
Graphify とは
最近、注目されている OSS の Claude Code スキルです(safishamsi/graphify、MIT ライセンス、GitHub スター 39k+)。コードベースをナレッジグラフ、要するにそれぞれの繋がりや関係性を持ったグラフに変換します。
Claude Code からは /graphify query "..." や /graphify path A B でグラフを検索でき、ファイルを直接全て読む事をせずにグラフ経由で回答するためtokenを大幅に節約できる効果が期待できます。
導入した背景
私が業務で関わっているプロジェクトは、複数の AWS Lambda 関数が連携する IoT データ処理システムです。横断的な仕様確認の質問をすると関連ファイルをすべてコンテキストに読み込む必要があり、token消費量が一気に膨らみます。
コンテキスト不足で質問を分割したり、毎回「このファイルを見て」と指示するのも漏れが出ることがあり、試してみたのが Graphify です。
導入対象範囲
- 複数の機器世代が存在する IoT データシステム
- AWS Lambda と Go で構成された大規模バックエンドのコード(Go 100 ファイル + 設計ドキュメント 92 ファイル)
- 上記から 888 ノード・1,414 エッジ・59 コミュニティのナレッジグラフを自動生成しました
インストール
pip install graphifyy
graphify install --platform claude注意点は graphifyy(y が 2 つ)です。
これだけで Claude Code のスキルディレクトリにインストールされ、/graphify スラッシュコマンドが使えるようになります。
スコープ選定
Graphify は 200 ファイルを超えると警告を出す設計のため、実際の開発で最もよく触るディレクトリに絞りました。絞る前は 2000 ファイルを超えていましたので、対象を 1/10 にした形です。
| ディレクトリ | ファイル数 | 選定理由 |
|---|---|---|
backend/adaptor |
34 | 各プロトコルのアダプター実装 |
backend/async |
57 | 非同期処理 Lambda 群 |
backend/eventhandler |
29 | ダウンリンクイベントハンドラ |
docs/api |
32 | API 仕様ドキュメント |
docs/datamodel |
9 | DynamoDB テーブル設計 |
docs/infra |
31 | AWS インフラ設計書 |
| 合計 | 192 ファイル |
処理パイプライン
グラフ生成は大きく 4 ステップで行われます。
- ファイル検出 — 対象ディレクトリのコード・ドキュメント・画像を検出します
- AST 抽出(コードファイル)— Tree-sitter で静的解析。LLM 不使用のため追加コストなし
- 結果:
100 ファイル → 681 ノード, 1,777 エッジ
- 結果:
- セマンティック抽出(ドキュメント・画像)— Claude がサブエージェントとして並列処理
- 結果:
92 ファイル → 223 ノード, 329 エッジ, 17 ハイパーエッジ
- 結果:
- グラフ構築・クラスタリング — Leiden アルゴリズムでコミュニティ検出
- 最終グラフ:
888 ノード, 1,414 エッジ, 59 コミュニティ
- 最終グラフ:
生成されたグラフの内容
God Nodes(最多接続ノード)
接続数の多いノードが「God Node」として識別されます。コードを読まずにグラフを見るだけでアーキテクチャの特徴が分かります。
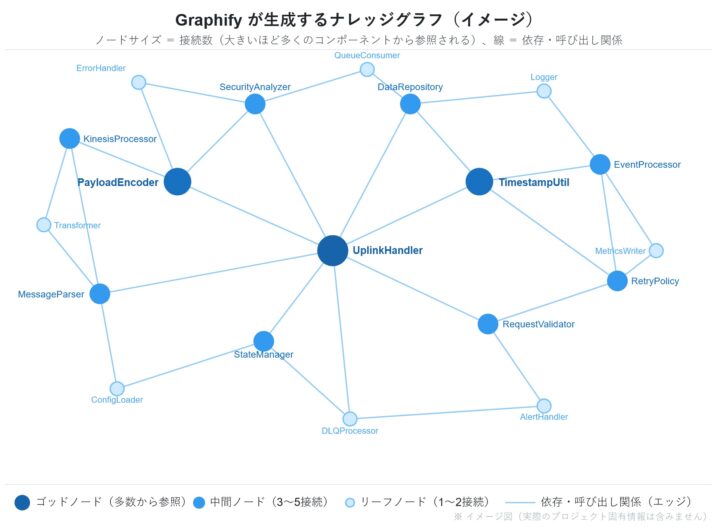
| ランク | ノード | エッジ数 | 意味 |
|---|---|---|---|
| 1 | UplinkHandler |
54 | 全 Lambda の共通エントリポイント |
| 2 | PayloadEncoder |
33 | バイナリエンコーディングのコア処理 |
| 3 | TimestampUtil |
23 | タイムスタンプ処理の共通基盤 |
ハイパーエッジ・コミュニティ
README とアーキテクチャ図を横断してデータフローが自動抽出されました。たとえば「第1世代は Dispatcher を経由するが第2世代は直接 Adapter に渡る」という設計の違いが、ドキュメントを読まずともグラフから見えるようになりました。
コードと設計書が同じコミュニティに属することで、「この Lambda は何をするか」という質問に対して実装コードと仕様書を同時に参照した回答が得られます。
token節約の計測
では、実際にtoken節約効果はあるのでしょうか?「グラフなし」は必要なファイルを実際に読んだ場合のtoken数、「グラフあり」は GRAPH_REPORT.md(6,026 token)を参照した場合です。
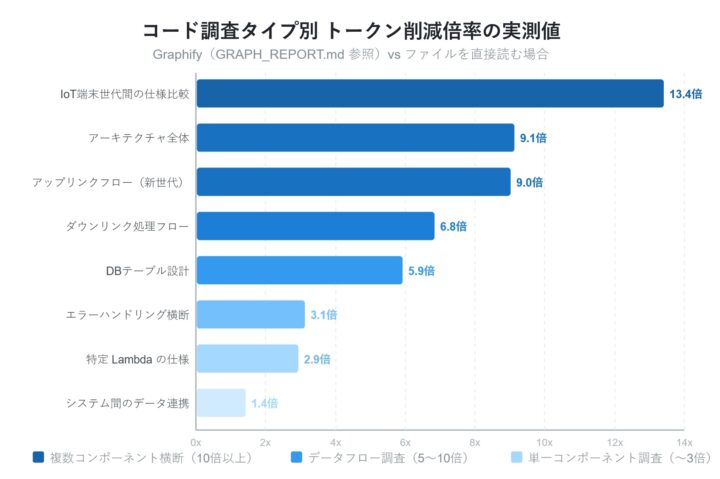
| 質問タイプ | グラフなし | グラフあり | 節約倍率 |
|---|---|---|---|
| IoT世代間の仕様比較(複雑) | 80,794 tok(21本) | 6,026 tok | 13.4倍 |
| アーキテクチャ全体 | 54,662 tok(12本) | 6,026 tok | 9.1倍 |
| アップリンクフロー(新世代) | 54,163 tok(9本) | 6,026 tok | 9.0倍 |
| ダウンリンク処理フロー | 41,107 tok(9本) | 6,026 tok | 6.8倍 |
| DB テーブル設計 | 35,730 tok(2本) | 6,026 tok | 5.9倍 |
| エラーハンドリング横断調査 | 18,586 tok(6本) | 6,026 tok | 3.1倍 |
| 特定 Lambda の仕様 | 17,577 tok(3本) | 6,026 tok | 2.9倍 |
| システム間のデータ連携 | 8,379 tok(5本) | 6,026 tok | 1.4倍 |
節約効果は質問の複雑さに比例するような結果になりました。参照ファイルが少ない単純な調査では、あまり差はないですが、複数の Lambda・ドキュメント・API 仕様書などを横断して調査する必要がある質問ほど差が開きます。
token節約は調査速度の向上にも直結する
実際に使った感じですと、tokenを節約しつつ最初から調査範囲を絞る事ができているので速度も速くなっているように感じました。速くなった要因としては以下のように考えています。
- ファイル探索フェーズがなくなる —
GRAPH_REPORT.mdを一読するだけでどこに何があるかが分かり、grep や find で探し回る手間が省けます - 1 往復で全体像が把握できる — 21 ファイルの調査が 1 往復で済み、その後必要な箇所だけ精読する流れに変わります
- コンテキストの余裕が生まれる — コンテキストの無駄を抑えることで、調査が 1 セッションで完結しやすくなります
具体的な使い方の例
/graphify query "データ受信アダプターから DB へのデータフローを説明して"
/graphify path "v2-dispatcher" "database"
/graphify explain "Handle"
/graphify backend/adaptor --update # コード変更後の差分更新(LLM 不要)まとめ
- ファイル数は 200 以下に抑える — 最初は最も必要なコア部分に絞ると良いです。後から
--updateで追加できます - 差分更新(
--update)は追加コストなし — AST 解析のみのため LLM コストが 0。ドキュメントを大幅変更した場合のみgraphify build .を検討すれば十分です - パッケージ名は
graphifyy(y が 2 つ) —graphifyは別のパッケージなので注意が必要です - 複数の Lambda 関数が絡み合うデータフローの把握や、設計書とコードの横断検索において効果が大きいと感じました。グラフは「どこに何があるか」を把握するための道具であり、実装の精読を置き換えるものではありません。そういう割り切りで使うのが正解だと思います。
- そのため「この関数のロジックはどう実装されているか」といった実装の詳細やバグ調査には、コードの直接精読がこれまで通り必要です。


