1
[リソースデータの同期]には任意の名前を入れてください[Inventory データ集約バケット]には先ほど作成した Inventory データ集約バケット のバケット名を入れてください
※コマンドの詳細については こちらの公式ドキュメント を参照ください
Athena で データベース、テーブル作成
① メンバーアカウント 1 にて Athena で データベース、テーブル作成を行います。
※ Athena の使い方などは割愛します
まず以下のクエリでデーターベースを作成します。
CREATE DATABASE IF NOT EXISTS [データベース名]
データベースを作成したらそのデータベースを選択した状態で以下のクエリを実行してテーブルを作成します。
CREATE EXTERNAL TABLE `[テーブル名]`( `PlatformName` string, `PlatformVersion` string, `AgentType` string, `AgentVersion` string, `InstanceId` string, `InstanceStatus` string, `ComputerName` string, `IamRole` string, `IpAddress` string, `ResourceCategory` string, `PlatformType` string, `resourceId` string, `captureTime` string, `schemaVersion` string) PARTITIONED BY ( `accountid` string, `region` string, `resourcetype` string) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://[Inventory データ集約バケット]/AWS:InstanceInformation/' TBLPROPERTIES ( 'classification'='json', 'compressionType'='none', 'typeOfData'='file')
[テーブル名]には任意のテーブル名を入れてください[Inventory データ集約バケット]には最初に作成した Inventory データ集約バケット のバケット名を入れてください
テーブルを作成したら以下のクエリを実行してメタデータを更新します。
MSCK REPAIR TABLE [テーブル名]
[テーブル名]には先ほど作成したテーブル名を入れてください
Athena で SELECT クエリを実行して EC2 インスタンスの OS 情報一覧を表示する
① メンバーアカウント 1 にて SELECT クエリを実行して EC2 インスタンスの OS 情報一覧を表示します。
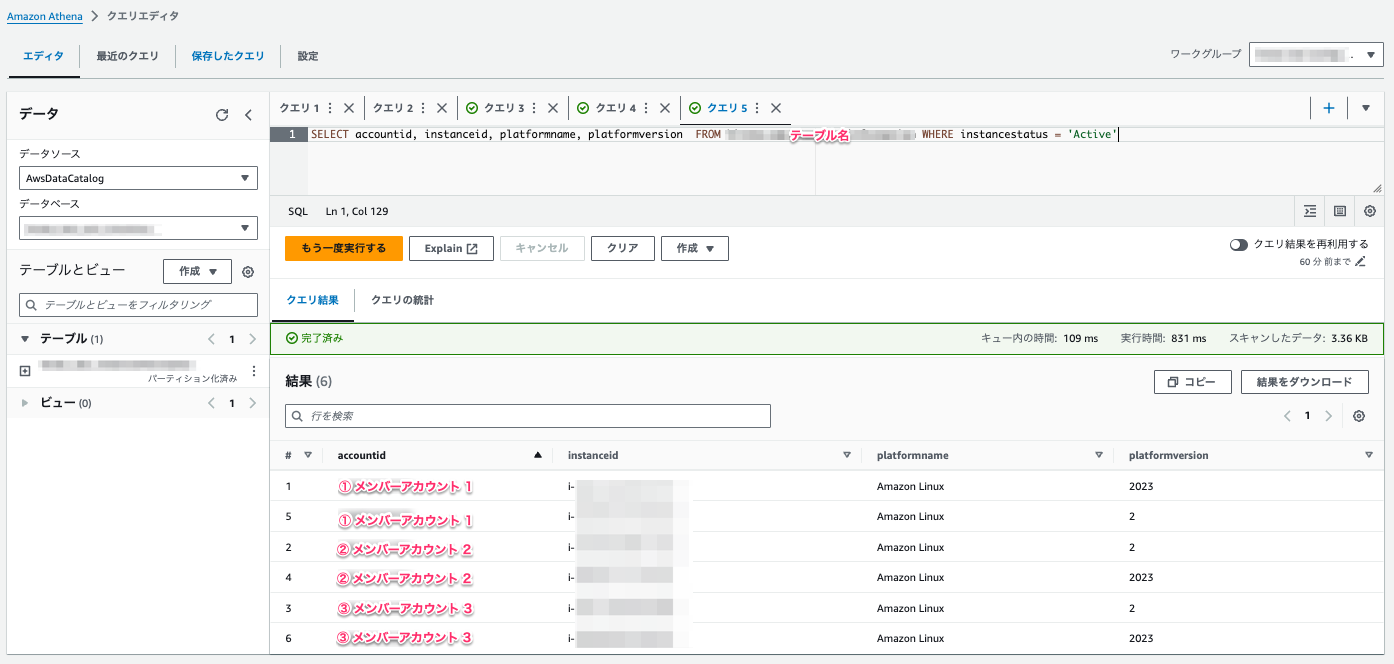
以下のクエリを Athena で実行します。
SELECT accountid, instanceid, platformname, platformversion FROM [テーブル名] WHERE instancestatus = 'Active'
[テーブル名]には先ほど作成したテーブル名を入れてください
以下の画像のように EC2 インスタンスの OS 情報一覧 が取得できます!
クエリの内容を調整して Amazon Linux 2 だけ出力することも可能です。
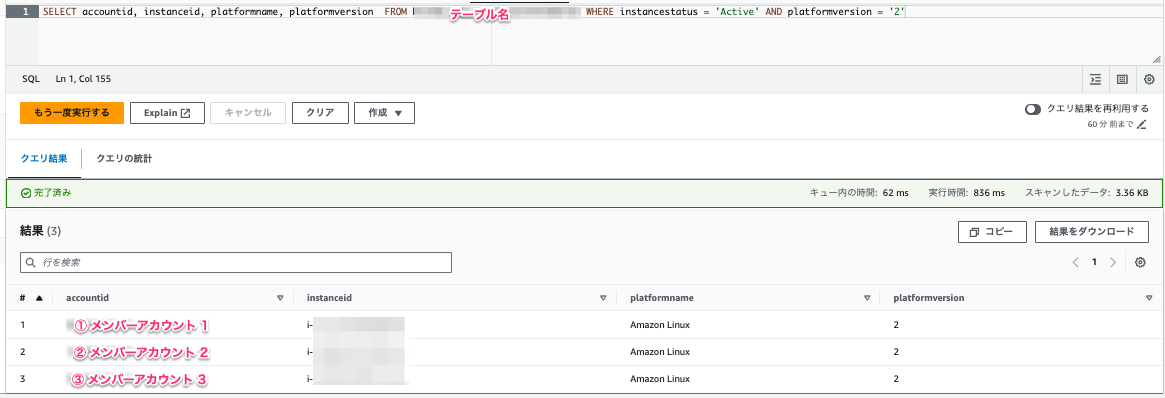
「結果をダウンロード」のボタンを押下すれば csv で結果をダウンロードすれば EC2 インスタンスの棚卸しが捗ると思います!
終わりに
マルチアカウントでのリソースの可視化ということについては色々な手段があるのですが、例えば今回のような OS 情報のような EC2 インスタンスの中身の情報が欲しい場合は AWS Systems Manager を使うことになります。
また、今回の構成についてはテーブルの自動更新は含まれていません。
テーブルの自動更新を目指す場合は AWS Glue などを利用することが考えられます。
さらに、情報をダッシュボードにしていつでも見れるようにしたいとなったら Amazon QuickSight を利用するということも考えられますね。
ただ、例えば EC2 インスタンスの OS 情報の棚卸しが目的だとして「頻繁に見るので常に最新の情報が簡単に見えるようにしたい」ということでなければ
手動でのテーブル更新とクエリの実行は必要になりますが今回の構成なら低コストで実現できると思います。
この記事が Amazon Linux 2 のリプレース対応対応などでお役に立てば幸いです😌


