
この記事では、Google のマルチモーダル埋め込みモデル Gemini Embedding 2(gemini-embedding-2)を実際に動かし、テキスト1つで画像・音声・PDF を“意味”で横断検索できるかを検証します。
検証は、2026年6月5日時点の公式ドキュメントをもとに行いました。確認時点で gemini-embedding-2 は GA のモデルです。料金・提供リージョン・API 仕様は変わる可能性があるため、利用時は公式ドキュメントで最新情報を確認してください。
今回は、専用のベクトル検索基盤を組まずにどこまでいけるのかを、合成データで試しました。
これまでの検索と、何が変わるのか
社内に写真も PDF も録音した音声もあるのに、「猫について」の素材をまとめて探そうとすると、結局それぞれ別々に検索することになりがちです。理由はシンプルで、これまで 検索の“ものさし”がデータの種類ごとに別だった からです。画像には画像用のモデル、テキストにはテキスト用のモデルと分かれていて、「テキストの質問で画像を探す」には専用の仕組みが必要でした。
Gemini Embedding 2 は、テキスト・画像・音声・動画・PDF を 1つのモデルで“同じものさし”に変換 します。これにより、今回のような小規模な検証であれば、テキスト1つで種類をまたいだ検索を手元で試せます。
Gemini Embedding 2 とは
埋め込み(embedding。文章や画像を「意味を表す数値の並び=ベクトル」に変換する技術) を作るモデルです。意味が近いものは数値も近くなるので、キーワードの一致ではなく 意味の近さ で探せます。
特徴は、テキストも画像も音声も PDF も同じ意味空間(single semantic space)に配置することです。だから「ふわふわした動物」というテキストの近くに、猫の写真や、猫について話した音声などが集まりやすくなります(実際には素材の内容が質問の意図に合っているほど近くに来ます。詳しくは後半で)。これが クロスモーダル検索(種類をまたいだ意味検索) です。
主な仕様(公式ドキュメントより):
- 入力: テキスト / 画像 / 音声 / 動画 / PDF
- 出力: 既定 3,072 次元(
output_dimensionalityで 128〜3,072 に削減可) - 上限: 合計 8,192 トークン(画像6枚 / PDF6ページ / 音声180秒 など)
- 常時課金されるリソース(稼働し続けるクラスタ等)は不要で、料金は 入力内容に応じた埋め込み生成料金のみ(課金単位はテキスト・画像・音声などの入力種類で異なるため、詳細は公式 Pricing ページを参照)
検証方法(ズルをしない工夫)
検証は検証環境で行い、素材は すべて合成データ(実在の写真・他人の声・個人情報は不使用)を用意しました。
- 画像6枚: 猫×2・コーヒー×2、無関係なダミー(車・ビル)×2
- 音声2本: 猫/コーヒーを説明する日本語ナレーション
- PDF2枚: 「猫の飼い方メモ」「カフェメニュー」
- テキスト4件: 猫×2・コーヒー×2
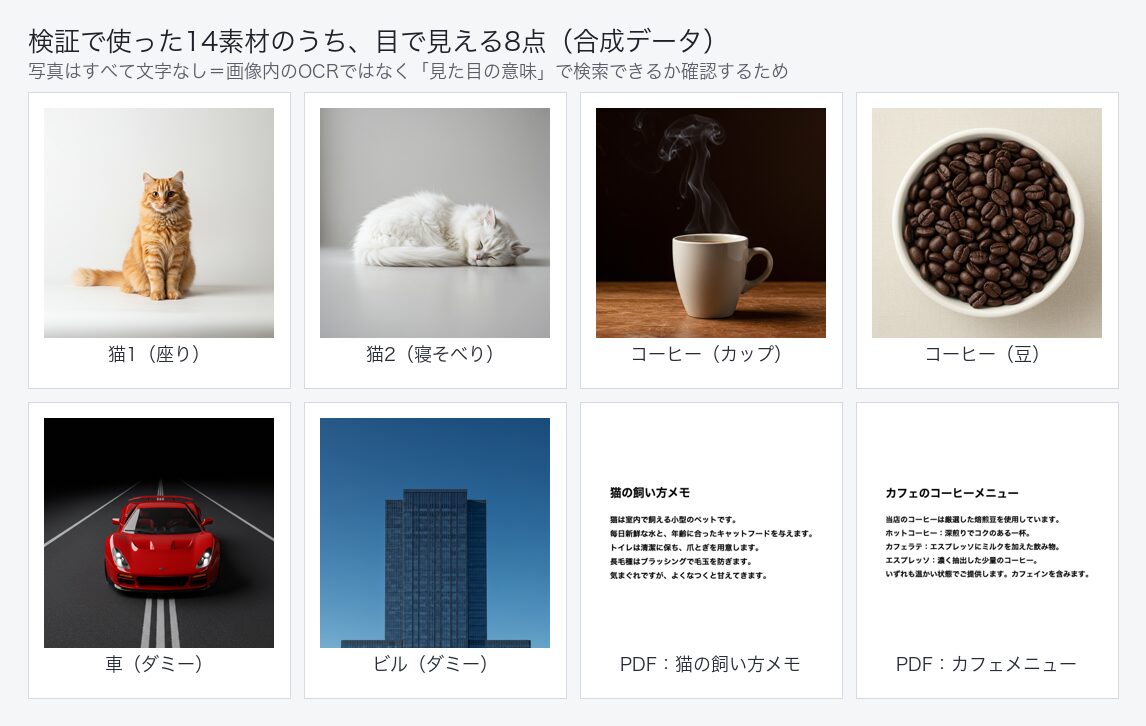
図1: 目で見える8点の素材。猫・コーヒーに加え、わざと無関係なダミー(車・ビル)を混ぜ、意味で選別できるかを見た。
結果を都合よく見せないために、2つ工夫しました。
ひとつは画像に文字を入れないことです。最初は画像に「猫」と分かる説明文字を入れようとしたのですが、これだと 画像の意味で引けたのか、画像内の文字を読んだだけ(OCR)なのか区別できません。Gemini Embedding 2 は画像内の文字も読み取れるので、画像は 文字なしの写真 にしました。これで「画像の“意味”で引けた」と言えます。
もうひとつは 無関係なダミー(車・ビル)を混ぜたことです。猫・コーヒーと関係ないものを下位に沈められるかで、意味で選別できているかが分かります。なお公式ドキュメントも「類似度は固定のしきい値で判定せず、ランキングで使うこと」としているので、評価は 順位 で見ます。
テキスト1問で画像も音声も PDF も検索できるか
合計14素材をベクトル(意味を表す数値の列)に変換し、日本語のテキストで検索しました。
やり方はシンプルで、質問と各素材の「意味の近さ」を数値にして、近い順に並べる だけです(この近さの数値を「コサイン類似度」と呼びます。仕組みは後半の実装の概要で触れます)。
いちばん分かりやすかったのが「温かい飲み物」です。
| 順位 | 類似度 | 素材 | 種類 |
|---|---|---|---|
| 1 | 0.6754 | コーヒーのテキスト | テキスト |
| 2 | 0.6550 | コーヒーの音声 | 音声 |
| 3 | 0.6304 | コーヒーカップの画像 | 画像 |
| 4 | 0.5613 | コーヒー豆の画像 | 画像 |
| 5 | 0.5405 | カフェメニューの PDF | |
| 6 | 0.5248 | コーヒーのテキスト | テキスト |
| 7〜14 | 0.50 以下 | 猫の各素材・ダミー(車・ビル) | — |
「温かい飲み物」という1つのテキストから、コーヒー関連の6素材が テキスト・音声・画像・PDF と種類を問わず1〜6位 になりました。猫の素材とダミーはすべて7位以下です。「コーヒー」という単語を含まないクエリでも、意味で引けています。

図2: 3位。湯気の立つコーヒーカップ(文字なしの生成画像)。

図3: 4位。コーヒー豆(同じく文字なしの生成画像)。

図4: 5位。カフェメニューのPDF。テキスト・音声・画像に加え、PDF も同じテキスト1問で引けている。
ここで1つ補足します。上位に来た テキスト 素材は、クエリと単語が一部重なっています(「温かい飲み物」と「コーヒーは温かい飲み物で…」)。
つまりテキスト同士のヒットには言葉の一致も混じります。いちばん強い根拠は 文字なし画像が上位に来たこと(3位のコーヒーカップ、4位の豆)で、これは OCR で文字を読んだのではなく 視覚的な意味 で引けたことを示します。
音声(2位)や PDF も、テキスト以外の入力形式を同じ検索対象にできた点でクロスモーダルです。ただし、音声は読み上げられた言語情報、PDF は文書内の文字情報が効いている可能性があります。そのため、純粋に“非テキスト”の入力を意味で引けた根拠としては、文字なし画像が上位に来たことがいちばん分かりやすい、という整理になります。
ほかのクエリでも、
- 「カフェインのある飲み物」→ コーヒー6素材が1〜6位
- 「ペットにかわいい生き物」→ 猫6素材が1〜6位
と、4つ試したうち3つで「同テーマの全素材が他テーマ+ダミーより上位」という完全分離になりました。
実装の概要
今回のような小規模な検証であれば、専用のベクトル検索基盤を用意しなくても試せます。各素材のベクトルを作り、クエリのベクトルと近さを比べて、近い順に並べるだけです。
- API は
embedContent1本です。テキストでも画像でもファイルでもcontent.partsに入れて投げます。 - リージョンは東京(
asia-northeast1)では提供されておらず、global/us/euを使います(今回はus)。エンドポイントのホストに.repが入る点も従来モデルと違います。 - ファイルは Cloud Storage を経由せず インライン(base64 で直接埋め込む) で渡せます。今回は画像・音声・PDF すべてインラインで通りました。保存先バケットや権限の設定がいりません。
- 検索する側のテキストには
task: search result | query: ...という指示(タスクの指定文)を添えると、検索用途に最適化されます。 - 逆に 検索対象のテキスト文書側 は、公式では
title: {タイトル} | text: {本文}形式が推奨されています。今回はそのまま投入しても問題なく動きましたが、実務でテキスト文書を多く検索対象にするなら、この形式に揃えておくのが無難です。
テキストクエリと、インラインで渡した画像の埋め込みを取る REST の例です。
PROJECT_ID="YOUR_PROJECT_ID"
LOCATION="us" # 東京(asia-northeast1)は提供外。us / global / eu を使う
URL="https://aiplatform.${LOCATION}.rep.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/publishers/google/models/gemini-embedding-2:embedContent"
# テキストクエリの埋め込み
curl -s -X POST -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \
-H "Content-Type: application/json" \
-d '{ "content": { "parts": [ { "text": "task: search result | query: 温かい飲み物" } ] } }' \
"$URL"
# 画像(インライン base64)の埋め込み
IMG_B64=$(base64 < coffee.png | tr -d '\n')
curl -s -X POST -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \
-H "Content-Type: application/json" \
-d "{ \"content\": { \"parts\": [ { \"inline_data\": { \"mime_type\": \"image/png\", \"data\": \"${IMG_B64}\" } } ] } }" \
"$URL"
返ってきたベクトル同士の「意味の近さ」を計算し、近い順(似ているものほど上)に並べれば検索結果になります。この近さを測る定番のものさしが コサイン類似度 で、2つのベクトルが似た向きかを表す数値です(1 に近いほど意味が近い)。
今回の検証では、返ってきたベクトルをそのまま使ってコサイン類似度を計算し、近い順に並べることで検索結果を作れました。実際のサービスで使う場合は、保存先のベクトルDBや検索方法によって扱いが変わることがあります。特に、output_dimensionality で次元数を変える場合や、別の検索エンジンに入れる場合は、必要に応じてベクトルの正規化を確認しておくと安心です。
ハマりどころ:意味がズレると順位は落ちる
便利な一方で、意味で引く仕組みならではのクセも出ました。
4つ目の「ふわふわした動物」では、猫のテキスト・音声・画像は上位に来たのに、「猫の飼い方メモ」PDF が10位 まで沈み、コーヒーの音声やダミーの車画像より下になりました。

図5: 10位だった「猫の飼い方メモ」PDF。本文は水・餌・トイレ・ブラッシングといった世話の手順で、「ふわふわ」という見た目の言葉とは意味が少しズレている。
理由を見ると腑に落ちます。この PDF の本文は「水・餌・トイレ・ブラッシング」といった飼い方の話で、“ふわふわ”という 見た目 の言葉とは意味が少しズレています。
埋め込みは文字の一致ではなく意味の近さで引くので、同じ「猫」でも 中身が質問の意図とズレると順位が落ちます。
これは壊れているのではなく、素直な挙動です。実務で使うなら、しきい値で機械的に切らず順位で見る・引けないときは素材の中身と質問の意味がズレていないか疑う・重要な用途では上位を人が確認する、といった運用が前提になります。
まとめ
- 小規模なら専用基盤なしでクロスモーダル検索を試せる: 1モデルで全種類のデータを同じ意味空間に置くので、テキスト1つで画像・音声・PDF を横断的に引けました。常時課金のリソースは不要で、ファイルはインラインで渡せます。
- よくある検索は実用レベル: 4クエリ中3つで、同テーマの全素材が他テーマ+ダミーより上位になりました。
- 意味で引く以上、鵜呑みにはしない: 質問と文書の意味がズレると順位が落ちます。固定しきい値で判定せず、順位で見て、必要なら人が確認するのが前提です。
派手さはありませんが、今回のような小規模な検証なら、「画像は画像、音声は音声で別々に探す」状態から、 テキスト1つで意味ごと横断して探す 形に変えられます。まずは手元のデータで試し、実務で大量データを扱う場合は、ベクトルの保存先や検索基盤もあわせて考えるのがよさそうです。




