
5 時過ぎに目が覚めて眠れなくなったので気になっていたことを考えてみた。
はじめに
RDS のリードレプリカを HAProxy で振り分ける方法については…
HAProxyを用いたRead Replica(RDS)の振り分け
上記の記事を参考にしつつ…
RDS のリードレプリカへのアクセスを HAProxy で分散しつつ consul と consul-template で冗長化するメモ
上記のようなことをやってみたりした。
RDS のリードレプリカ(RR)接続を HAProxy で振り分ける
一応、構成図
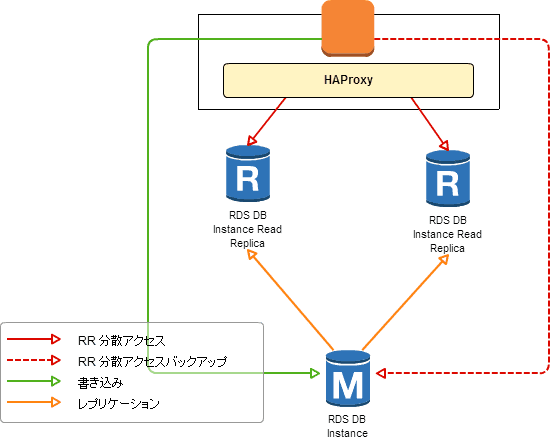
基本的には…
HAProxy で RDS への分散アクセスを行う場合には、以下のように設定すれば RDS への接続をチェックして接続出来なければ HAProxy がよしなに切り離してくれる。
(略) listen mysql bind 0.0.0.0:3306 mode tcp option mysql-check user user_name balance leastconn server read01 hogehoge-replica01.xxxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com:3306 check port 3306 inter 10000 fall 2 server read02 hogehoge-replica02.xxxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com:3306 check port 3306 inter 10000 fall 2 server master hogehoge.xxxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com:3306 check port 3306 backup
ポイントは死活チェック用のユーザーを作成して option mysql-check user user_name を設定することで、MySQL サーバーに対して Client Authentication パケットと QUIT パケットを送信してレスポンスをチェックして死活を判断している点。
問題点
残念ながら、上記の Client Authentication パケットと QUIT パケットを送信する死活監視では、レプリケーションが停止してしまうエラー等には対応出来ないという問題があり、これを解決する為の方法(苦肉の策)を考えてみる。
一歩踏み込んだ RDS の死活監視
まずは構成図
以下のような構成を作って動作確認。
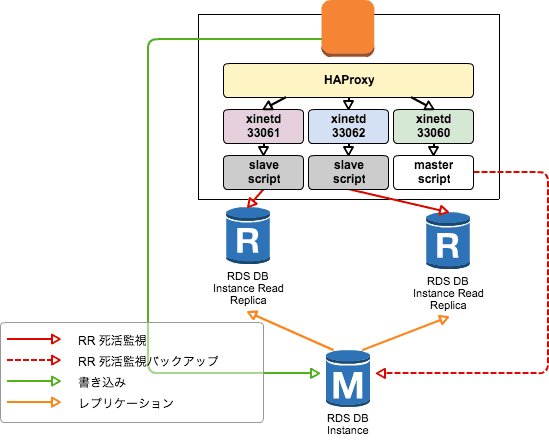
概要
mysql-checkを止める- 死活監視の方法を一歩踏み込んだ方法で監視する(レプリケーションが正しく動作しているかをチェックする)
- チェックはシェルスクリプトを利用して HTTP レスポンスで HAProxy に死活を判断させる(
option httpchkを利用する) - シェルスクリプトは xinetd を利用して HAProxy からのヘルスチェックが発生した時のみ起動させる
RR インスタンスにおいてレプリケーションが正しく動作していることを判断させるスクリプト
show slave status の出力から Slave_IO_Running と Slave_SQL_Running が共に Yes となっていることでレプリケーションが正しく動作していると判断する。
Slave_IO_Running: Yes Slave_SQL_Running: Yes
また、MySQL への接続が出来ない場合を想定して以下のように --connect_timeout= も指定しておく。
MSG=`/usr/bin/mysql --connect_timeout=1 -h ${MYSQL_HOST} -P ${MYSQL_PORT} -u${MYSQL_USERNAME} -p${MYSQL_PASSWORD} -e "show slave statusG" | grep Running | grep Yes | wc -l`
スクリプトはこちら。 尚、動作確認の環境ではスクリプト名は mysqlchk_slave.sh として /opt/bin/ 以下に設置する。
$ ls -l /opt/bin/mysqlchk_slave.sh -rwxr-xr-x 1 root root 627 Jul 9 19:33 /opt/bin/mysqlchk_slave.sh 以下のようにリードレプリカホストを第一引数に渡して実行する。 $ /opt/bin/mysqlchk_slave.sh hogehoge-replica01.xxxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com HTTP/1.1 200 OK Content-Type: text/plain up
マスターインスタンスおいて自身がマスターであることを判断させるスクリプト
全てのリードレプリカが停止した際に最終的にマスターインスタンスに対してアクセスさせる為に HAProxy 側で以下のように設定している。
server master hogehoge.xxxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com:3306 check port 3306 backup
その為、マスターインスタンスの死活監視も行う必要があるのので、以下の点をチェックするスクリプトを利用する。
- MySQL に接続することが出来る
- show status を実行して Slave_running が OFF であることをチェック
スクリプトはこちら。 尚、動作確認の環境ではスクリプト名は mysqlchk_master.sh として /opt/bin/ 以下に設置する。
$ ls -l /opt/bin/mysqlchk_master.sh -rwxr-xr-x 1 root root 633 Jul 9 19:54 mysqlchk_master.sh
リードレプリカ用スクリプトと同様にマスターホストを第一引数に渡して実行する。
$ /opt/bin/mysqlchk_master.sh hogehoge.xxxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com HTTP/1.1 200 OK Content-Type: text/plain up
xinetd にスクリプトを登録
設定はこちら。 以下、抜粋。
service mysqlchk_read01
{
flags = REUSE
socket_type = stream
port = 33061
wait = no
user = nobody
server = /opt/bin/mysqlchk_slave.sh
server_args = hogehoge-replica01.xxxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com
log_on_failure += USERID
disable = no
only_from = 127.0.0.1
per_source = UNLIMITED
}
(略)
only_from を 127.0.0.1 に指定することで最低限のセキュリティを担保。per_source を UNLIMITED にして同一クライアントからの接続を上限緩和。
/etc/services にサービスを登録
起動するサービスは /etc/services に登録しておく必要があるので以下のように追記しておく。
sudo cp /etc/services /etc/services.bk cat > /etc/services # mysqlchk_master 33060/tcp mysqlchk_read01 33061/tcp mysqlchk_read02 33062/tcp EOT
HAProxy の設定
HAProxy の設定は以下のようにヘルスチェック部分を修正する。
(略) listen mysql bind 0.0.0.0:13306 mode tcp log global option log-health-checks balance leastconn option httpchk server read01 hogehoge-replica01.xxxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com:3306 check inter 1000s fall 2 addr 127.0.0.1 port 33061 server read02 hogehoge-replica02.xxxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com:3306 check inter 1000s fall 2 addr 127.0.0.1 port 33062 server master hogehoge.xxxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com:3306 check inter 1000s fall 2 addr 127.0.0.1 port 33060 backup
ポイントは…
- option httpchk を利用することでスクリプトに対して HTTP での死活チェックを行うようになる
- addr と port で死活チェックのホストとポートを指定する(今回は localhost の各ポートに対してチェックを行う)
xinetd と HAProxy を起動
sudo service xinetd start sudo service haproxy restart
動作確認
通常
以下のようにローカルホストに接続するとそれぞれのリードレプリカにアクセスする。
$ mysql -ureplchk -h 127.0.0.1 -P 13306 -e "SELECT @@hostname hostname;" +-----------------+ | hostname | +-----------------+ | ip-172-23-0-202 | +-----------------+ $ mysql -ureplchk -h 127.0.0.1 -P 13306 -e "SELECT @@hostname hostname;" +-----------------+ | hostname | +-----------------+ | ip-172-23-0-164 | +-----------------+
異常発生(リードレプリカの 1 台に接続出来なくなった)
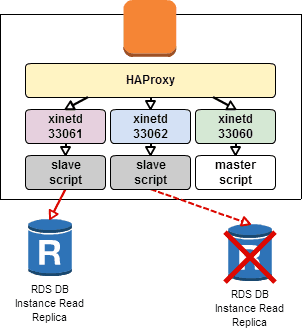
何らかの理由でリードレプリカの 1 台に接続出来なくなった場合(例:セキュリティグループを外した)には HAProxy のログに以下のように記録される。
Health check for server mysql/read01 failed, reason: Layer7 timeout, check duration: 1000ms, status: 1/2 UP. Health check for server mysql/read01 failed, reason: Layer7 timeout, check duration: 1000ms, status: 1/2 UP. Health check for server mysql/read01 failed, reason: Layer7 timeout, check duration: 1001ms, status: 0/2 DOWN. Health check for server mysql/read01 failed, reason: Layer7 timeout, check duration: 1001ms, status: 0/2 DOWN. Server mysql/read01 is DOWN. 1 active and 1 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue. Server mysql/read01 is DOWN. 1 active and 1 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue.
復旧して疎通が取れるようになると以下のように記録される。
Health check for server mysql/read01 succeeded, reason: Layer7 check passed, code: 200, info: "OK", check duration: 15ms, status: 1/2 DOWN. Health check for server mysql/read01 succeeded, reason: Layer7 check passed, code: 200, info: "OK", check duration: 15ms, status: 1/2 DOWN. Health check for server mysql/read01 succeeded, reason: Layer7 check passed, code: 200, info: "OK", check duration: 10ms, status: 2/2 UP. Health check for server mysql/read01 succeeded, reason: Layer7 check passed, code: 200, info: "OK", check duration: 10ms, status: 2/2 UP. Server mysql/read01 is UP. 2 active and 1 backup servers online. 0 sessions requeued, 0 total in queue. Server mysql/read01 is UP. 2 active and 1 backup servers online. 0 sessions requeued, 0 total in queue.
異常発生(レプリケーションが止まった)
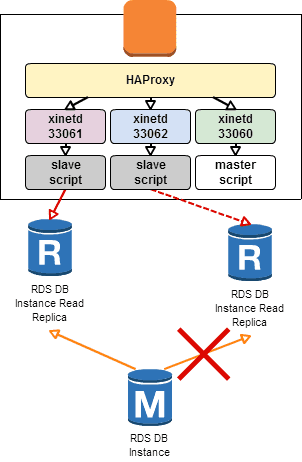
レプリケーションチェックで異常を検知した場合にはスクリプトからは 503 エラーが返ってくるので、以下のように HAProxy のログに記録され、振り分けのメンバーからは外される。
Health check for server mysql/read02 failed, reason: Layer7 wrong status, code: 503, info: "Service Unavailable", check duration: 14ms, status: 1/2 UP. Health check for server mysql/read02 failed, reason: Layer7 wrong status, code: 503, info: "Service Unavailable", check duration: 14ms, status: 1/2 UP. Health check for server mysql/read02 failed, reason: Layer7 wrong status, code: 503, info: "Service Unavailable", check duration: 11ms, status: 0/2 DOWN. Health check for server mysql/read02 failed, reason: Layer7 wrong status, code: 503, info: "Service Unavailable", check duration: 11ms, status: 0/2 DOWN. Server mysql/read02 is DOWN. 1 active and 1 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue. Server mysql/read02 is DOWN. 1 active and 1 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue.
正常に戻る(レプリケーションが復旧)すると以下のように HAProxy のログに出力されて振り分けメンバーに再度ジョインされる。
89 Health check for server mysql/read02 succeeded, reason: Layer7 check passed, code: 200, info: "OK", check duration: 18ms, status: 1/2 DOWN. Health check for server mysql/read02 succeeded, reason: Layer7 check passed, code: 200, info: "OK", check duration: 18ms, status: 1/2 DOWN. Health check for server mysql/read02 succeeded, reason: Layer7 check passed, code: 200, info: "OK", check duration: 10ms, status: 2/2 UP. Health check for server mysql/read02 succeeded, reason: Layer7 check passed, code: 200, info: "OK", check duration: 10ms, status: 2/2 UP. Server mysql/read02 is UP. 2 active and 1 backup servers online. 0 sessions requeued, 0 total in queue. Server mysql/read02 is UP. 2 active and 1 backup servers online. 0 sessions requeued, 0 total in queue.
ということで…
参考
- Alex Williams » Using HAProxy for MySQL failover and redundancy
- Having HAProxy check mysql status through a xinetd script | Sysbible
死活監視スクリプトを xinetd で立ち上げる例。この記事が今回の記事を書くきっかけ。
Making HAProxy 1.5 replication lag aware in MySQL
上記は HAProxy の agent-check というオプションを利用した例。実はこちらでも試してみたが、インスタンスが復旧した際に振り分けメンバーに戻してくれないことがあったので今回は断念。も少し調べてみる。
HAProxy で MySQL のヘルスチェックをちょっと便利にする
死活監視スクリプトを Perl 又 Go で作成されている例。
動作確認あたり得た知見
- RDS では CHANGE MASTER や START / STOP SLAVE が使えない
- 同様に RDS では権限として
REPLICATION SLAVEが付与出来ない(他にも幾つかの権限は付与出来ない)
尚、マスターユーザーの権限についてはドキュメントに以下のように記載されている。
MySQL の場合、マスターユーザーのデフォルトの特権は、create、drop、references、event、alter、delete、index、insert、select、update、create temporary tables、lock tables、trigger、create view、show view、alter routine、create routine、execute、trigger、create user、process、show databases、grant option です。
メリデメ
最後に苦肉の策についてメリデメを整理。
- (メリ)xinetd とシェルスクリプトのみなので手間は最小限(だと思う)
- (メリ)スクリプトを工夫すれば死活条件の精度を高めることが出来る(スクリプトを頑張る)
- (デメ)構成が複雑になる
- (デメ)RR インスタンスの増減が発生した場合に xinetd 設定を手動で管理する必要がある
以上、苦肉の策でした。
