
概要
Elasticsearch で 日本語形態素解析を行えるプラグラインである、「Sudachi」では、ユーザー辞書を追加したり、同義語を定義することができます。
Amazon OpenSearch Service はマネージドサービスで、OpenSearch のインスタンスにアクセスしてファイルを配置することはできません。
Sudachi の ユーザー辞書ファイルや同義語辞書ファイルを配置してOpenSearchで使える様にするにはどうすれば良いか?
AWS の デベロッパガイド の Amazon OpenSearch Service のカスタムパッケージ に記載されていますが、パッケージとして、S3に配置したファイル を登録し、登録したパッケージをOpenSearchのクラスターに関連付けることで、OpenSearchのインスタンスにファイルが配置されます。
配置されたファイルはパッケージで確認できるパッケージIDやリファレンスパスを指定することで使用することができます。
目次
- 日本語形態素解析器 Sudachi インストール
- ユーザー辞書ファイルをバイナリ辞書ファイルへ変換
- OpenSearchへのユーザー辞書関連付けと結果確認
- OpenSearchへの同義語辞書関連付けと結果確認
日本語形態素解析器 Sudachi インストール
事前に、JRE(Java Runtime Environment)をインストールしておきます。
JREをインストールした後に、Sudachiをインストールします。インストール手順はSudachi の Githubに記載 があるので、手順に沿ってインストールします。
本記事ではインストール手順を省略します。
手順に記載されていますが、試しに実行した結果は下記の様になりました。
echo 国会議事堂 | java -jar sudachi-0.7.5.jar
???? 補助記号,一般,*,*,*,* ????
c 名詞,普通名詞,一般,*,*,* c
???? 補助記号,一般,*,*,*,* ????
空白,*,*,*,*,*
EOS
ユーザー辞書ファイルをバイナリ辞書ファイルへ変換
ユーザー辞書のテストファイル「user_test.csv」をSudachiのGithubからダウンロードします。
ファイルの中身
国立博物館,5146,5146,-100,国立博物館,名詞,普通名詞,一般,*,*,*,コクリツハクブツカン,国立博物館,*,C,"国立,名詞,普通名詞,一般,*,*,*,コクリツ/博,名詞,固有名詞,人名,姓,*,*,ハク/物,名詞,普通名詞,一般,*,*,*,ブツ/館,名詞,普通名詞,一般,*,*,*,カン","国立,名詞,普通名詞,一般,*,*,*,コクリツ/博,名詞,固有名詞,人名,姓,*,*,ハク/物,名詞,普通名詞,一般,*,*,*,ブツ/館,名詞,普通名詞,一般,*,*,*,カン",*,*
バイナリ辞書ファイルへ変換 「user_test.csv」→「user_test.dic」
java -Dfile.encoding=UTF-8 -cp sudachi-0.7.5.jar com.worksap.nlp.sudachi.dictionary.UserDictionaryBuilder -o user_test.dic -s system_core.dic user_test.csv user_test.csv .................... Done! (2 entries, 0.192 sec) POS table Done! (2 bytes, 0.001 sec) WordId table .................... Done! (9 bytes, 0.003 sec) double array Trie Done! (1028 bytes, 0.008 sec) word parameters Done! (6 bytes, 0.001 sec) word entries Done! (76 bytes, 1.377 sec) WordInfo offsets Done! (4 bytes, 0.001 sec)
ユーザー辞書の作成方法やバイナリ辞書ファイルへの変換コマンドについては、
Sudachi の Githubに解説 があります。
OpenSearchへのユーザー辞書関連付けと結果確認
OpenSearchへのユーザー辞書関連付けの操作をして行きます。
・ユーザー辞書のバイナリ辞書ファイルをS3へアップロードし、S3 URI をコピーして控えておきます。
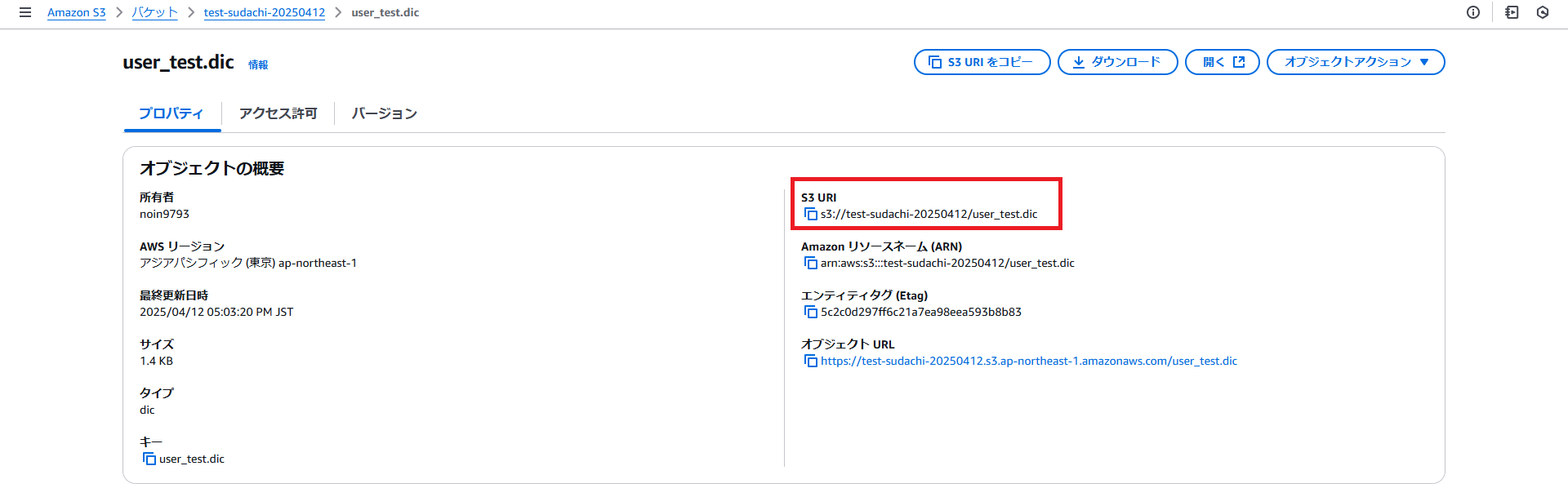
・OpenSearchの左メニューのPackagesを選択して表示された画面の「テキスト辞書」タブの「パッケージのインポート」ボタンを押下します。
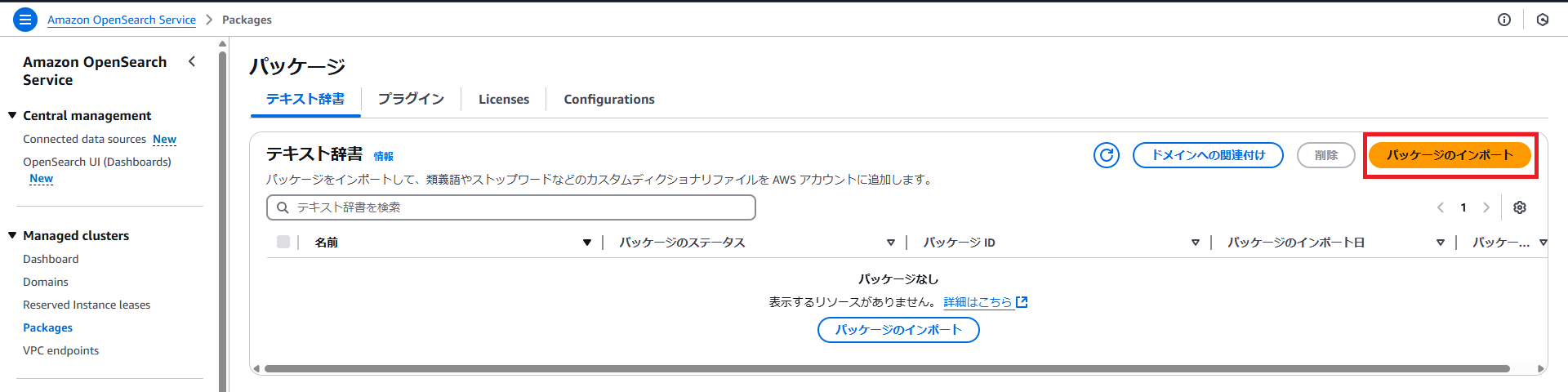
・名前は任意の値、パッケージソースに、先ほど控えたユーザー辞書のバイナリ辞書ファイルのS3 URL を入力して、「インポート」ボタンを押下します。
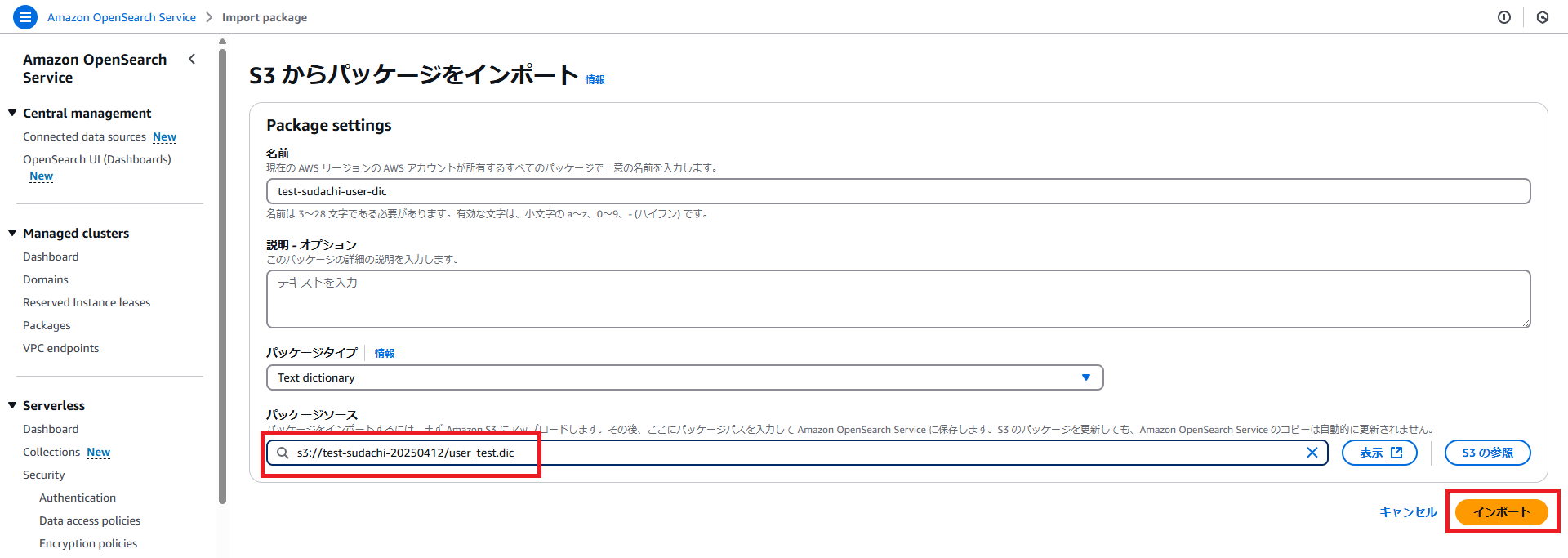
・インポート完了したら、先ほど作成したパッケージを選択して、「ドメインへの関連付け」ボタンを押下します。
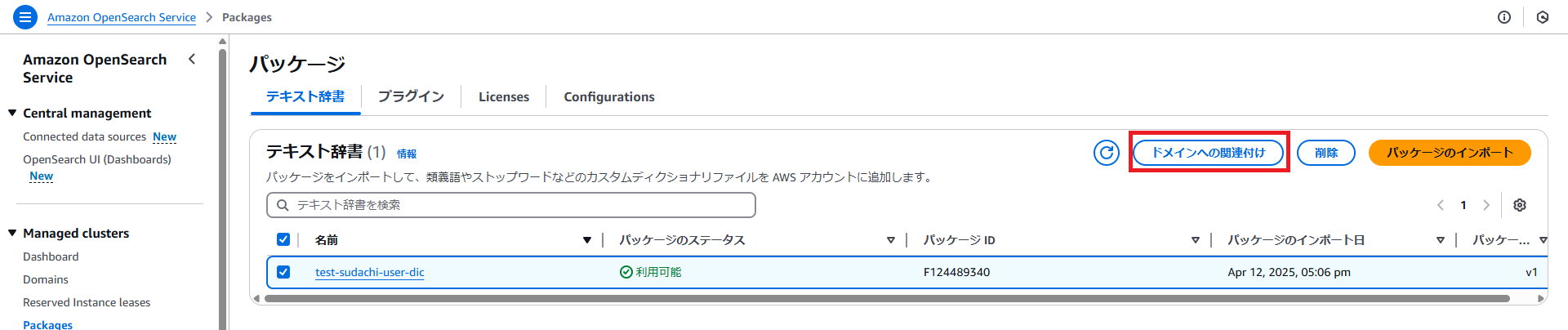
・ドメインを選択し、パッケージを選択して、「次へ」ボタンを押下します。
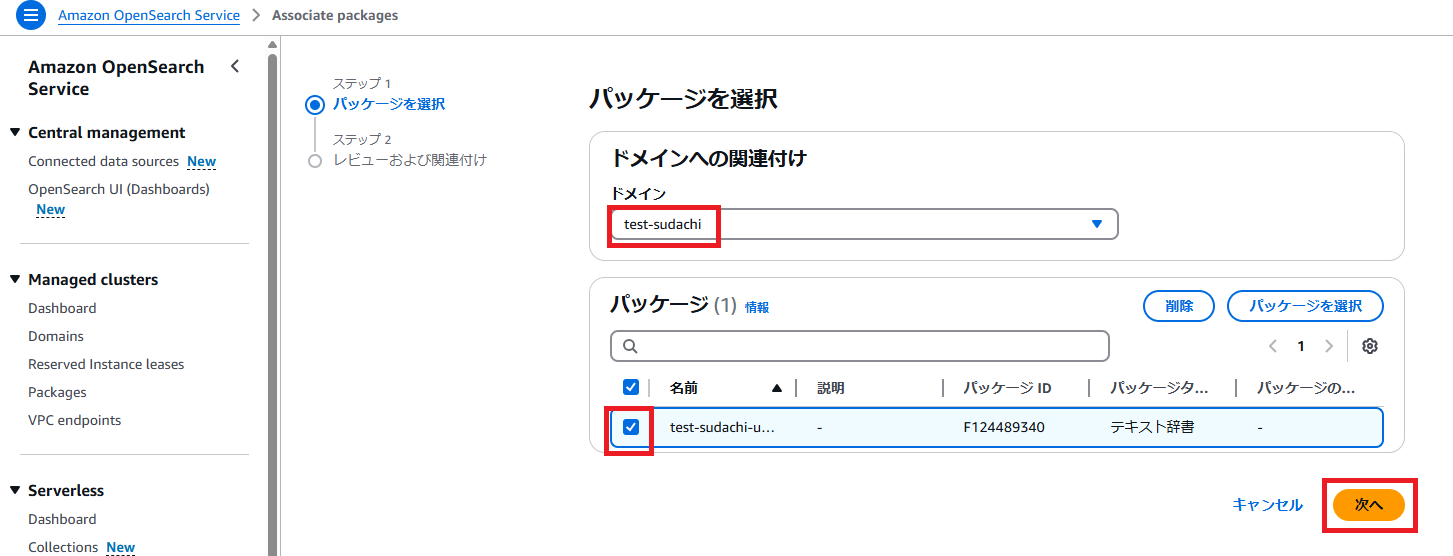
・「関連付け」ボタンを押下します。
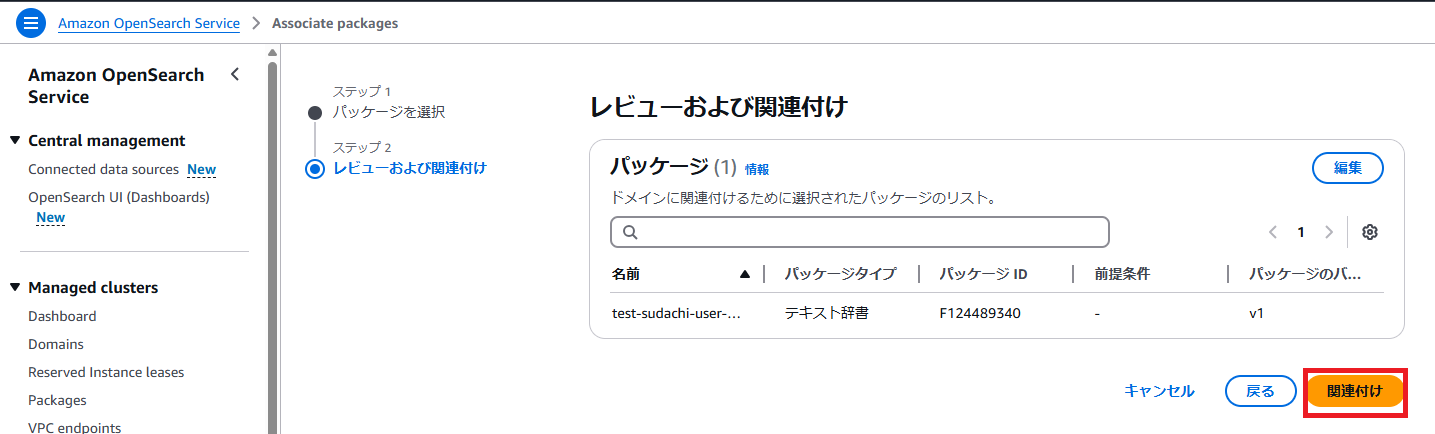
・関連付けには数分時間がかかります。関連付けが完了すると、関連付けのステータスが「アクティブ」になります。このパッケージIDをコピーして控えておきます。
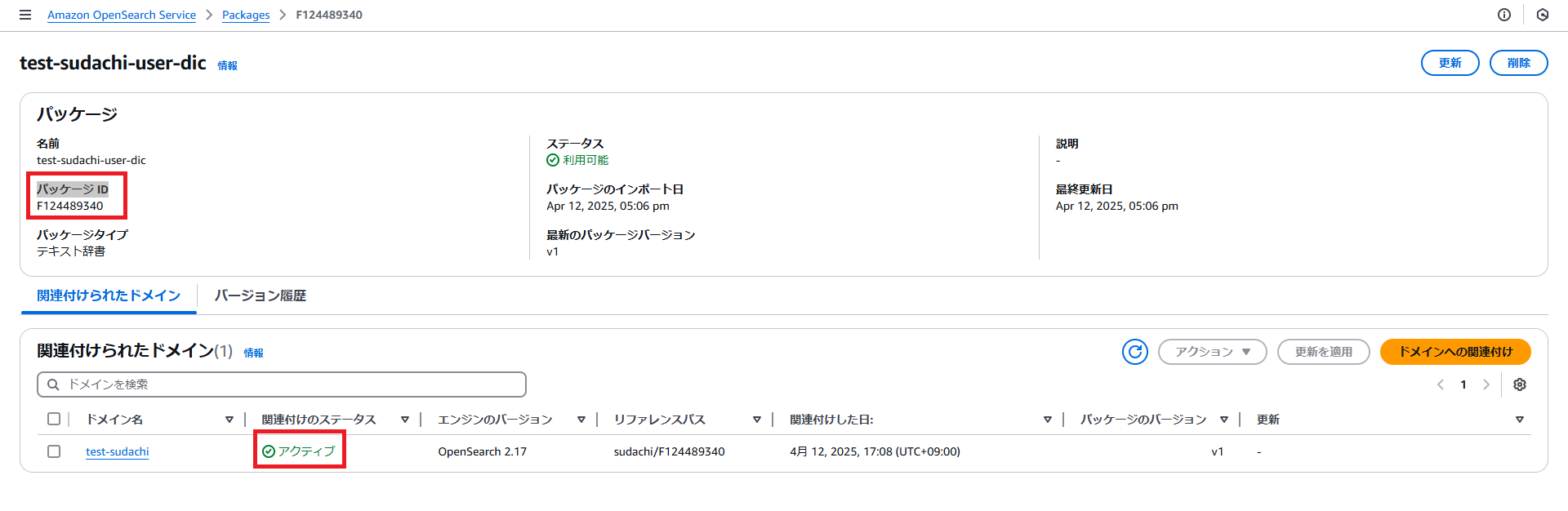
OpenSearchのDevToolsにログインして、ユーザー辞書が適用されているか確認します。
・インデクス定義
PUT /test_sudachi_user_dic
{
"settings": {
"index": {
"analysis": {
"tokenizer": {
"user_dic_not_use": {
"type": "sudachi_tokenizer"
},
"user_dic_use": {
"type": "sudachi_tokenizer",
"additional_settings": "{\"userDict\":[\"F124489340\"]}" ← ユーザー辞書はパッケージのパッケージIDを指定します。
}
},
"analyzer": {
"user_dic_not_use": {
"tokenizer": "user_dic_not_use"
},
"user_dic_use": {
"tokenizer": "user_dic_use"
}
}
}
}
}
}
・ユーザー辞書なしで解析
POST test_sudachi_user_dic/_analyze
{
"analyzer": "user_dic_not_use",
"text": "国立博物館"
}
{
"tokens": [
{
"token": "国立",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "博物館",
"start_offset": 2,
"end_offset": 5,
"type": "word",
"position": 1
}
]
}
・ユーザー辞書ありで解析
POST test_sudachi_user_dic/_analyze
{
"analyzer": "user_dic_use",
"text": "国立博物館"
}
{
"tokens": [
{
"token": "国立博物館",
"start_offset": 0,
"end_offset": 5,
"type": "word",
"position": 0
}
]
}
「国立博物館」を名詞として追加したユーザー辞書が適用されていることが確認できました。
OpenSearchへの同義語辞書関連付けと結果確認
同義語辞書ファイルの形式については、Sudachi の Githubに解説がありますが、
形式例)
000001,1,0,1,0,0,0,(),曖昧,, 1,(org), 000001,1,0,1,0,0,2,(),あいまい,, 1,(org), 000001,1,0,2,0,0,0,(),不明確,, 1,(org), 000001,1,0,3,0,0,0,(),あやふや,, 1,(org), 000001,1,0,4,0,0,0,(),不明瞭,, 1,(org), 000001,1,0,5,0,0,0,(),不確か,, 1,(org),
上記形式は、WordNet形式とのこと。
ElasticSearch Synonym token filter WordNet format
指定が難しいので、簡単なSolr形式(Solr format) で、同義語辞書ファイルを作成します。
最終行に空行があると同義語ファイルとして使用できませんでした。
曖昧,あいまい,不明確,あやふや,不明瞭,不確か
OpenSearchへの同義語辞書関連付けの操作をして行きます。
・同義語辞書ファイルをS3へアップロードし、S3 URI をコピーして控えておきます。
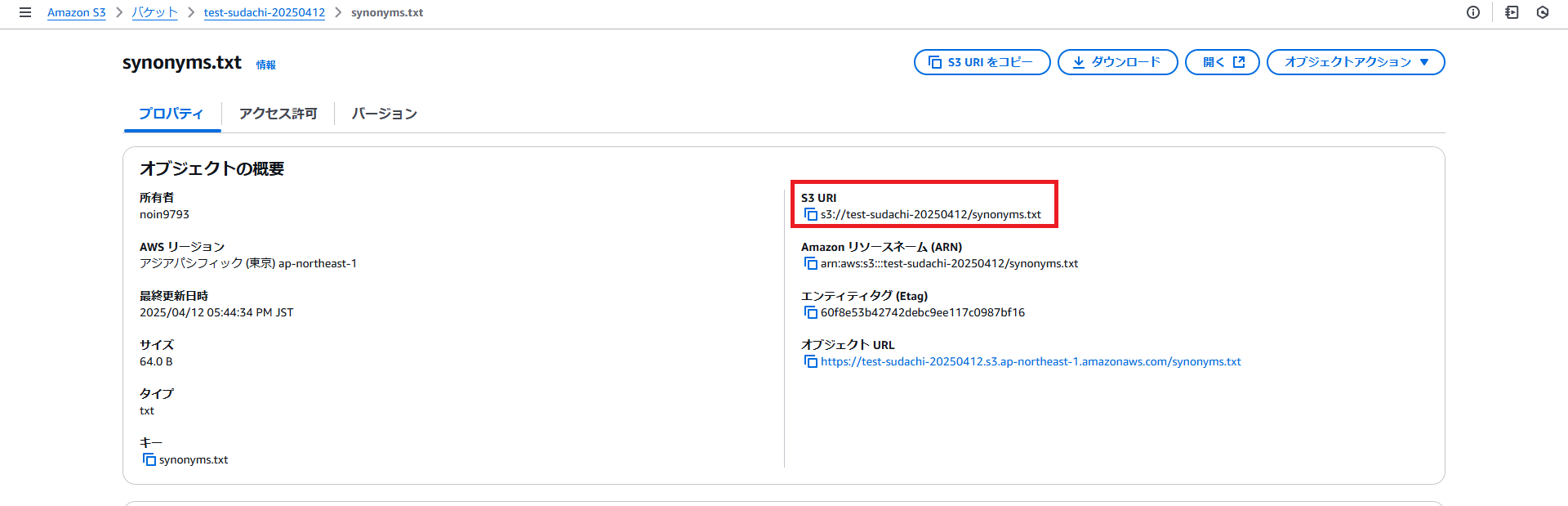
・OpenSearchの左メニューのPackagesを選択して表示された画面の「テキスト辞書」タブの「パッケージのインポート」ボタンを押下します。

・名前は任意の値、パッケージソースに、先ほど控えた同義語辞書ファイルのS3 URL を入力して、「インポート」ボタンを押下します。
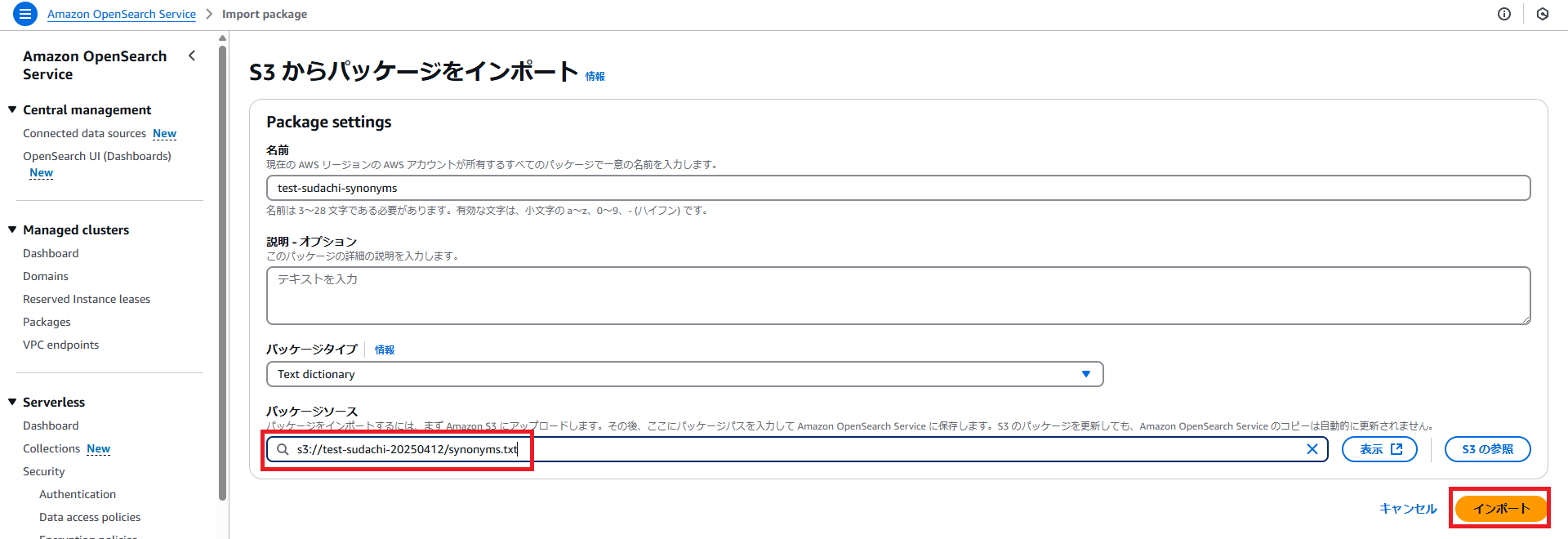
・インポート完了したら、先ほど作成したパッケージを選択して、「ドメインへの関連付け」ボタンを押下します。
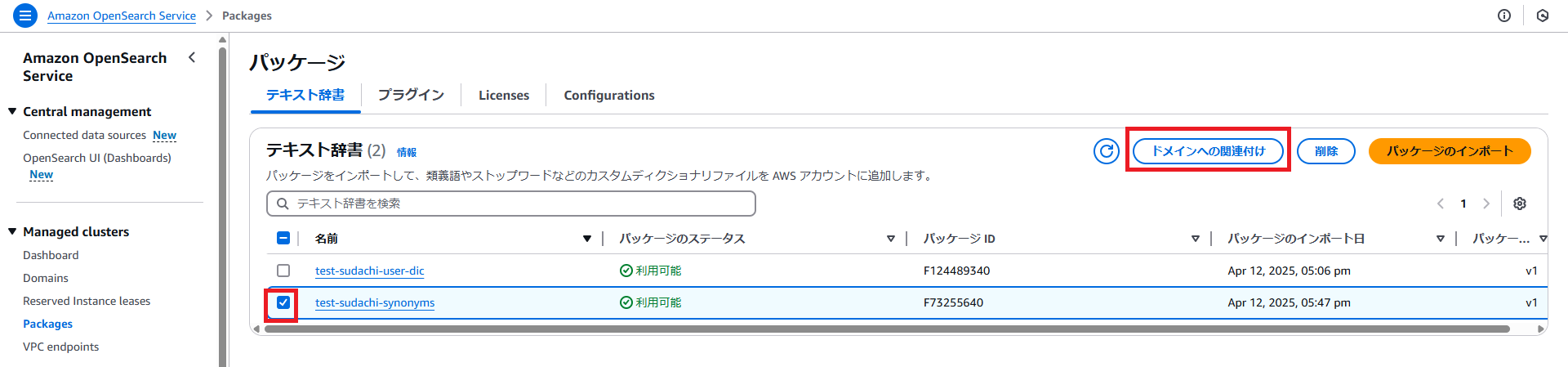
・ドメインを選択し、パッケージを選択して、「次へ」ボタンを押下します。
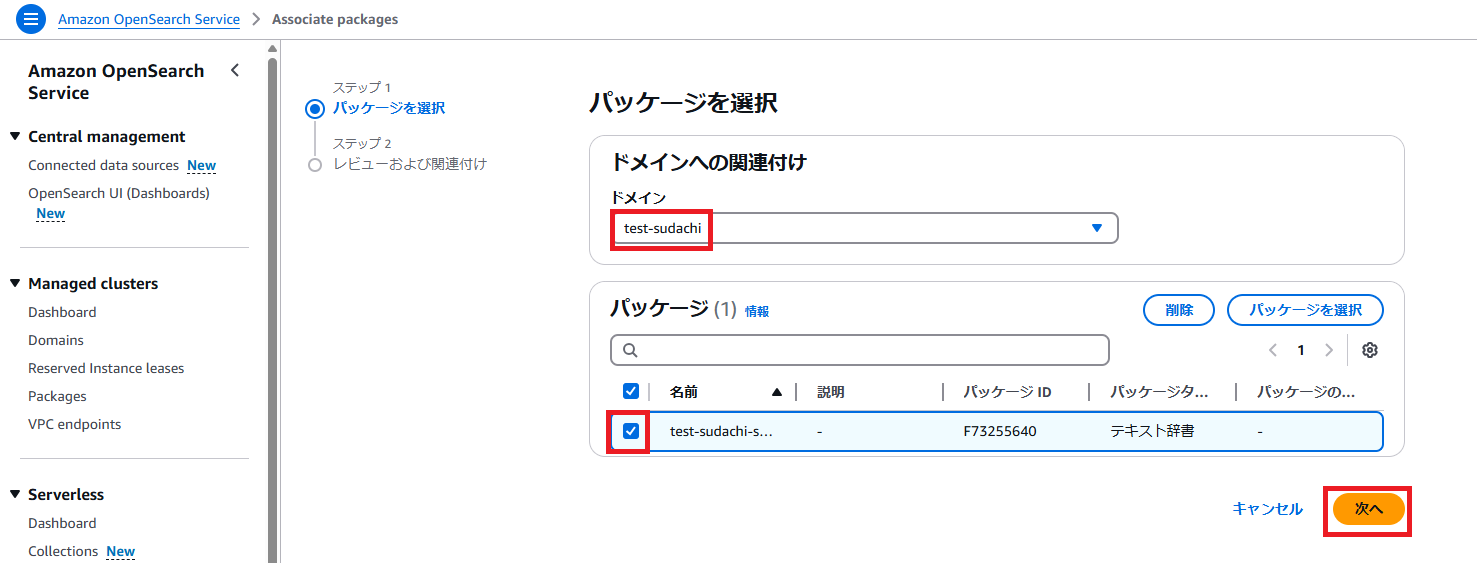
・「関連付け」ボタンを押下します。
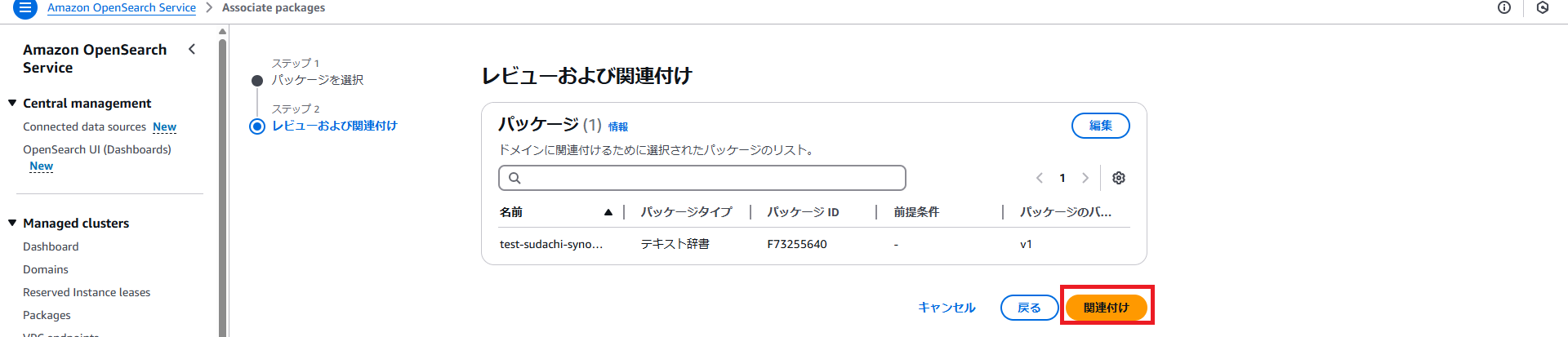
・関連付けには数分時間がかかります。関連付けが完了すると、関連付けのステータスが「アクティブ」になります。ユーザー辞書の時と違い、同義語辞書はリファレンスパスをコピーして控えておきます。
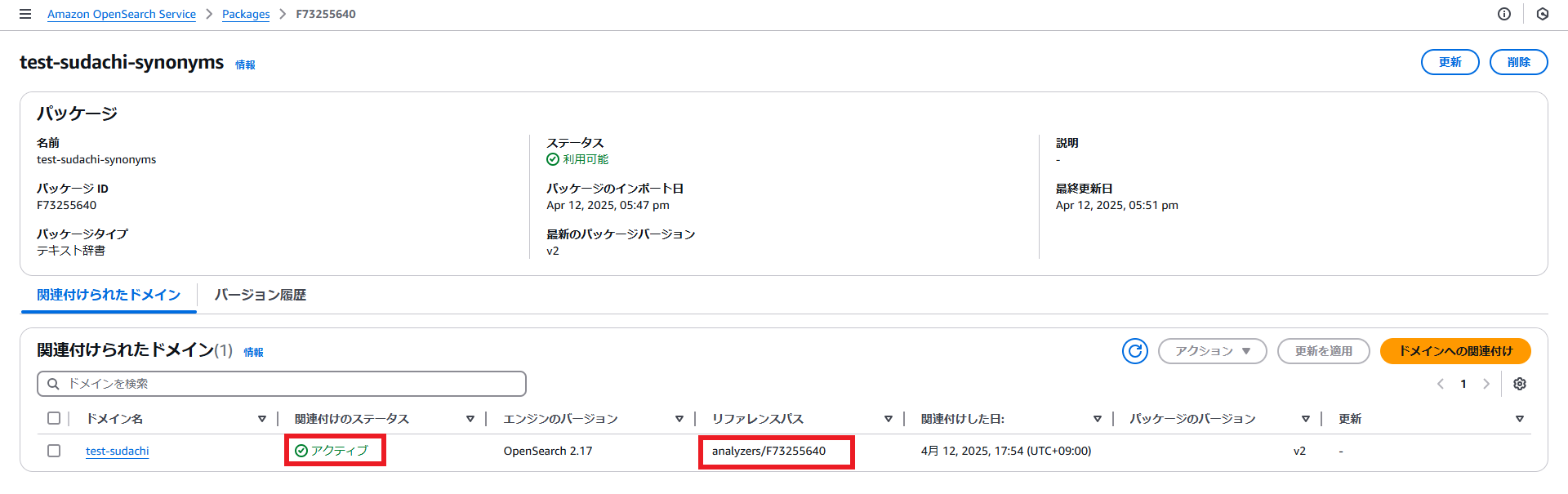
OpenSearchのDevToolsにログインして、同義語辞書が適用されているか確認します。
・インデクス定義
PUT /test_sudachi_synonyms
{
"settings": {
"index": {
"analysis": {
"tokenizer": {
"sudachi_tokenizer": {
"type": "sudachi_tokenizer"
}
},
"filter": {
"synonym_filter": {
"type": "synonym",
"synonyms_path": "analyzers/F73255640" ← 同義語辞書のパッケージのリファレンスパスを指定します。
}
},
"analyzer": {
"synonyms_not_use": {
"type": "custom",
"tokenizer": "sudachi_tokenizer"
},
"synonyms_use": {
"type": "custom",
"tokenizer": "sudachi_tokenizer",
"filter": [
"synonym_filter"
]
}
}
}
}
}
}
・同義語辞書なしで解析
POST test_sudachi_synonyms/_analyze
{
"analyzer": "synonyms_not_use",
"text": "曖昧 あいまい 不明確 あやふや 不明瞭 不確か"
}
{
"tokens": [
{
"token": "曖昧",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "あいまい",
"start_offset": 3,
"end_offset": 7,
"type": "word",
"position": 1
},
{
"token": "不明確",
"start_offset": 8,
"end_offset": 11,
"type": "word",
"position": 2
},
{
"token": "あやふや",
"start_offset": 12,
"end_offset": 16,
"type": "word",
"position": 3
},
{
"token": "不明瞭",
"start_offset": 17,
"end_offset": 20,
"type": "word",
"position": 4
},
{
"token": "不確か",
"start_offset": 21,
"end_offset": 24,
"type": "word",
"position": 5
}
]
}
・同義語辞書ありで解析
POST test_sudachi_synonyms/_analyze
{
"analyzer": "synonyms_use",
"text": "曖昧 あいまい 不明確 あやふや 不明瞭 不確か"
}
{
"tokens": [
{
"token": "曖昧",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "あいまい",
"start_offset": 0,
"end_offset": 2,
"type": "SYNONYM",
"position": 0
},
{
"token": "不明確",
"start_offset": 0,
"end_offset": 2,
"type": "SYNONYM",
"position": 0
},
{
"token": "あやふや",
"start_offset": 0,
"end_offset": 2,
"type": "SYNONYM",
"position": 0
},
{
"token": "不明瞭",
"start_offset": 0,
"end_offset": 2,
"type": "SYNONYM",
"position": 0
},
{
"token": "不確か",
"start_offset": 0,
"end_offset": 2,
"type": "SYNONYM",
"position": 0
},
{
"token": "あいまい",
"start_offset": 3,
"end_offset": 7,
"type": "word",
"position": 1
},
{
"token": "曖昧",
"start_offset": 3,
"end_offset": 7,
"type": "SYNONYM",
"position": 1
},
{
"token": "不明確",
"start_offset": 3,
"end_offset": 7,
"type": "SYNONYM",
"position": 1
},
{
"token": "あやふや",
"start_offset": 3,
"end_offset": 7,
"type": "SYNONYM",
"position": 1
},
{
"token": "不明瞭",
"start_offset": 3,
"end_offset": 7,
"type": "SYNONYM",
"position": 1
},
{
"token": "不確か",
"start_offset": 3,
"end_offset": 7,
"type": "SYNONYM",
"position": 1
},
{
"token": "不明確",
"start_offset": 8,
"end_offset": 11,
"type": "word",
"position": 2
},
{
"token": "曖昧",
"start_offset": 8,
"end_offset": 11,
"type": "SYNONYM",
"position": 2
},
{
"token": "あいまい",
"start_offset": 8,
"end_offset": 11,
"type": "SYNONYM",
"position": 2
},
{
"token": "あやふや",
"start_offset": 8,
"end_offset": 11,
"type": "SYNONYM",
"position": 2
},
{
"token": "不明瞭",
"start_offset": 8,
"end_offset": 11,
"type": "SYNONYM",
"position": 2
},
{
"token": "不確か",
"start_offset": 8,
"end_offset": 11,
"type": "SYNONYM",
"position": 2
},
{
"token": "あやふや",
"start_offset": 12,
"end_offset": 16,
"type": "word",
"position": 3
},
{
"token": "曖昧",
"start_offset": 12,
"end_offset": 16,
"type": "SYNONYM",
"position": 3
},
{
"token": "あいまい",
"start_offset": 12,
"end_offset": 16,
"type": "SYNONYM",
"position": 3
},
{
"token": "不明確",
"start_offset": 12,
"end_offset": 16,
"type": "SYNONYM",
"position": 3
},
{
"token": "不明瞭",
"start_offset": 12,
"end_offset": 16,
"type": "SYNONYM",
"position": 3
},
{
"token": "不確か",
"start_offset": 12,
"end_offset": 16,
"type": "SYNONYM",
"position": 3
},
{
"token": "不明瞭",
"start_offset": 17,
"end_offset": 20,
"type": "word",
"position": 4
},
{
"token": "曖昧",
"start_offset": 17,
"end_offset": 20,
"type": "SYNONYM",
"position": 4
},
{
"token": "あいまい",
"start_offset": 17,
"end_offset": 20,
"type": "SYNONYM",
"position": 4
},
{
"token": "不明確",
"start_offset": 17,
"end_offset": 20,
"type": "SYNONYM",
"position": 4
},
{
"token": "あやふや",
"start_offset": 17,
"end_offset": 20,
"type": "SYNONYM",
"position": 4
},
{
"token": "不確か",
"start_offset": 17,
"end_offset": 20,
"type": "SYNONYM",
"position": 4
},
{
"token": "不確か",
"start_offset": 21,
"end_offset": 24,
"type": "word",
"position": 5
},
{
"token": "曖昧",
"start_offset": 21,
"end_offset": 24,
"type": "SYNONYM",
"position": 5
},
{
"token": "あいまい",
"start_offset": 21,
"end_offset": 24,
"type": "SYNONYM",
"position": 5
},
{
"token": "不明確",
"start_offset": 21,
"end_offset": 24,
"type": "SYNONYM",
"position": 5
},
{
"token": "あやふや",
"start_offset": 21,
"end_offset": 24,
"type": "SYNONYM",
"position": 5
},
{
"token": "不明瞭",
"start_offset": 21,
"end_offset": 24,
"type": "SYNONYM",
"position": 5
}
]
}
同義語辞書を使うと、同義語で登録した単語がtype:SYNONYM で出力されていることが確認できました。
おわりに
OpenSearch に、sudachi の ユーザー辞書、同義語辞書を登録して、適用されたこと確認できました。
同義語辞書の関連付けの手順はネット上の記事にいくつかあるのですが、
ユーザー辞書の関連付け手順の記事はあまり見かけなかったので、今回投稿しました!


