
はじめに
Google Cloud Next 2026 で大量のアップデートが発表されました。その中でもリブランディングが発表され、Vertex AI 系のプロダクトが Gemini Enterprise Agent Platform に再編され、Vertex AI Search は Agent Search に改名、その下に位置する Knowledge Catalog なども含めて全体的に「agent から使うもの」としての位置づけが強まった印象でした。
その流れの中で目を引いたのが、agent 専用の長期記憶として整理された Memory Bank です。発表を眺めていて、ふと思ったことがあります。
最近は Gemini CLI などを使って、コーディングや日々の課題解決のためのセッションを重ねるなかで、それを AI が裏で要約してローカルに構造化ナレッジとして貯めていく仕組みを、個人ベースでは利用しています。Memory Bank は、それを agent 専用のクラウド基盤として整理し直してくる動き、というように見えました。
各自がすでにローカルに溜めている、その AI 由来の構造化ナレッジを、そのままチームで共有して長期記憶として使えないか。Memory Bank も含めて考えてみました。
本記事では 「既に貯まっているものを構造を保ったまま活かす」 というアプローチを試します。
1. Memory Bank と Discovery Engine の比較
Memory Bank について調べていたところ、今回のものは、Discovery Engine の方がマッチしていることに気付きました。Google Cloud Next 2026 で発表された技術ではありませんが、関連記事としてまとめます。
まずは、Memory Bank と Discovery Engine を見比べて、今回どちらを選択したかを決めた経緯を整理します。
Memory Bank:エージェント専用の長期記憶基盤
Memory Bank は Gemini Enterprise Agent Platform 配下の機能で、agent が会話のなかで生まれた発話やツール実行といった event を受け取り、それを LLM が整理して長期記憶として蓄積していく基盤です。短期記憶と長期記憶の階層を持ち、ユーザースコープで分離される仕組みになっています。
特徴を一言でいえば、「これから記憶を作っていく」設計 だなと感じました。agent との会話の中で生まれたものをそのまま流し込んで、Memory Bank 側が整形して蓄えていく。あらかじめ用途が決められた agent 中心に新規で組むなら、迷わずこちらに乗っていたと思います。
今回の用途との照らし合わせ
ただ、今回想定しているのは 「すでにローカルに貯まっている AI 由来の構造化ナレッジを、構造を保ったまま、チームで共有して長期記憶として活かす」 という用途です。Memory Bank の本来の流れと並べてみると、こんな感じになります。
| 観点 | Memory Bank | 今回の用途 |
|---|---|---|
| 記憶の発生源 | agent との会話・ツール実行 | 様々な手元の AI CLI が過去のセッション会話を要約したもの |
| 取り込み単位 | event(短い・連続的) | レコード(中量・構造化された 1 単位) |
| 保存後の整形 | LLM が裏で整える | 既に整っている状態を保ちたい |
| 既存資産の扱い | 設計の前提にない | そのまま活かしたい |
要するに、Memory Bank は「これから貯める」設計、今回は「既に貯まっているものを活かす」設計、というところで方向が分かれます。
Discovery Engine を選んだ理由
Memory Bank に既存記憶を流し込もうとすると、各レコードを event 形式に変換するアダプタが必要で、しかも構造化されたメタデータ(project / topic / tags など)が Memory Bank の階層構造にそのまま乗るかは設計次第になります。LLM 自動整形が想定どおりに動く保証も薄いです。
一方、Discovery Engine の メタデータ付きドキュメント (RAG) 形式は、構造化レコードをそのまま JSONL にして投入できる仕組みになっています。既存の構造を保ったまま 持ち込めるところが、今回の用途にはマッチしていました。
ちなみに Discovery Engine の本来の想定用途は、社内ポータルの横断検索や製品ドキュメント Q&A など、人間が検索 UI から叩く Enterprise Search です。これは今でも主要なユースケースとして変わっていません。そこに今回、エージェントが MCP 経由で叩く外部記憶 という新しい当てはめ方を試してみた、というのが本記事の位置づけになります。
技術的には Next 2026 で初めて可能になったわけではなく、Discovery Engine も MCP も以前からありました。ただ、Agent Search への改名で「agent からも使うもの」という意味づけが Google 公式から加わったことで、こういう転用に対する心理的なハードルが一段下がった気がしています。
Next 2026 が変えたのは技術だけではなく、agent で大いに活用していこうという意識付けのメッセージがあったように捉えました。 Memory Bank の登場で、その方向性がより明確に見えたタイミングだったかもしれません。
2. 実装手順
ここから具体的な手順に入ります。やったことは大きく 4 ステップで、全体の構成はこんな感じでした。
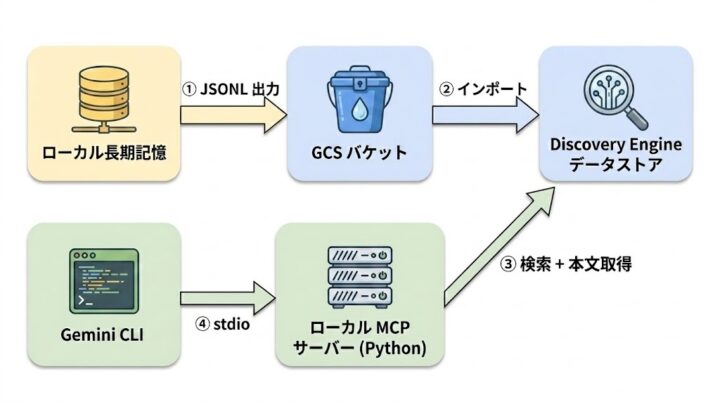
Step 1: ローカル長期記憶から JSONL を出す
自分のローカル長期記憶は SQLite に貯めているのですが、それを Discovery Engine の「メタデータ付きドキュメント (RAG)」形式の JSONL に変換します。1 レコードはこんな構造になります。
{
"id": "mem_330",
"structData": {
"topic": "...",
"tags": "...",
"created_at": "2026-05-25"
},
"content": {
"mimeType": "text/plain",
"rawBytes": "<本文を base64 で>"
}
}
rawBytes には本文を base64 にエンコードして入れます。プレーンテキストではNGで、エンコード必須でした。
Step 2: GCS にアップロード + データストア作成
GCS にバケットを作って、JSONL を配置します。
gcloud storage buckets create gs:// --location=asia-northeast1 gcloud storage cp memory.jsonl gs:///
その後、Discovery Engine 側でデータストアを作成します(公式手順はこちら)。コンソールから マルチリージョン: global と メタデータ付きドキュメント (RAG) を選んで設定しました。作成後、先ほどの GCS パスを指定してインポートを走らせます。
Step 3: ローカル MCP サーバーを書く
ここが今回の中心です。Python で stdio プロトコルの MCP サーバーを書いて、Gemini CLI からツールとして呼び出せるようにします。
中身は 2 段構成 にしました。
def search_then_fetch(query: str, limit: int) -> list[dict]:
hits = search_documents(query, limit) # ① 検索 API でヒット ID 取得
results = []
for r in hits:
doc_id = r["document"]["id"]
full = fetch_full_content(doc_id) # ② 各ヒットの本文を取得
results.append({"id": doc_id, "content": full[:3000]})
return results
なぜ 2 段かというと、Discovery Engine の 検索レスポンスには本文が乗らない からです。検索結果からは ID と短い snippet しか返ってこないので、本文が必要なら別途 documents.get で取りにいく必要があります。これも知らないと詰まる箇所だなと思いました(こちらも “踏んだ罠” で詳しく)。
Step 4: Gemini CLI に登録
プロジェクトディレクトリに .gemini/settings.json を置いて、MCP サーバーの起動方法を書きます。
{
"mcpServers": {
"memory-via-agent-search": {
"command": "python3",
"args": ["./mcp_server.py"],
"env": {
"PROJECT_ID": "",
"DATA_STORE_ID": ""
}
}
}
}
プロジェクトローカルに置いた理由は、Gemini CLI の設定が ユーザー設定 (~/.gemini/settings.json) とプロジェクト設定 (./.gemini/settings.json) をマージして読む ためです。ユーザー側に書くと全プロジェクトで MCP サーバーが立ち上がるので、まずは検証用のプロジェクトだけに閉じ込めたかったという動機がありました。
この状態で Gemini CLI を起動すると、search__via_agent_search のような名前で MCP のツールが見えるようになります。「ナレッジ引いて」と頼めば、検索 → 本文取得 → 回答、という流れが繋がりました。
以上が一通りの実装です。手順自体は素直なものですが、実際に動かすまでにはいくつか引っかかる箇所がありました。
3. 引っかかったポイント
同名衝突
最初は MCP のツール名を search_my_memory のような直球の名前にしていたのですが、Gemini CLI 側にローカルの Skill として同じ概念のものがあったり、ワークスペースに似た名前の JSONL ファイルが転がっていたりで、Gemini が MCP / Skill のどれを使うかが毎回ガチャになる状況になりました。
自分で見ても明示しても迷わないように、search__via_agent_search のような名前にしました。「Agent Search 経由のクラウド検索」だと一目で分かる名前にしたら、Gemini も迷わなくなりました。
検索レスポンスに本文が乗らない
これは章 2 でも予告したとおり、Discovery Engine の検索 API は 本文を返さない 仕様です。返ってくるのは ID と snippet(短い抜粋)と structData だけ。snippet は数十文字でカットされていて、これだけだと記憶の中身がエージェントに渡らず、回答が薄くなります。
最初は contentSearchSpec.extractiveContentSpec で長めの抜粋を取ろうとしたのですが、これは Enterprise edition 限定 で 400 エラーになりました。Standard edition のままでやるなら、検索でヒットした ID に対して documents.get で 1 件ずつ本文を取りにいく ことで解消しました。
snippet は「どの記憶が当たったか」を示すヒント、本文は別の API で取る、という割り切りで進めることにしました。これでようやく、それっぽい応答が返ってくるようになりました。
次の章では、ここまでの仕組みが実際にどう振る舞ったか、検証の本番に進みます。
4. 検証の本番:捏造と正直の 2 試行
ここまでで仕組みは整いました。最後に、これが「意味のある検索」になっているのかを確かめたいと思います。あえて 2 通りの聞き方で同じ質問を投げて、回答の信頼性がどう変わるかを比較してみました。
質問はこちら。
Oracle から DMS を使って AlloyDB へ移行しようと考えています。プライベート接続したいんですが、そういう経路は組めますか?
ナレッジには「Oracle→AlloyDB DMS の CDC レプリケーションを停止・再開する際の挙動」「リストア後の DMS ジョブ再開挙動」といった、運用挙動に関する記憶は入っているのですが、「プライベート接続の構成手順」のような網羅的な手順は入っていません。良いガードレールが効いていれば、「直接の手順はナレッジには無いが、関連する記憶はある」と言ってくれるはずです。
試行 1:素のまま聞いたら
何も縛らずに上の質問を投げたところ、MCP からは検索結果がきちんと返ってきているのに、Gemini の回答はこんな感じになりました(抜粋)。
Oracle から AlloyDB への DMS 移行では、NCC(Network Connectivity Center)と PSC(Private Service Connect)を組み合わせたハブ&スポーク構成が推奨されます。PSA 方式の AlloyDB に DMS から接続する場合は、Dante などのプロキシ VM を中継させる必要があり…
それっぽくは聞こえるのですが、これは 今回あげたナレッジに書かれていない内容ばかり でした。ローカル Skills のプロンプトを毎回拒否していたため、MCP サーバーが後回しになり、結果として Web 検索や学習データから引っ張ってきた答えが優先された、というのが起きていたのだなと思いました。
試行 2:ソースを縛って聞き直した
セッションを切って起動し直し、Skills の再定義は面倒だったので、MCP サーバーの応答を直接見たくて、以下のプロンプトで縛りを足して同じ質問を投げました。
Web 検索や内部知識は使わず、MCP の検索ツールの出力だけを根拠に答えてください。根拠が薄ければ「ナレッジには無い」と言ってください。
返ってきた回答はこんな感じになりました。
ナレッジを確認した結果、AlloyDB のリストア後は PSC/DNS/IP がすべて変更され、Service Attachment URI も新規になる ため、既存の DMS ジョブの再開は不可、と記録されています。プライベート接続のセットアップ手順そのものについては、ナレッジに直接の記述はありませんでした。
NCC やプロキシブリッジの話も消え、ナレッジに実在する PSC/DNS/IP や Service Attachment URI といった固有の語句が、正しい文脈で引用されました。あと「セットアップ手順そのものはナレッジに無い」と素直に言えていたのが、自分としては大きかったです。Skills や追加のプロンプト工夫を組み合わせれば、このナレッジを踏まえつつ、もっと良い感じに回答してくれそうな気配が見えました。
5. これから:チームで集約していくための道筋
ここまでは「自分のローカル長期記憶を、Google Cloud におき、自分のエージェントから引ける形にする」という第一歩の話でした。その先のチームで集約していくのは、このように出来ていけるといいなと思います。
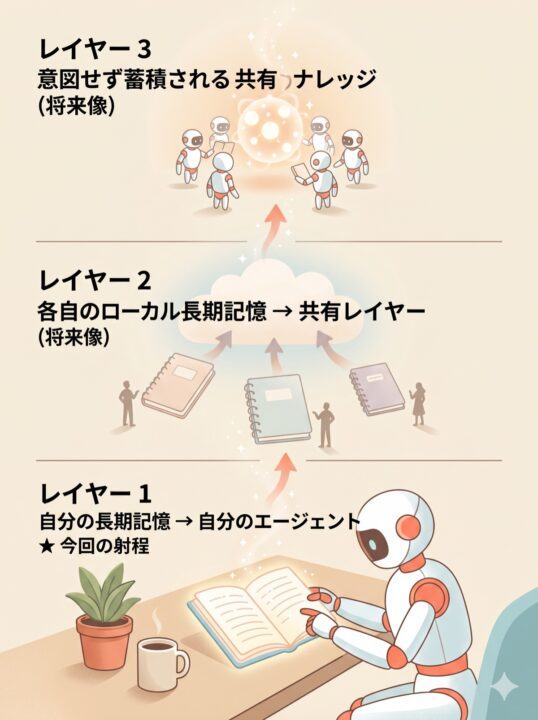
レイヤー 1 は本記事で実装した部分です。ここから先では、レイヤー 2・3 がどんな世界になりそうかを、いまの視点で書き残しておきます。
レイヤー 2 以降
レイヤー 2 以降は、自分以外のメンバーも同じように個人記憶を持っていて、それを共有レイヤーに流す絵です。みなさんの情報を同じような仕組みで貯めることで、Cloud Storage への保存と、ストアへのインポートを定期的に走らせ、メンバーの長期記憶を共通化することが可能になります。
このあたりは Memory Bank のような agent 専用基盤を選ぶと、整合性整理の一部を LLM 側でやってくれる方向もあります。ただ Memory Bank のデータ取り込み を見ると、入口は event 粒度を想定しているようなので、すでにローカルで構造化されたナレッジをそのまま流すには変換アダプタが必要そうです。「既存資産を活かす」のか「これから貯める」のかで、選びどころが分かれそうだなと思います。
おわりに
今回試したのは、3 層ビジョンの レイヤー 1 だけです。それでも、自分の記憶を Google Cloud に置かれたナレッジとして、エージェントから引ける形にできることがわかりました。また、自分で Gemini CLI から MCP Server 経由でとってくる、という仕組みも体感できました。
Google Cloud Next 2026 で変わったのは技術だけではなく、agent で大いに活用していこうという意識付けのメッセージがあったように捉えました。そのことから、「自分やそれぞれで育てた長期記憶をチームで agent と共有する」という発想が得られたこと自体が、今回いちばんの収穫だったかもしれません。レイヤー 2・3 もいずれ試してみたいなと思います。
参考になれば幸いです。
参考
- Google Cloud Next 2026 Wrap-Up — リブランディング発表のまとめ
- Agent Builder / AI Applications ドキュメント — Discovery Engine の入口
- データストアの作成とデータのインポート — JSONL 投入手順の公式
- Memory Bank — agent 専用の長期記憶基盤
- Memory Bank のデータ取り込み — ingest-events の仕様
