
はじめに
クラウド運用が成熟するにつれ、CSPM (Cloud Security Posture Management) は今や導入が当たり前のツールになりつつあります。
主要なクラウドサービスは自前の CSPM サービスを提供しており、有効にするだけで、数百ものチェック項目が自動で実行され、設定の不備が検知されます。また、様々なセキュリティベンダーも CSPM 製品を提供しています。
最近の CSPM 製品や、CSPM に加えて脅威検知や脆弱性管理などの様々な機能を備えた CNAPP (Cloud Native Application Protection Platform)製品は、複数のリスクを組み合わせて優先順位を付ける機能を備えており、「危険度の高い箇所から対処する」というアプローチを強力に支援します。
これは、「既にあるセキュリティ的に危険な箇所を減らす」という観点では大きな助けになりますが、「構造的に安全で効率的なクラウド環境を構築する」ことは別問題です。
後からリスクを潰すだけでは、構造的な課題は残る
CSPM で検知されたリスクに個別に対処していくだけでは、クラウド環境の根本的な改善には至りません。
- 終わりのない修正対応:新しいシステムが構築されるたびに類似のリスクが再発し、その都度、対応に追われる。
- 運用負荷の増大:過剰なアラート設定削除保護設定により運用負荷が増える。
- コストの増大:重要度の低いデータのバックアップなどによりコストが増大する。
- ガバナンスの欠如:セキュリティ対策が優先され、ビジネス要件や組織全体のガバナンスが置き去りになる。
また、構築時に IaC をスキャンしたり、Git リポジトリでマージを自動的にブロックしたりする仕組みも有効ですが、すべてのルールを画一的に適用すると、リソースの重要度にそぐわない過剰な検知が発生しがちです。
かといって、開発者に除外ルールの設定を委ねるのも、セキュリティ担当がすべての除外申請を処理するのも、双方にとって大きな負荷となりますし、セキュリティレベルの担保も困難になります。
「検知してから修正する」という事後対応のみに頼るのではなく、「そもそも検知されない設計を初期段階で組み込む」のが理想です。
AWS Well-Architected に見る「分類」の重要性
そもそも検知されない設計にするヒントが、AWS 上でシステムを構築する際のベストプラクティスである「AWS Well-Architected Framework」にあります。
このフレームワークのセキュリティの柱の中に、「データの保護」という項があります。
そこでは、「どのようなデータを扱っているか」「どこに存在するか」「誰が責任を持つか」などを把握したうえで、分類レベルに応じて暗号化・アクセス制御・保管・転送・削除を設計し適用することが推奨されています。
各データベース毎に暗号化やバックアップなどの設計をするのではなく、あらかじめデータを分類し、その分類に沿って設計や運用を行うというものです。
DLP と DSPM による自動分類の限界
分類が重要なのであれば、自動で分類してくれるツールを使えば良いのでは?と考えるかもしれません。
DLP (Data Loss Prevention) や、DSPM (Data Security Posture Management) といった、データを自動でスキャン・分類するソリューションも注目されています。
これらのツールは、データベースやストレージの内部をスキャンし、個人情報 (PII) やクレジットカード情報などを自動で検出します。「意図せず個人情報を保存してしまった」「機密情報を含むファイルが外部に送信されそうになった」といったインシデントを防ぐ上で、非常に有効な手段です。
しかし、DLP や DSPM が得意とするのは、あくまで形式的に機密と判断できるデータの検出です。
ビジネスの文脈と意図を汲み取った判断、例えば「これは社外向け資料なので Public で OK」「これはビジネス上重要な技術情報のため手厚く保護」といった判断をすべて自動化することはできません。
IaC とタグによる分類管理
データだけでなく、クラウドリソース全体に分類をあてはめる方法として、IaC (Infrastructure as Code) とタグの活用を考えてみます。
今回は、リソースを2つの軸で分類するアプローチを考えました。
軸1:データ機密度 (DataClassification)
リソースが扱うデータの機密レベルを定義します。パブリックアクセスの可否や暗号化の強度などを判断します。
| 分類 | 対象例 | 特徴 | ポリシー例 |
|---|---|---|---|
| Restricted | 個人情報、決済情報 | 法規制対象、漏洩時の影響が極めて大 | パブリックアクセス不可、顧客管理鍵での暗号化、詳細なアクセスログ必須 |
| Confidential | 個人情報以外の顧客関連情報、未公開の経営情報 | 社外秘。漏洩時のビジネス影響大 | パブリックアクセス不可、強力な暗号化、アクセスログ必須 |
| Internal | 一般的な社内文書、開発資料 | 関係者のみに公開 | パブリックアクセス不可 |
| Public | Webサイトの画像、公開ブログ記事 | 全体に公開可能 | パブリックアクセス可 |
軸2:運用特性 (OpsClassification)
リソースがどのように運用されるべきかを定義します。障害時に再構築できるのか、データを永続的に保持する必要があるのか、といった観点で分類します。
| 分類 | 特徴 | ポリシー例 |
|---|---|---|
| Critical | データやリソースの再生成が不可能または困難、障害時の影響がシステム全体に及ぶ。 | 削除保護必須 |
| Persistent | データやリソースの再生成が不可能または困難。 | バックアップ・レプリケーション必須 |
| Ephemeral | データやリソースの再生成が可能。 | バックアップ不要 |
この2つのタグを IaC のコードに明示的に記述することで、リソースの役割を定義します。
例えば、同じ S3 バケットでも、タグの組み合わせによって求められるセキュリティレベルは大きく異なります。
- DataClassification=Restricted + OpsClassification=Persistent
- 役割:顧客の個人情報を永続的に保管するS3バケット
- 適用ポリシー:バージョニング、レプリケーション、顧客管理鍵による暗号化、パブリックアクセスブロック、といった全ての要件が必須となる。
- DataClassification=Internal + OpsClassification=Ephemeral
- 役割:社内向けレポート生成のため、一時的に中間ファイルを出力するS3バケット
- 適用ポリシー:バージョニングやレプリケーションは不要。ただし、Internalなのでパブリックアクセスはブロックする。
実践:Terraform + Conftest + Sysdig でタグ別ポリシーを適用してみる
注:本記事は IaC とタグを使ったアプローチの紹介を目的としており、各ツールの使用方法については割愛します。また、リソースは S3 バケットを例に絞り、ポリシーも一部抜粋で掲載しています。
1. Terraform で AWS リソースにタグを付与する
Infrastructure as Code (IaC) ツールであるTerraformを用いて、S3バケットなどのAWSリソースに分類タグを明示的に記述します。
Confidential/Persistent バケット(アクセスログあり):機密情報 (Confidential) を永続的 (Persistent) に保管するため、アクセスログを有効化します。
# S3 Bucket - Confidential (アクセスログあり - OK)
resource "aws_s3_bucket" "confidential_bucket_with_logging" {
bucket = "test-confidential1-${random_id.bucket_suffix.hex}"
tags = {
DataClassification = "Confidential"
OpsClassification = "Persistent"
}
}
resource "aws_s3_bucket_logging" "confidential_bucket_logging" {
bucket = aws_s3_bucket.confidential_bucket_with_logging.id
target_bucket = aws_s3_bucket.access_log_bucket.id
target_prefix = "confidential-bucket-logs/"
}
Confidential/Persistent バケット(アクセスログなし):アクセスログ設定がないため、後のチェックでポリシー違反となります。
# S3 Bucket - Confidential (アクセスログなし - 違反)
resource "aws_s3_bucket" "confidential_bucket" {
bucket = "test-confidential2-${random_id.bucket_suffix.hex}"
tags = {
DataClassification = "Confidential"
OpsClassification = "Persistent"
}
}
Internal/Ephemeral バケット(アクセスログなし):社内文書 (Internal) 用の一時的な中間ファイル (Ephemeral) を扱うため、アクセスログは必須ではありません。
# S3 Bucket - Internal (アクセスログなし - OK)
resource "aws_s3_bucket" "internal_bucket" {
bucket = "test-internal-${random_id.bucket_suffix.hex}"
tags = {
DataClassification = "Internal"
OpsClassification = "Ephemeral"
}
}
2. Conftest でコードの段階で設定をチェックする
Conftest (Regoによるポリシーエンジン) をローカルで実行したり、IaCのパイプラインに組み込むことで、リソースデプロイ前にポリシーチェックを実行し、設定不備を検出します。
必須タグのチェックポリシーの例
package main
import rego.v1
target_resource_types := ["aws_s3_bucket"]
required_tags := ["DataClassification", "OpsClassification"]
valid_data_classifications := ["Restricted", "Confidential", "Internal", "Public"]
valid_ops_classifications := ["Critical", "Persistent", "Ephemeral"]
# 必須タグのチェック
deny contains msg if {
some resource in input.planned_values.root_module.resources
resource.type in target_resource_types
some tag in required_tags
not resource.values.tags[tag]
msg := sprintf("Resource '%s' is missing required tag '%s'", [resource.address, tag])
}
# DataClassificationタグ値の妥当性チェック
deny contains msg if {
some resource in input.planned_values.root_module.resources
resource.type in target_resource_types
data_classification := resource.values.tags.DataClassification
data_classification
not data_classification in valid_data_classifications
msg := sprintf("Resource '%s' has invalid DataClassification '%s'", [resource.address, data_classification])
}
# OpsClassificationタグ値の妥当性チェック
deny contains msg if {
some resource in input.planned_values.root_module.resources
resource.type in target_resource_types
ops_classification := resource.values.tags.OpsClassification
ops_classification
not ops_classification in valid_ops_classifications
msg := sprintf("Resource '%s' has invalid OpsClassification '%s'", [resource.address, ops_classification])
}
S3 バケットのアクセスログ有効化有無をチェックするポリシーの例
package main
import rego.v1
logging_required_classifications := ["Confidential", "Restricted"]
# S3バケットのアクセスログ設定チェック
deny contains msg if {
some bucket in input.planned_values.root_module.resources
bucket.type == "aws_s3_bucket"
data_classification := bucket.values.tags.DataClassification
data_classification in logging_required_classifications
not has_access_logging(bucket.address)
msg := sprintf("S3 bucket '%s' with DataClassification '%s' requires access logging", [bucket.address, data_classification])
}
# アクセスログ設定の存在確認
has_access_logging(bucket_address) if {
some logging in input.configuration.root_module.resources
logging.type == "aws_s3_bucket_logging"
# configurationセクションでbucketの参照関係をチェック
bucket_reference := sprintf("%s.id", [bucket_address])
logging.expressions.bucket.references[_] == bucket_reference
}
ポリシー違反がある場合、以下のような結果が表示され、デプロイ前に問題を修正できます。
FAIL - plan.json - main - Resource 'aws_s3_bucket.no_tags_bucket' is missing required tag 'DataClassification' FAIL - plan.json - main - Resource 'aws_s3_bucket.no_tags_bucket' is missing required tag 'OpsClassification' FAIL - plan.json - main - S3 bucket 'aws_s3_bucket.confidential_bucket' with DataClassification 'Confidential' requires access logging
3. Sysdig で作成後のリソースの設定をチェックする
リソースがデプロイされた後、CNAPP ツールである Sysdig のコンプライアンスチェック機能を使用して、実際のクラウド環境でのリソース設定を継続的にチェックします。
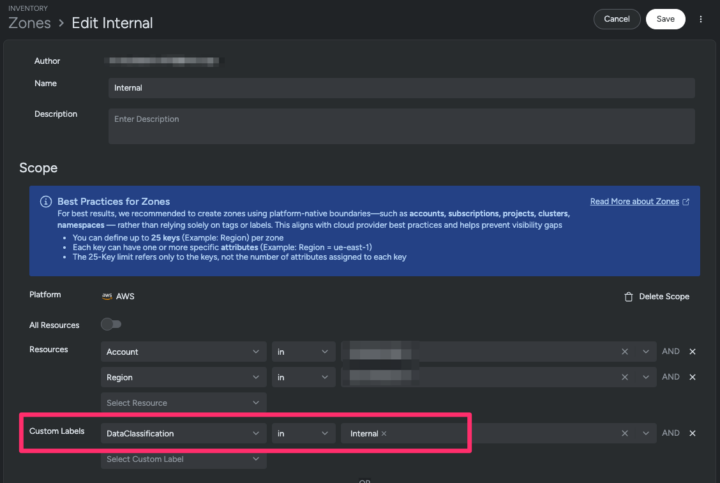
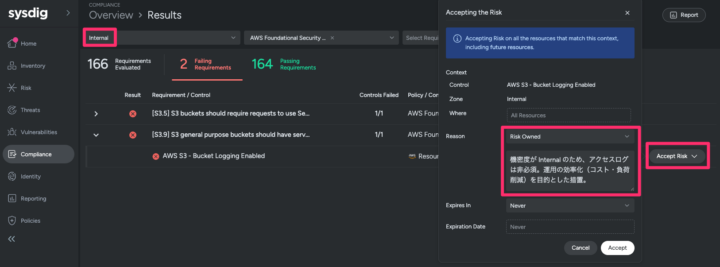
Sysdigでは、リソースに付与されたタグに基づいて Zone (リソースをまとめたグループ) を作成し、Zone 単位で検出されたリスクを許容することが可能です。
Zone の作成例
Zone 単位での Risk Accept 例
リスク許容した履歴を理由とともに確認可能
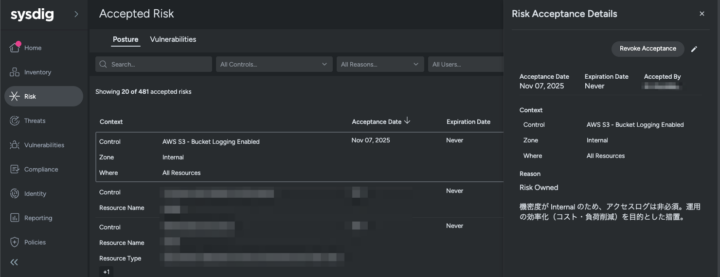
このアプローチにより、リソースの分類 (コンテキスト) に基づいた柔軟なセキュリティ管理と、ノイズの削減が可能になります。ただし、Rego や Sysdig でのこのような設定は、設定が複雑になるリスクも伴います。
課題と今後の期待
この仕組みを維持するには、タグ別のポリシーを整備し続ける運用が必要になります。ツールによるタグ別ポリシーの管理や自動生成のサポートや、AI によるポリシーの自動生成にも期待です。
おわりに
リスクを後から減らすのではなく、構造的にリスクが生まれにくい設計にするため、リソースの分類を IaC に組み込むアプローチを考えました。
このアプローチによるメリットとしては、以下が挙げられます。
- セキュリティチーム:後追い対応ではなく分類設計に集中できる
- 開発チーム:タグ付けで例外申請を不要化
- ガバナンスチーム:分類情報がそのまま監査証跡に
タグを付けることは、リソースにコンテキストを与えるということでもあります。
これまで設計書や台帳を見なければ分からなかった情報を、クラウド上の実リソースだけで理解できるようにすることは、将来的には AI エージェントがリソースの用途や目的を元に判断する助けにもなると考えています。



