
この記事のポイント : 本記事では Datadog Logs の 「収集 → 取り込み確認 → 検索/分析 → コスト最適化」 を、現場のつまずき事例と最小構成のベストプラクティスを交えて解説します。初めてログ監視を整える方、まずは“最低限を最短で”形にしたいチームにおすすめです。
はじめに
Datadog の Logs は、アプリ/ミドルウェア/OS/コンテナからのログを集約し、検索・集計・アラートを一元化できます。インシデント初動の“事実ベース”を作るうえで要となるため、最初に最低限の型を作っておくことが大切です。
私自身、SRE としてプロジェクトを進めるなかで次の課題に直面してきました。
- ログ収集はできているが検索軸(Facet)がなく分析が進まない
- 時刻ズレ/マルチライン崩れで可視化が歪む
- 低価値ログでコストが膨らむ
本記事はそれらを避けるための “最小構成の実践書”です。ゼロ→イチで使えるところまでをまとめました。
前提・動作環境
- Datadog アカウント(US/EU いずれか)
- Datadog Agent 導入済みの対象(Linux/Windows いずれか、または Kubernetes クラスタ)
- 収集対象ログの場所(ファイルパス or STDOUT)が把握できている
- タグ命名の指針:
env/service/versionを統一(例:env:prd,service:myapp)
ポイント:タグは後方互換を意識して最初に決めると運用が安定します。
ログ収集の有効化 3 ステップ(Linux / Windows / Docker・Kubernetes)
Step 1|Agentでログ機能をON
編集するファイルのデフォルト配置先(フルパス)
Linux:/etc/datadog-agent/datadog.yaml
Windows:C:\ProgramData\Datadog\datadog.yaml
# /etc/datadog-agent/datadog.yaml(Linux)
logs_enabled: true
# C:\ProgramData\Datadog\datadog.yaml(Windows)
logs_enabled: true
Step 2|ソースを定義
Linux(ファイル)
# /etc/datadog-agent/conf.d/myapp.d/conf.yaml
init_config: {}
instances:
- logs:
- type: file
path: /var/log/myapp/app.log
service: myapp
source: custom
tags:
- env:prd
Windows(ファイル/イベント)
# C:\ProgramData\Datadog\conf.d\myapp.d\conf.yaml
init_config: {}
instances:
- logs:
- type: file
path: C:\MyApp\Logs\app.log
service: myapp
source: custom
- type: windows_event
channel_path: Application
service: winapp
source: windows
Docker/Kubernetes(STDOUT)
- Docker:Agent に
DD_LOGS_ENABLED=trueを付与(必要に応じてDD_CONTAINER_INCLUDE_LOGS/DD_CONTAINER_EXCLUDE_LOGS)。 - Kubernetes(Helm):以下のとおり。
logs:
enabled: true
containerCollectAll: true
containerCollectUsingFiles: true
Step 3|取り込み確認
- Live Tail(Logs → Live Tail)でリアルタイム到着を確認します。
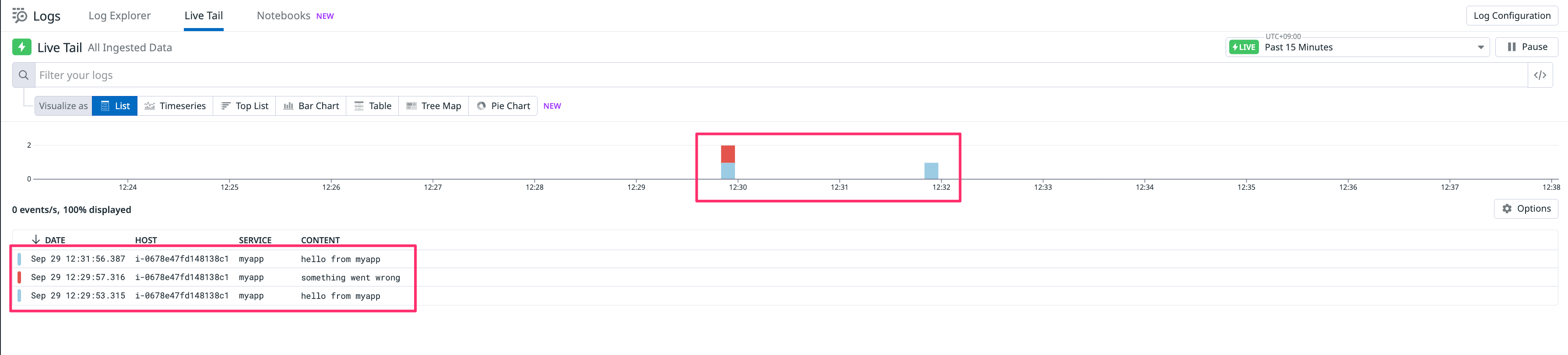
service / env で絞り込み)Tips:まずは“全部拾う” → 後から除外(Exclusion)が最短ルートです。
検索クエリの基本(コピペで使える例)
よく使うフィールド:service, env, status, host, @message, @http.status_code
直近のエラー:
status:error
サービス × 環境:
service:myapp env:prd
サービスのみで絞る(環境タグがない場合):
status:error service:myapp
HTTP 5xx:
@http.status_code:[500 TO 599]
文字列一致:
@message:"timeout"
数値条件:
@bytes_sent:>100000
@duration_ms:[1000 TO *]
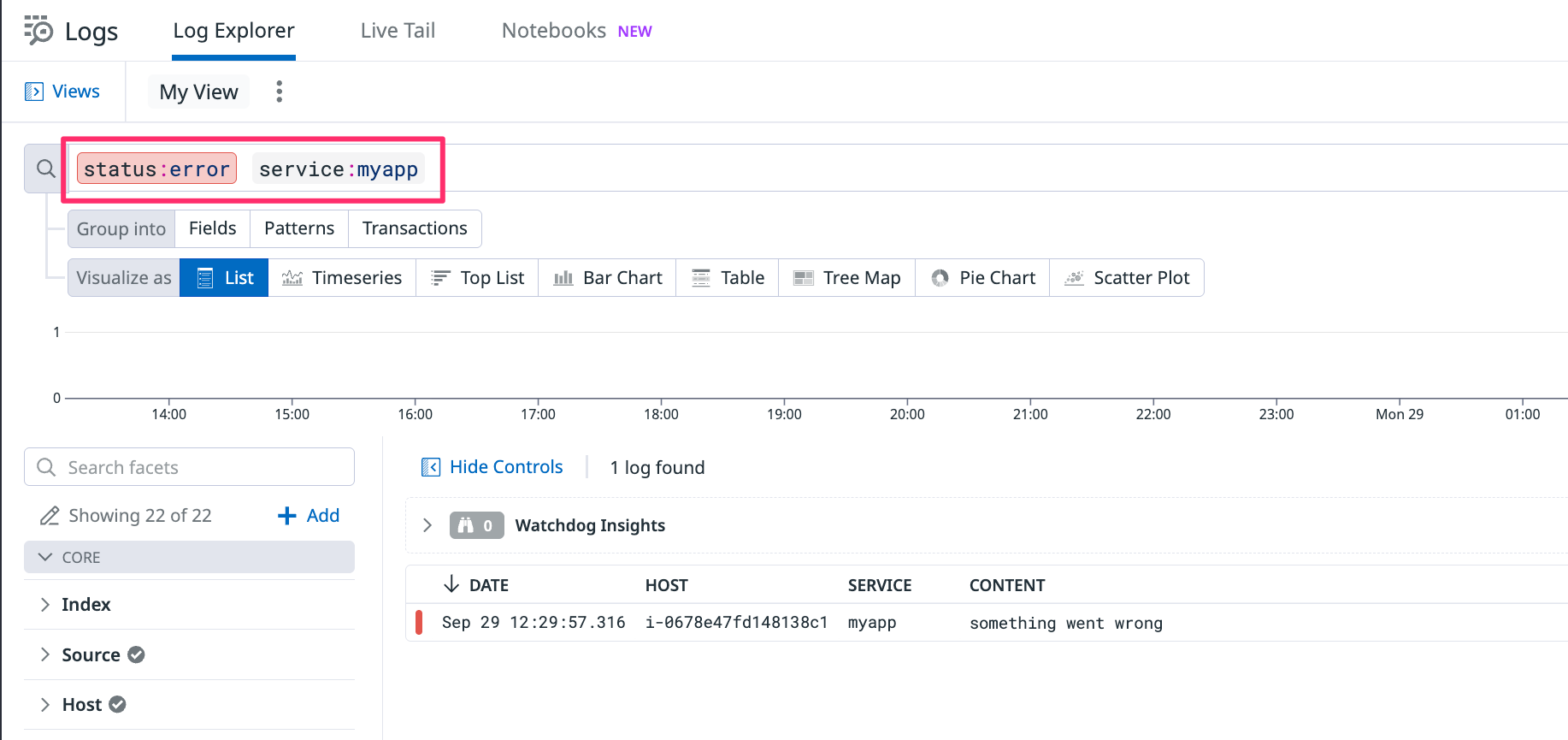
status:error と service:myapp で絞り込み)運用の型:よく使う条件は Save new view as… で“ビュー化”し、チームで共有します。
Log Explorer で集計・可視化(ログ分析)
設定は画面上部のバーから行います。Visualize as(List / Top List / Timeseries など)とGroup byを選ぶだけで、件数のランキングや時系列が作れます。
ねらい:大量のログを「数える/上位を見る/時系列で推移を見る」ために、Log Explorer の Visualize as(List / Top List / Timeseries など)と Group by を使います。公式ドキュメントではこの操作を総称してログ分析と呼びます。
Facet(ファセット)とは
- 検索や集計の“切り口”にしたい文字列属性。例:
service,host,http.path,k8s.namespace - ログ詳細のメニューから Create facet(作成済みなら Edit facet)を選ぶと、左ペインや Group by に使えるようになります(以降に届くログから有効)。
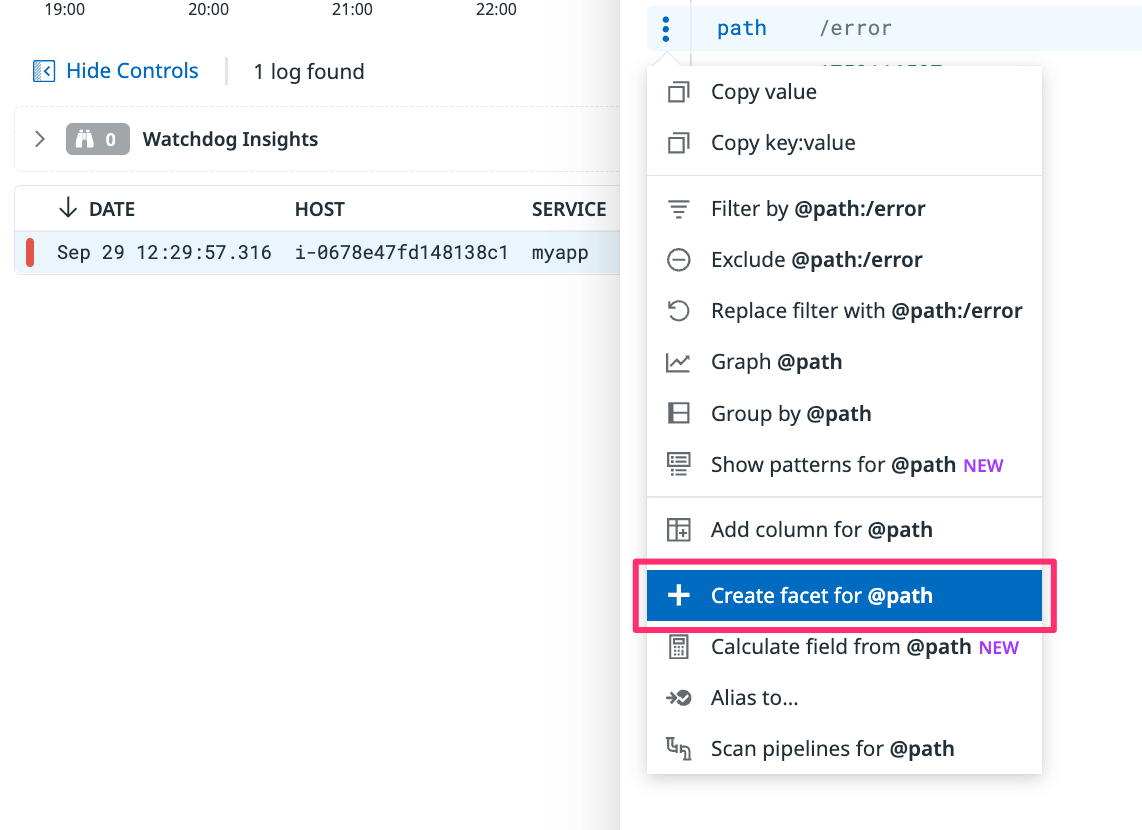
コツ:まずは
serviceとhttp.pathを Facet 化しておくと、入門の集計はほぼ賄えます。
はじめての操作(最短手順)
目的:「エラーがどのサービスで多いか」を 5ステップで可視化します(件数のランキング+時系列)。
- 検索条件を入れる:上部の検索バーに
status:error service:myappと入力。 - 表示タイプを選ぶ:画面上部の Visualize as で Top List をクリック。
- 集計の軸:Group by = service を指定(
serviceが出ない場合は、ログ詳細から Create facet を実行)。 - 並び替え:
count desc(件数の降順)。 - 推移も見る:必要に応じて Timeseries を選び、同じ条件で時間推移を確認。
このあと見えるもの:サービスごとのエラー件数の上位表(降順)と、時間推移のグラフ。増減が一目で分かります。
ミニTips:
service:myappをservice:*にすると全サービス比較に。環境で分けたいときはenv:prdを追加。
定番レシピ(まずはこの2つ)
レシピA:サービス別のエラーを見つける
- 検索:
status:error service:myapp - 可視化設定:Visualize as =
Top List、Group by = service、並び替え =count desc、(必要に応じてTimeseriesも確認) - 目的:どのサービスでエラーが多いか、増加の有無を把握します。
レシピB:エンドポイント別のログ件数トップ10
- 検索:
service:myapp - 可視化設定:Visualize as =
Top List、Group by = http.path、上位10表示、必要に応じてTimeseriesで推移も確認 - 目的:アクセス集中や特定パスの異常を把握します。
Pipeline 設計(初めては3つだけ覚える)
ねらい:検索やログ分析で使いやすいように、ログを“整形”する場所です。まずは次の3つだけで十分です。
1) Date Remapper(時刻の正規化)
- 役割:アプリが持つ日時を Datadog の
@timestampに採用。取り込み遅延やタイムゾーン差でグラフのズレを防ぎます。 - 目安:アクセスログ等で日時フォーマットが一意なら有効化。
2) Status Remapper(レベルの正規化)
- 役割:
INFO/WARN/ERRORをstatus:info/warn/errorに統一。 - 使いどころ:検索で
status:errorを使えるようにする“土台”です。
3) Grok Parser(フィールド抽出)
- 役割:テキスト行から
method/path/status/latencyなどを抜き出します。
Grok 例(Nginx)
%{IPORHOST:client_ip} - - \[%{HTTPDATE:@timestamp}\] \"%{WORD:http.method} %{DATA:http.path} HTTP/%{NUMBER:http.version}\" %{NUMBER:http.status_code} %{NUMBER:http.bytes} \"%{DATA:http.referer}\" \"%{DATA:http.useragent}\"
注意:抽出した日時をタイムラインに正しく反映させるには、Date Remapper でそのフィールドを @timestamp に採用しておくのが安全です。
運用の型:1ソース = 1パイプライン。テストサンプルを保存 → 本適用の順で進めます。
コスト最適化(まずは“置き場所”を分ける)
ねらい:必要なログだけを必要な期間だけ検索できる状態にし、コストを抑えます。
最小セット(これだけで十分スタート)
- Index / Retention:重要度ごとに保持日数を分ける(例:
prod-critical: 30d/prod-default: 7d/stg-default: 3d)。 - Exclusion:明らかなノイズ(LBヘルスチェック、冗長DEBUG行)を取り込み前に除外。
- Archive:長期はオブジェクトストレージへ。必要なら Rehydration で一時復元して検索。
- 属性の整理:巨大な属性(長大なスタックトレース等)はドロップ/短縮。
迷ったら:① Index を重要度で分割 → ② Exclusion でノイズ削減 → ③ 長期は Archive に退避。
注意:PII/認証情報はログに残さない設計にしましょう。必要な場合はマスキング/ハッシュ化を検討します。
運用フェーズのログ管理(ビュー共有/モニター化)
ねらい:日常の“入口”を決め、通知に繋げます。
ビュー共有(入口の統一)
- よく使う検索は Save new view as… で保存し、命名を統一(例:
PRD エラー調査/PRD 5xx/PRD タイムアウト)。
モニター化(自動検知)
- 重要クエリは ログモニター に(しきい値 or 異常検知)。
- Message に関連ビュー/ダッシュボードURLを貼り、一次対応の導線を用意します。
定期レビュー(軽量でOK)
- 月1回、ビューの見直しと Exclusion/属性整理の更新だけ実施します。
まとめ
ログ運用は“作って終わり”ではなく、小さく回すほど強くなります。
service/http.pathを Facet 化status:errorの ビューを1本 用意- 月1の見直し15分
この3つだけで、調査の初動がぐっと早くなりました。



