
最近、あるプロジェクトでOpenSearchを使ったベクトル検索を行うシステムと関わることになりました。しかし、「文字列じゃなくてベクトルを検索するってどういうこと?」となってしまい、ちんぷんかんぷんでした。正直、ベクトル検索という言葉を聞くだけで、学生時代に数学が苦手だった記憶が蘇り、頭がクラクラしました。そこで今回は、私がベクトル検索について理解を深めるために学んだことをシェアしたいと思います。
ベクトル検索の概要
ベクトル検索とは、データをベクトル(数値の並び)として表現し、そのベクトル間の類似度を計算して検索結果を返す手法です。従来のキーワードベースの検索とは異なり、内容の意味や文脈を捉えて関連性の高い情報を提供することが可能です。例えば、類似した内容の文章や画像を効率的に見つけ出すことができます。
ベクトルの復習
ここで少しベクトルについて復習しましょう。ベクトルとは、数学で言うところの「方向と大きさを持つ量」のことです。日常生活では、速度や力などがベクトルにあたります。コンピュータサイエンスでは、データを多次元のベクトルとして表現することで、複雑な情報を数値的に扱いやすくします。
例えば、2次元空間のベクトルは「(x, y)」のように表されますが、テキストデータや画像データなどではもっと多次元になります。これにより、データ間の類似度を計算することが可能になります。
ベクトルが似ているとは?
「ベクトルが似ている」とは具体的にどういうことなのでしょうか。一般的には、ベクトル間のコサイン類似度やユークリッド距離を用いて類似度を測ります。ここでは、例としてコサイン類似度に焦点を当てて説明します。
コサイン類似度を例に理解する
直感的な理解
まず、2次元ベクトルを例にとって考えてみましょう。以下の図を参考にしてください。
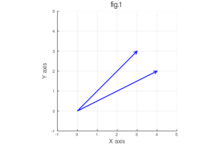
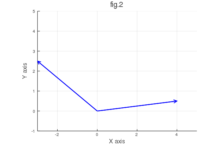
各図にはそれぞれ2つのベクトルが描かれています。
さあ、どちらのペアが似ていると感じますか?
ほとんどの人は、fig.1の方が似ていると感じるでしょう。なぜなら、fig.1のベクトルはほぼ同じ方向を向いており、なす角が小さいからです。一方、fig.2は方向が大きく異なり、なす角が広いため、あまり似ていないと感じます。
なぜ方向が重要なのか?
この直感的な感覚を数値化するのがコサイン類似度です。コサイン類似度は、2つのベクトルがどれだけ同じ方向を向いているかを測る指標です。具体的には、以下の式で計算されます。

ここで、
![]() はベクトルAとベクトルBの内積
はベクトルAとベクトルBの内積
![]() はそれぞれのベクトルの大きさ(ノルム)
はそれぞれのベクトルの大きさ(ノルム)
コサイン類似度は-1から1の値を取り、1に近いほどベクトルは似ている(同じ方向を向いている)と判断されます。
図で見るコサイン類似度
もう一度fig.1を見てみましょう。ベクトルの間のなす角は小さく、コサイン類似度は高くなります。一方、fig.2のベクトルの間のなす角は大きく、コサイン類似度は低くなります。これにより、fig.1の方がfig.2よりも類似していると数値的に判断できるのです。
例えば、fig.1のベクトルのコサイン類似度が0.95であったとすると、これは非常に高い類似性を示しています。一方、fig.2のベクトルのコサイン類似度が-0.7であれば、これは低い類似性を意味します。
ユークリッド距離との違い
ベクトルの類似度を測る方法は他にもありますが、コサイン類似度とよく比較されるのがユークリッド距離です。ユークリッド距離は2つのベクトル間の直線距離を測る指標で、値が小さいほど類似していると判断されます。
例えば、fig.1のベクトルのユークリッド距離は小さいですが、fig.2の距離は大きいため、こちらも類似度が低いと判断されます。しかし、ユークリッド距離はベクトルの大きさにも影響を受けるため、方向だけでなく大きさも考慮する点でコサイン類似度とは異なります。
まとめ
ベクトルが似ているとは、主に方向や大きさの類似性を指します。コサイン類似度を用いることで、ベクトルの方向性に基づいた類似度を数値的に評価することができ、検索の精度を高めることが可能です。
文書をベクトル化する方法
ベクトルの比較方法は分かりました。
では、文書をどのようにベクトル化するのでしょうか。
今回詳しくは踏み込みませんが主な方法として以下のような手法があるようです。
- Bag of Words (BoW): 文書中の単語の出現頻度を数えてベクトル化する。しかし、単語の順序や文脈を考慮しないため限界がある。
- TF-IDF: 単語の重要度を考慮した手法で、文書内で頻繁に出現するが他の文書ではあまり出現しない単語に高い重みを与える。
- Word Embeddings (例: Word2Vec, GloVe): 単語を高次元のベクトルに変換し、意味的な類似性を捉える。
- 文書エンコーダ (例: BERT, GPT): 文脈を考慮した高度なベクトル表現を生成する。
つまり、文書をこういったベクトルへ変換してくれる仕組みに食わせていい感じに変換してもらうということのようです。
人間が考えるような「意味が似ている」というのをいい感じに「似たベクトル表現にする」というのはこういった手法・モデルの出来によりそうです。
最近では、深層学習を用いた手法が主流となっており、文書全体を一つのベクトルとして捉えることで、より精度の高い検索が可能になっているようです。
…なんとな~く理解できた
ベクトル検索について学ぶ前は、ただの難しそうな言葉に感じていました。しかし、ベクトルの基本的な概念や類似度の測り方、そして文書をどのようにベクトル化するかを理解することで、少しずつ全体像が見えてきました。実際にシステムと向き合う中で具体的な応用例を見つけると、より深く理解できるようになりました。
ベクトル検索は一見難しそうですが、基礎をしっかりと押さえることで、私たちのデータ検索や分析に大きな力を発揮するツールとなります。数学が苦手な方でも、少しずつ学んでいけば必ず理解できるはずです。皆さんもぜひ、ベクトル検索の世界に足を踏み入れてみてください。
おわりに
今回の学びが、同じようにベクトル検索に戸惑っている方々の助けになれば幸いです。技術の進化は日進月歩であり、新しい概念に挑戦することは時に難しいですが、その分得られる知識やスキルは計り知れません。これからも一緒に学び続けましょう!



