
はじめに
「システムのパフォーマンスが悪化しているけど、どこが原因か分からない…」
「便利な監視ツールとしてDatadogが良いと聞いたけど、何から学べばいいの?」
そんな悩みを抱える方に向けて、この記事を書きました。
はじめまして、MSPセクションの遠藤です。
私たちアイレットでは、お客様のIT環境を監視するツールとしてDatadogという監視SaaSを活用しています。私も業務でDatadogに触れる機会が多く、その機能の豊富さを日々実感しています。
この記事では、モダンな監視プラットフォーム「Datadog」の心臓部ともいえる「メトリクス」に焦点を当て、その種類や収集方法を、初学者の方にも理解できるようにイチから丁寧に解説します。
さらに、実際に手を動かしながら学べる簡単なハンズオンも用意しました。
この記事が、Datadogを使ったシステム監視の第一歩を踏み出す手助けとなれば幸いです
そもそもDatadogとは?
Datadogは、サーバー、コンテナ、データベース、アプリケーションなど、ITインフラ全体からデータを集約し、一元的に監視・分析できるSaaS型の「可観測性プラットフォーム」です。
ざっくり言うと、サーバーとか、アプリとか、データベースとか、ITシステムのいろんな情報をまとめてイイ感じに見える化してくれるツールです!
従来は別々のツールで管理されていたサーバーの性能監視(メトリクス)、アプリケーションのログ、パフォーマンス追跡(APM)などを、Datadog一つで分析できます。これにより、問題発生時の原因究明が圧倒的に速くなるのが大きな強みです。
日本でのユーザー会も活発で、様々な業界のユーザーが活用事例やノウハウを発信しています。
また、最近話題のS&P500の構成銘柄にも採用されるなど、ビジネス面でも大きな注目を集めています。
Datadog、S&P 500構成銘柄に採用
それだけ注目度の高いプラットフォームなんだなと思います。
システム監視の心臓部!「メトリクス」を完全に理解しよう
Datadogを使いこなす上で、まず最初に理解すべき最も重要な概念が「メトリクス」です。
メトリクスとは?一言でいうと「システムの健康診断データ」
メトリクスとは、システムの様々な状態を定量的に測定した数値データのことです。人間の健康診断で体温や血圧、心拍数を測るように、システムにおいてもCPU使用率、メモリ使用量、リクエスト数などを定期的に測定します。これらの連続した数値データがメトリクスです。
なぜメトリクスが重要なのか?
メトリクスを監視することで、システムの「体調」を常に把握できます。例えば、「CPU使用率が急に90%を超えた」というメトリクスの変化を検知すれば、ユーザーが影響を受ける前に問題の調査を開始できます。問題の早期発見、パフォーマンス改善、将来のサーバー増設計画(キャパシティプランニング)など、安定したサービス運用にメトリクスは不可欠なのです。
これだけは押さえたい!Datadogの主要メトリクス5つの種類
Datadogで扱うメトリクスは、主に5つのタイプに分類されます。それぞれのタイプがどのようなデータを扱い、システムのどんな疑問に答えてくれるのかを理解しましょう。
📈 1. Count (カウント):積み上がる「累計値」
特定の期間におけるイベントの総回数・累計値を計測する、最も基本的なメトリクスタイプです。カウンターのように値は常に増加し続けます。
これで何がわかるか?
- 「昨日1日で、このAPIエンドポイントへのリクエストは合計何回あったか?」
- 「今月、エラーは累計で何件発生したか?」
技術的な例
http.requests.count:サーバーが受け取ったHTTPリクエストの総数app.errors.count:アプリケーションで発生したエラーの累計回数
例えるなら…
コーヒーショップの1日の累計販売杯数です。営業終了後に「今日は合計で何杯売れたか」を確認するようなものです。
⏱️ 2. Rate (レート):今の「勢い・ペース」
単位時間(通常は1秒)あたりのイベントの発生頻度・ペースを計測します。システムの「今の勢い」や「負荷」をリアルタイムに把握するために不可欠です。
これで何がわかるか?
- 「Webサイトへのアクセスが急増してないか? サーバーは大丈夫か?」
- 「エラーの発生ペースは落ち着いているか? それとも悪化しているか?」
技術的な例
http.requests.rate:1秒あたりのHTTPリクエスト受信ペースapp.errors.rate:エラーの発生ペース(急増していないか?)
例えるなら…
コーヒーショップのレジの1分あたりの注文ペース。これを見ればお店の現在の混雑具合がわかります。
🌡️ 3. Gauge (ゲージ):その瞬間の「状態」
最後に受信した値をそのまま記録します。車のスピードメーターのように、その瞬間の状態を示すメトリクスです。値は上がったり下がったりします。
これで何がわかるか?
- 「サーバーのCPU使用率は今、何%か? 高負荷になっていないか?」
- 「データベースのアクティブなコネクション数は現在いくつか?」
技術的な例
system.cpu.utilization:現在のCPU使用率(%)system.memory.used:現在のメモリ使用量
例えるなら…
コーヒーマシンのディスプレイに表示されている現在の水温です。常に変動する「今の状態」を示します。
📊 4. Histogram (ヒストグラム):値の「ばらつき」
一定期間における値の統計的な分布を記録します。平均値だけでは見えないデータの「ばらつき」を把握できます。Datadogでは平均値(avg), 中央値(median), 95パーセンタイル(p95), 最大値(max)などが自動で計算され、特にユーザー体験に直結するレスポンスタイムの監視などで絶大な効果を発揮します。
これで何がわかるか?
- 「Webサイトのレスポンスタイムのp95はどのくらいか? 遅いと感じているユーザーはいないか?」
- 「ほとんどのクエリは高速だが、一部だけ極端に遅いクエリが隠れていないか?」
技術的な例
http.request.latency:HTTPリクエストのレスポンスタイムの分布db.query.execution_time:データベースクエリ実行時間の分布
例えるなら…
お客さんの待ち時間を「1分以内」「1〜2分」「3分以上」のように範囲分けして、どの待ち時間帯に何人いたかを集計するようなものです。
🌐 5. Distribution (ディストリビューション):システム全体の「分布」
ヒストグラムと似ていますが、複数のソース(ホスト、コンテナ、地域など)のデータを集約し、システム全体でのグローバルな分布を記録する点が異なります。マイクロサービスのような分散システム全体の傾向を分析するのに非常に強力です。
これで何がわかるか?
- 「全世界のユーザーで見た場合、アプリケーションの99パーセンタイルのロード時間は?」
- 「クラスター全体のサーバーで見た、CPU使用率のばらつきはどのくらいか?」
技術的な例
api.request.latency:全サーバーを横断したAPIリクエストのレスポンスタイム分布web.page_load_time:様々な地域のユーザーを横断したWebページ読み込み時間の分布
例えるなら…
ヒストグラムが一店舗の待ち時間分布だとすれば、ディストリビューションはチェーン全店舗のデータを集約して分析するイメージです。
どうやって集める?Datadogでメトリクスを収集する3つの方法
これらのメトリクスをDatadogに集めるには、主に3つの方法があります。
① Datadog Agent(最も基本かつ強力な方法)
監視したいサーバーに「Agent」と呼ばれるソフトウェアをインストールする方法です。インストールするだけで、CPU、メモリ、ディスク、ネットワークといった基本的なシステムメトリクスを自動で収集し、Datadogに送信してくれます。まずはここから始めるのが基本です。
② インテグレーション(各種サービスと簡単連携)
AWS、MySQL、Nginxなど、750以上(2024年8月時点)のサービスと連携するための仕組みが「インテグレーション」です。Datadogの画面上で数クリックするだけで、専門的なメトリクス(例:AWS RDSのDBコネクション数、Nginxの秒間リクエスト数など)を簡単に収集開始できます。
③ DogStatsDやAPI(自作アプリの情報を送る)
アプリケーション独自のカスタムメトリクス(例:会員登録数、商品の購入数など)を送信したい場合に使います。Datadogが提供するライブラリ(DogStatsD)を使えば、お使いのプログラミング言語から簡単にメトリクスを送信でき、よりビジネスに近い視点での監視が可能になります。
【ハンズオン】Datadog Agentで最初のメトリクスを可視化してみよう!
理論がわかったところで、実際に手を動かしてみましょう!ここでは、EC2にDatadog Agentをインストールして、CPU使用率を可視化するまでの流れを解説します。
Step 1: Datadogの無料トライアルに登録
まずはDatadogのアカウントを作成します。公式サイトから14日間の無料トライアルに登録できますので、気軽に試してみましょう。
Datadogではじめるモダンなモニタリング
Step 2: Datadog Agentをサーバーにインストール
アカウント登録後、Datadog AgentをインストールするOSの選択画面に遷移しますので、AmazonLinuxの場合は【Linux】を選択します。
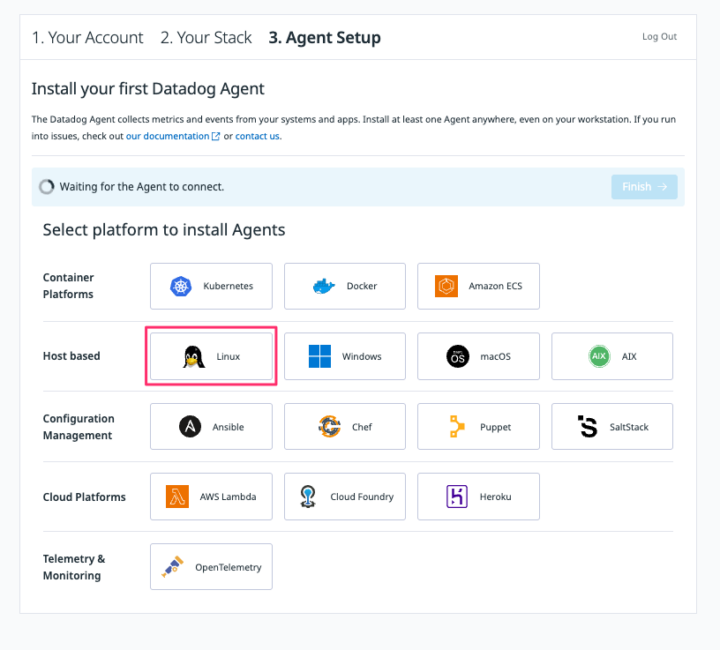
すると専用のインストールコマンドが表示されるので、それをコピーしてターミナルやコマンドプロンプトに貼り付けて実行するだけでインストールが完了します。
Step 3: ホストが認識されたことを確認
Agentのインストールが完了すると、自動的にメトリクスの送信が始まります。Datadogの左側メニューからInfrastructure > Resourceを開き、Agentをインストールしたホストが表示されていれば成功です!
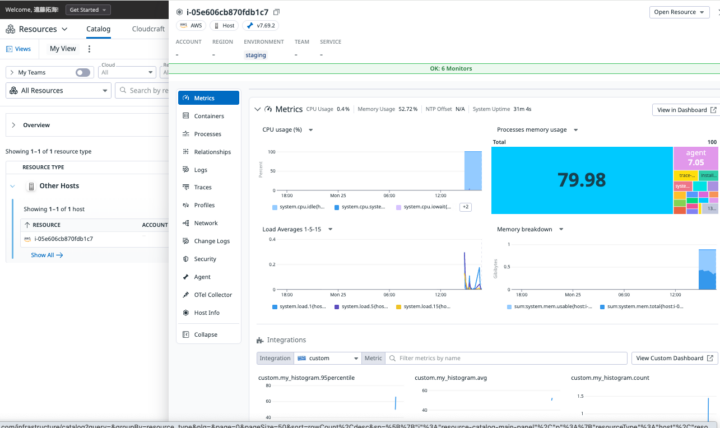
Step 4:CPU使用率をグラフで確認
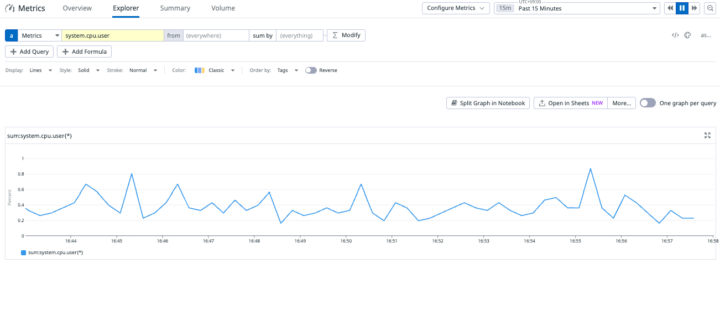
最後に、収集したメトリクスを可視化してみましょう。
- 左側メニューの
Metrisc>Explorerをクリックします。 - Metricの入力欄に
system.cpu.userと入力します。これがAgentによって収集されたCPU使用率のメトリクスです。
まとめ
今回は、Datadogの基本となるメトリクスについて一通り解説してみました。
私自身、初めてDatadogに触れたときは「メトリクス?ゲージ?レート?何が違うんだ…」と混乱した経験があります。ですが、実際にEC2にAgentを入れてCPU使用率がグラフになったのを見たとき、「こんなに簡単にメトリクスとれるのか!」感動したのを覚えています。
この記事を通して、少しでも「試しに無料アカウント作成してみようかな」と感じていただけたなら、とても嬉しいです。
最後までお読みいただき、ありがとうございました。
この記事が、あなたのDatadog学習の第一歩としてお役に立てれば幸いです。
Information
以下のような課題でお困りのお客様はぜひ当社にご相談ください。
サービス障害時にインフラ観点だけでなく、俯瞰的なボトルネック調査を行い、問題の特定・解決を早めたい
Daadog の導入は決まったものの、ノウハウもなくどうしたらいいかわからない
お客様の課題に合わせて、当社が提供するサービスをご提案させていただきます。
ぜひお気軽にアイレットへご相談ください。



