
はじめに
結論から先に書くと、AWSのAIセキュリティレビューを「設計書込み」で当ててみたら、設計書を書くこと自体が次のレビューの評価軸を作っていた、という話です。順を追って書いていきます。
最近、社内で生成AIを使ったプロダクトを作る機会が増えてきました。
私はいま MSP 監視チームで大規模障害時の対応を補助する社内ツールを開発中で、Bedrock AgentCore とか Strands Agents SDK などを使っています。
普段、社内プロダクトの開発って、私 個人ではなく、社内の開発チームに依頼するか、協働で作るケースがほとんどでした。レビューも開発フローの中で自然に入ってくる安心感がある。
でも今回はちょっと違っていて、AWS のKiroというAgentic AI IDE(エージェント型AI IDEで要件定義 → 設計 → タスク化 → 実装まで仕様駆動でサポートしてくれるタイプ) を使って、手元で spec-driven 開発しているプロダクトなんです。「個人 + AI で、どこまで品質を担保しながら開発できるか」を検証する目的もあって、いつものパターンとは違う形でスタートしています。
そうなると当然、「品質チェック」も自分で巻き取る必要が出てきます。特に AI-native なアプリって、できあがってきたコードのセキュリティレビューに困るんですよね。従来の SAST ツールに当ててみても「何をどう見たらいいか」を、いまいち手応えがない (これは私側の問題もある)。
これまで本格的なプロダクトのセキュリティ評価って、社内の専門セキュリティチームにレビューを依頼するのが通例でした。それは大事な工程なんですが、レビュアーの方々の貴重な時間も拘束してしまう(それでももちろん必要な工程には変わりない)
そこで思ったんですよね。「AI レビュアーに網羅的に見てもらうことで、専門セキュリティチームのレビューと同等か、それ以上の効果を得られないかな」と。網羅性は AI の得意領域だし、AI-native アプリの仕様理解についても AI レビュアーの方が相性が良さそう、と感じたのが背景です。
そんなときに 5 月の頭、AWS から AWS Security Agent のフルリポジトリコードレビュー機能 (Preview) が出ました。AI エージェントが設計書とコードを読んで、信頼境界やデータフローを推論しながら脆弱性を指摘してくれるやつです。
出典:
これはちょうどいいタイミングだなと思って、すぐ試してみました。Code Review と Design Review を並走させて、ハードニングして、もう 1 回 Code Review を当てる。これを 2 日でやってみたら、想像していなかった面白いことが見えてきたので、その記録を残しておきます。
なお、今回お話するのは α版パイロットに向けて品質を整えている段階での話 です。社内ツールとはいえ、本番運用前に AI レビューを通して整える、というサイクルを試した記録になります。
ちなみに強調しておくと、今回スキャン対象にしているのは、弊社内で開発している社内ツール のコードと設計ドキュメントだけ です。お客様の AWS 環境やお客様のデータは、一切スキャン対象に入れていません。社内ツールの品質を社内で整えるための検証、という位置づけで読んでもらえると嬉しいです。
ざっくり言うと
長くなりそうなので、先に結論を 3 つ書いておきます。
- 社内 GitHub Enterprise Server からでも、ちょっと工夫すれば普通に動かせます (S3 経由)
- AI-native アプリ特有の脆弱性が High confidence で出てきて、ちょっとびっくりしました
- 設計書に書いた要件が 次のコードレビューの評価軸として認識される、という閉ループが観察できました
特に 3 つ目は、書いていて少し興奮した部分です。順に書いていきます。
全体の流れ
先に「いつ何をやったか」だけ整理しておきます。記事を読みながら「あれ、これは何回目の話だっけ」とならないように。
- 1 日目 夜 — Code Review 1 回目を開始 + Design Review も並走で実行
- 2 日目 朝 — 両方の結果を読んで、突き合わせて分析
- 2 日目 日中 — 即時修正 (Task 25.X) + 設計書に Requirement を追記
- 2 日目 夜 — Code Review 2 回目 (ハードニング後) を実行
- 3 日目 朝 — 2 回目の結果を読んで、何が変わったかを確認
ざっくり 2〜3 日間の話です。AWS Security Agent には Code Review と Design Review の 2 つの機能があって、私は同じ Agent Space の中で両方を走らせました。それが後の伏線になるので、覚えておいてもらえると嬉しいです。
きっかけと、最初の壁
開発中のプロダクトは、AWS のAI サービスをいくつか組み合わせて作っている、インシデント対応の補助ツールです。具体的には Amazon Bedrock AgentCoreとか Strands Agents SDK とか Bedrock Guardrails とか、要は「AI が裏で考えてくれて、人を助けるタイプの社内ツール」だと思ってもらえれば大丈夫です。
ユーザーが触る入口の認証から、AI を動かす裏側、外部サービス (Slack / PagerDuty) との連携まで、AWS のサービスを何層にも重ねて作っています。この「層がいっぱいある」というのが、後でセキュリティレビューが面白くなった理由のひとつでした。
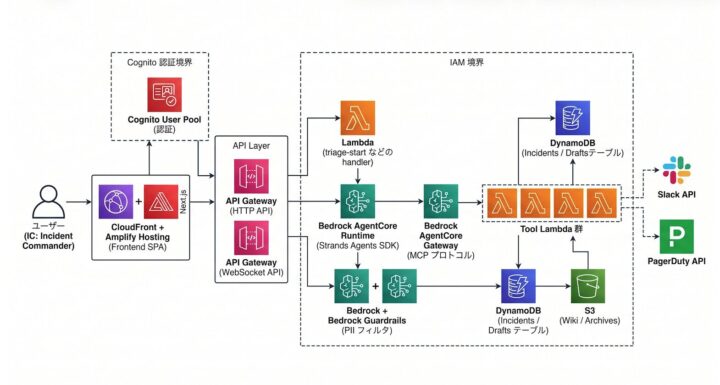
前述のとおり開発スタイルは Kiroで spec-driven です。具体的には、requirements.md / design.md / tasks.md の 3 点セットを最初にしっかり書いてから、それに沿って実装を進めるやり方。これが後半の話に効いてくるので、頭の片隅に置いておいてもらえると嬉しいです。
AWS Security Agent の発表を見て「これは試したい」と思ったんですが、最初にぶつかった壁は、社内のソースコードが GitHub Enterprise Server にある という事実でした。
公式ドキュメントを読むと、こう書いてあります。
AWS Security Agent supports both cloud-hosted GitHub and cloud-hosted GitHub Enterprise.
出典:
つまり cloud 版の GHE は対応していて、self-hosted の GHES は現時点では対象に含まれていないということです。これ、わりと同業の方が同じ壁にぶつかっていそうな気がします。
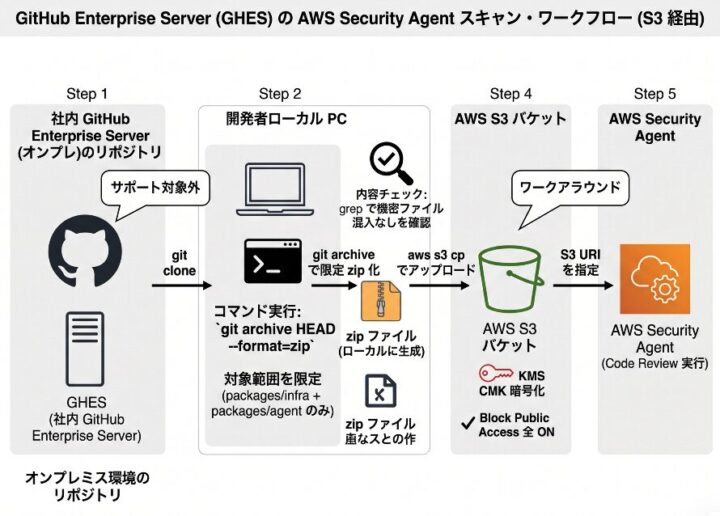
「無理か…」と一瞬思ったんですが、ドキュメントをもう少し丁寧に読んでみたら、S3 バケットをソースとして指定する経路 が用意されていました。zip を S3 に置けばそれを読んでくれる、というシンプルな仕組みです。
これは行けると思って、こんな流れを組みました。
- ローカルで
git archive HEADで対象を限定して zip 化 - 内容チェック (機密ファイルが混ざってないか grep)
- S3 にアップロード (KMS 暗号化)
- AWS Security Agent コンソールで S3 URI を指定
git archive を使うのがポイントで、これだと .gitignore で除外されているファイル (.env とか node_modules/ とか) が物理的に含まれません。安心して S3 に上げられます。
もうひとつ、これから試す方への TIPS として — Code Review 用に AWS Security Agent が作成するサービスロールに、S3 バケットと KMS キー両方への参照権限 を付けておく必要があります。KMS で暗号化した S3 バケットを使うときに、ここを見落とすと「権限不足でソースが読めません」で詰まるので、最初に設定しておくと安心です。
社外秘の設計書や、顧客情報を含む可能性のあるディレクトリは zip 化の段階で除外して、ソースコードの中核 (CDK インフラと Agent 本体) だけに対象を絞りました。
ここまでで「とりあえず動かせる目処は立った」状態。所要時間はたぶん 30 分くらいでした。
1日目: 1回目をやってみたら、思ったよりずっと深く読んでくれた
スキャンを開始すると、まずは Agent Space という入れ物が作られて、その中で 23 個のタスクが並列で走り始めました (レポート上は “Hunter” と呼ばれているので、ここからは Hunter と書きます)。面白いのが、これらの Hunter が事前定義じゃなくて、私のファイル構成を読んで動的に切り出されてくる、というところ。
実際に立った Hunter のいくつかを書き出すと、こんな感じです (AWS Security Agent のレポートより)。
- Hunter 1: Authentication & Session Management
- Hunter 4: AI Agent Orchestration — Primary & Guardrails
- Hunter 6: Prompt Configuration & Knowledge-Base Loading
- Hunter 7: Tool Lambda + EventBridge Escalation Routing
「おお、Cognito 認証とか AgentCore Runtime とか MCP Tools とか、ちゃんと別々の攻撃面として認識してるんだ」と分かって、ここで結構期待値が上がりました。
スキャンは 60 分くらいかかる見込みだったので (公式ブログの事例でもそれくらいと紹介されていました)、待っている間に Design Review (設計書レビュー) も並走させる ことにしました。これは Code Review とは別の機能で、設計ドキュメントを 3 つアップロードすると、事前に有効化しておいたセキュリティ要件と照らし合わせて評価してくれるやつです (詳しい仕組みは後で書きます)。こっちは数分で終わります。「両方の結果を翌朝突き合わせよう」と思って、寝ました。
スキャンは 67 分 で完了。検出されたのは 12 件 (High 8 / Medium 4) で、全部 High confidence の指摘でした。レポートを開いて読んでみたら、想定していたよりずっと深いところまで指摘してくれていて、正直ちょっとヒヤッとしました。
特に「これは AI ならではだな」と感じたのが、こういう指摘です。ざっくりした要約で書きます。
- AI が読み込む「知識ベース」(S3 にある社内ドキュメント) を書き換えられると、AI の動きをこっそり乗っ取られる可能性がある という指摘。AI に渡す前にテキストをチェックする処理を入れていなかったので、悪意ある文章が混ざると AI の判断がねじ曲がる、という構造になっていました。なるほど、確かに。ちょっと驚きました。
- 前の人の AI とのやり取りが、次の人に漏れちゃう可能性がある という指摘。Lambda が、効率化のために一度使った “箱” を再利用することがあって、その時に前の人の会話履歴が残ったままになる、というよくある落とし穴らしいです。同じような構成で AI 開発してる人は、心当たりあるかもしれません。
- 「PII (個人情報) フィルター動いてますよね?」と思っていたら、実は何も動いていなかった という指摘。コードを書いたときに「とりあえず仮置きで、後で本番設定する」的なコメントを残していたんですが、AI レビュアーがそのコメントまで読んで「これ、意図的にフィルター切ってますよね?」と確認してきた感じです。これは本当にヒヤッとしました(ちなみにデータはサンプルデータです)
どれも「パターンマッチ型のチェックツールでは恐らく拾えない」種類の指摘です。データの流れを追って、コードのコメントまで読んで、その上で「ここに穴がありますよ」と教えてくれる。読みながら「これは月次で回したいな」と思いました。
2日目: ハードニングして、もう一度レビューを当ててみた
1 回目の Code Review と、(後述する) Design Review の結果を踏まえて、その日のうちに即時修正タスクを 7 件 (Task 25.1 〜 25.7) 定義して、指摘された脆弱性の修正(ハードニング)しました。同時に、設計書側にも 5 つの Requirement を追記 しました。この経緯は後の「設計書を書いたら〜」のセクションで詳しく書きます。これが後で効いてくるので、覚えておいてください。
夕方には修正が一通り終わって、同じスコープで 2 回目のスキャンを走らせて、その晩のうちに結果を見ました。そして、また驚化されました。
21 件 (High 8 / Medium 11 / Low 2)。
「あれ、件数増えてる…」というのが最初の感想です。直したのに増えるって何事だと。
でも中身を読んでいくと、面白いことが分かってきました。
- 完全に消えた指摘: 2 件 (DEBUG ログレベル、IAM Wildcard) — Task 25.X で確実に修正された分
- 直したつもりが、別パスで残っていた指摘: 8 件 (元は 7 件で、1 件が 2 回目では 2 件に分かれて検出)
- 別の形に変化していた可能性のある指摘: 3 件 (1 回目では見えていたが 2 回目では消え、ただし関連する新規指摘として再表出している可能性)
- 1 回目では見えていなかった、新規の指摘: 13 件
2 回目の総数 21 件は「残った 8 件 + 新規 13 件」の内訳になっています。
「件数が増えた」という見た目だけ取り上げると怖い数字に見えるんですが、別の見方をすると、本番運用前のこの段階で 21 件を全部叩き出して、対応プロセスに乗せられている という話でもあります。あらためて書きますが、これは弊社内の社内ツールに対する内部スキャンの結果で、お客様環境への波及はゼロ件 です (前述のとおり、お客様の AWS 環境は今回のスキャン対象に入っていません)。
増えたのは「新しく出てきた」分です。そして、これらは別に AWS Security Agent が「気が向いた」とかではなくて、1 回目のときには見えなかった、もう一層深いところの問題 だったんですよね。
一番ぞっとしたのは、こういう指摘です。これも私の言葉でざっくり書くと:
AWS 側で自動生成された PII フィルター用の ID と、コード側に書いてある名前 (人間が読みやすい名前を直書きしてた) が、ズレていた。AWS の API はそういう人間用の名前を受け付けないので、フィルターの呼び出しが毎回エラーで失敗していた。結果、「フィルター動いてるはず」と思っていた処理が、全部素通りの状態だった。
…つまり、「ガードレール、動いてないですよ」と言われたわけです。設定したつもりが、設定の繋ぎ込み方を間違えていて、稼働していなかった。これも自分の知識不足が露呈した瞬間でした。
これは 1 回目のスキャンでは検出されなかった ものでした。なぜかというと、1 回目時点では check_output_guardrail() 自体が呼ばれていなかった (これが 1 回目の指摘の一つ) ので、ID 不一致が顕在化していなかったから。
直したことで、次の層の問題が見えた。玉ねぎの皮を一枚むいたら、もう一枚あった、みたいな感覚 です。
「単発スキャンの限界」と「月次運用の価値」を、ものすごく具体的な数字で見せられた瞬間でした。
設計書を書いたら、それがコードレビューの評価軸になっていた話
ここからが、書いていて一番興奮した部分です。少し時系列を巻き戻します。
2 日目の朝、1 回目の Code Review の結果と一緒に、Design Review (設計書の自動評価) の結果も出ていました。前の晩に Code Review と並走で走らせておいたやつです。これは設計ドキュメント 3 本 (design.md / requirements.md / design-brief.md) をアップロードすると、AWS コンソールで有効化した Security Requirements(AWS 管理の業界標準ベース要件 + カスタム要件)に照らして評価してくれる機能です。要件は Enable / Disable をコンソールで選択しておく仕組みで、評価自体はそれに沿って自動で走ります。
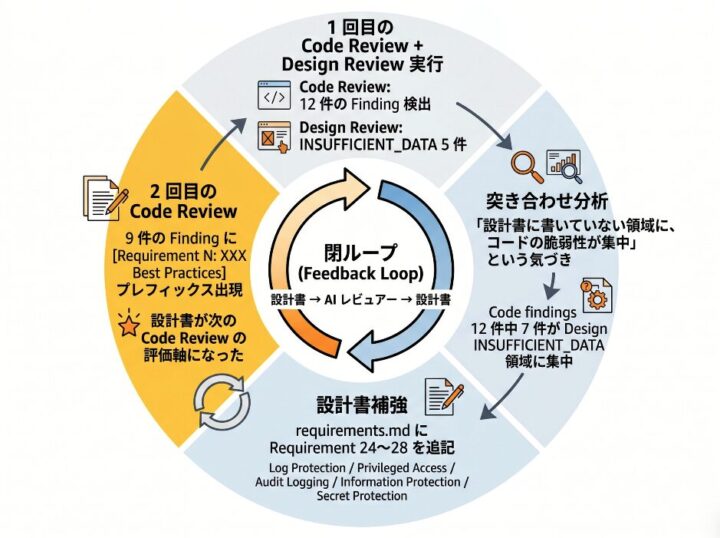
結果は「NON_COMPLIANT 0 件、COMPLIANT 3 件、NOT_APPLICABLE 2 件、INSUFFICIENT_DATA 5 件」でした。INSUFFICIENT_DATA は「設計書に書かれていなくて判断材料が足りない」という意味です。
そして、それを見ながら Code Review 側の指摘と並べてみたら、面白いことに気付きました。INSUFFICIENT_DATA 判定された 5 領域に、Code Review の 12 件の指摘のうち 7 件が集中していた んです。重なっていた領域はこんな感じでした (どちらも「データ不足 / 漏れあり」):
- Privileged Access — IAM 権限のスコープ過剰
- Information Protection — Prompt Injection 系 + Guardrail 設定の不備 (複数)
- Secret Protection — インフラ識別子の hardcode
- Log Protection — 認証トークンのログ露出リスク
「設計書に書いていないことは、実装でも漏れる」っていう、よく言われる話。それを AI が独立した 2 つのレビューで同時に裏付けてきた、という。私はこれを画面で見て、けっこう鳥肌が立ちました。
それで、同じ日の日中、ハードニング作業と並行して「じゃあ設計書にも書いておこう」と思って、設計書 (requirements.md) に Requirement 24 〜 28 を追記したんです。Log Protection、Privileged Access、Audit Logging、Information Protection、Secret Protection、の 5 領域分。Code Review で出てきた指摘を踏まえながら、設計レベルで「うちはこういう要件を満たすべきだ」と言語化したやつです。
ここで効いたのが、最初に書いた Kiro spec の存在でした。requirements.md がもともと Requirement 1 〜 23 で構成されていたので、追加するのは「Requirement 24 〜 28」と続き番号で書くだけ。spec 駆動の開発スタイルが、AI レビュアーとの相性を一段引き上げてくれた感じがします。
ここから先が、本当に面白いところです。
その日の夜に走らせた 2 回目の Code Review のレポート を翌朝開いてみたら、9 件の指摘に [Requirement N: XXX Best Practices] というプレフィックスが付くようになっていました。1 回目には、こんなプレフィックスは無かったのに、です。
つまり、「設計書に書いた要件が、次のコードレビューの自動評価軸として認識された」ということです。「Code Review → 設計書補強 → 次の Code Review が補強後の要件で評価」という閉ループ(制御工学でいう) が、文字通り回りました。
これは、ソフトウェアエンジニアリングの教科書に昔から書かれてきた「設計書はコードの仕様を決める」という命題が、AI 時代に 「設計書に書くこと自体が AI レビュアーの評価軸を定義する」 という新しい意味を持ち始めている、ということだと思います。
「ドキュメントを書く」が、いままで以上に強い行動になる。これに気付けただけでも、今回試してよかったなと思いました。
ついでに、Design Review も 2 回目を回してみた
せっかくなので、設計書を直したあと Design Review (設計書レビュー) も 2 回目を回してみました。これがまた面白い結果でした。
- 1 回目で「データ不足」と判定された 5 領域 (Log Protection / Privileged Access / Audit Logging / Information Protection / Secret Protection) が、すべて “準拠” 判定に格上げ
- 1 回目で「評価対象外」だった 1 領域 (Trusted Cryptography) も、設計書に「カスタム暗号は使わず AWS のサービスに任せている」と明示したことでAIが「AWSのマネージドサービスを利用しているため要件を満たしている(COMPLIANT)」と正しく判断できるようになった
- 一方で、1 領域 (Secure by Default) が 新たに「非準拠」判定 に格下げ
Secure by Default が “非準拠” になったのは、Phase 1 段階で許容しているリスク (MFA OFF / Bedrock Guardrails の DRAFT バージョン利用 / WebSocket JWT を URL に載せる、など) を 設計書に正直に明示していたから でした。AI から「これは “安全側がデフォルト” の状態じゃないですよね」と返ってきた感じです。
これも 玉ねぎの皮を剥いていく現象の一種 で、設計書を真面目に書くと、AI レビュアーがより深く突っ込んでくる という。隠していたら指摘されなかったかもしれないけど、書いたから見つかった。これは健全な方向の指摘だなと思いました。
設計書を書いた分だけ、レビューが深いところを見てくれる。書けば書いただけ、ちゃんと評価が返ってくる。これはやっぱり気持ちのいい体験でした。
思ったこと
2 回のスキャンを通じて、いくつか思ったことがあります。
コメントを書く文化が、AI 時代に再評価される、というのが一番大きい気づきでした。今回のレポートを読んでいると、AI が私のコードコメントを「設計判断の表明」として扱っていることが、随所で感じられたんですよね。「Phase 1 では fail-open を許容 と書いてあるので、これは意図的な判断と認識します」みたいに。
これは逆に言うと、コメントを書かないと AI に意図が伝わらない、ということでもあります。「ドキュメンテーション・ファースト」とか「型で表現する」とか、これまでも大事と言われてきましたが、AI レビュアーとの協働を考えると、「書いてあること」しか拾ってもらえない わけです。
もうひとつ、「ちゃんと直したつもりが、まだ残ってる」という現象が想像以上に難しかった という発見もありました。2 回目のスキャンで残っていた指摘 8 件のうちいくつかは、「私が修正したファイル」と「実際に動いているファイル」が微妙にズレていた、というのが原因でした。同じようなコードを 2 か所に持っていて、片方しか直していなかった、みたいな話です。
AI に「設定ファイルから逆引きして、本当に動いている方のファイルを特定しましたよ」と言われて、ぐうの音も出ませんでした。Kiroと私で 1 人 2 役で実装している中で起きやすいミスだなと、後から反省しました。
このあたりは、たぶん同じような構成で開発している方ならピンと来るんじゃないかと思います。
これからどうするか
このプロダクトでは、AWS Security Agent を まずは月次運用に組み込む 方向で検討しようと思っています。プレビュー期間中は追加料金もかかりませんし、障害対応で動くツールに対して、月 1 回フルスキャン回すのは、頻度的にもちょうどいい気がしています。
実はこの記事を書いている間に、対象範囲を広げて 3 回目のスキャンも完了しました。1〜2 回目はインフラ部分と AI まわりに絞っていたんですが、3 回目はフロントエンドや他のツール群も含めた全パッケージに広げてみたんです。対象を約 5 倍に広げたのに件数は 21 → 18 に減った ので、修正してきた効果がそれなりに効いている手応えはありました。もちろん、対象範囲が変わると評価軸も多少変わってくるので「純粋にハードニングの効果だけで減った」と言い切るのは難しいんですが、それでも方向感としては嬉しい結果でした。ただ、フロントエンド側ではまた別の種類の指摘が出てきて、玉ねぎの皮を剥いていく状態はまだ続きそう です。詳しい中身はまた別の機会に、続編として書こうと思っています。
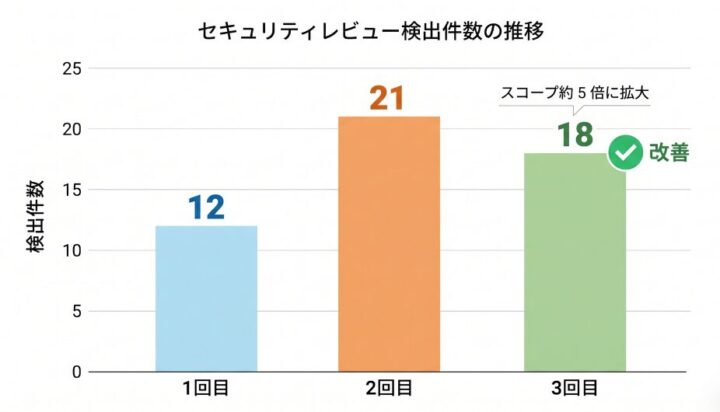
1 回目 → 2 回目 → 3 回目と並べて、件数の推移グラフが描けたら、それはそれで運用レポートとして面白いデータになりそうです。
同じような環境で開発している方 — つまり、社内 GHES でソース管理していて、Bedrock AgentCore とかで AI アプリ作っていて、レビューに困っている 方 — がいたら、ぜひ S3 経由で試してみてほしいなと思います。動かす分にはハードルは高くないので、まず 1 回当ててみるだけでも、想像していなかった指摘が見えてくると思います。
もし試した方がいたら、結果を共有しあえると嬉しいです。私もまだ手探りの最中なので、一緒に学んでいきたい感じです。
まとめ
長くなったので、3 日間で見えてきた 学び を 3 つにまとめて締めようと思います。
- 書いていないこと = AI に伝わらないこと。ドキュメントやコメントが、AI 時代の評価軸そのものになる
- 書いたこと = 次のコードレビューの評価軸になること。設計書 → コードレビューの閉ループが回り始める
- 正直に書くこと = AI がさらに深い指摘を返してくれること。隠さずに書けば、その分だけ品質が見える
「設計書を書く」が、AI 時代にこれまでとは違う意味を持ち始めている感じがします。これからもう少し回数を重ねながら、運用に組み込んでいくつもりです。
次の課題は、月次運用でどこまで品質曲線が描けるか。続編で、Frontend 含めた 3 回目以降の話と、運用に組み込んだ後の数字を書ければと思っています。


