
はじめに
カスタマーサポートのプラットフォームとしてZendeskを利用されている企業は多いと思います。
Zendesk標準のAI機能も日々進化していますが、現場独自の運用をしていると、こんな壁にぶつかることはないでしょうか?
- 「社内のWikiやPDFマニュアルの内容を回答させたいが、標準機能では連携が難しい」
- 「『エラー画面のスクショ』などの画像が送られてくることが多いが、ボットが画像を理解できず有人対応になってしまう」
本記事では、Zendesk AIエージェントの拡張機能を使い、Google Cloudの Cloud Run と Vertex AI (Gemini) を連携させることで、「社内独自データ対応 (RAG)」 と 「画像対応 (マルチモーダル)」 を実現したAIチャットボットの開発事例を紹介します。
特に、Zendesk連携における技術的ハードルである「30秒のタイムアウト制限」をどう乗り越えたか、そのチューニングの勘所を中心にお話しします。
アーキテクチャ構成
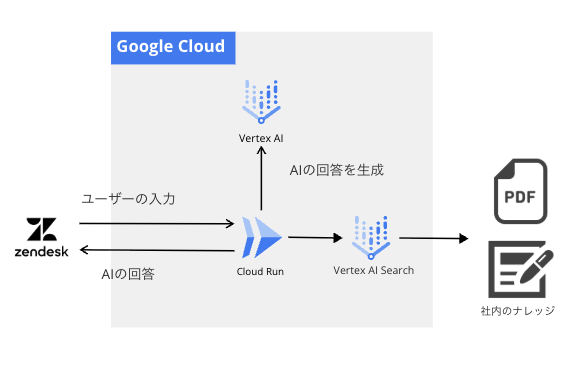
システム全体の構成は以下の通りです。
Zendeskをフロントエンドとし、バックエンドの頭脳部分をGoogle Cloud上に構築しています。
技術スタック:
- Frontend: Zendesk Messaging / AI Agent
- Backend: Cloud Run (Python / FastAPI)
- LLM: Vertex AI Gemini Pro & Flash
- RAG: Vertex AI Search
開発のステップ
1. ZendeskとCloud Runを繋ぐ
Zendesk AIエージェントには、外部APIを呼び出すための「APIインテグレーション」という機能があります。
これを利用して、ユーザーのメッセージをCloud RunへPOSTし、AIの回答を受け取ります。
Zendesk側の設定:
APIインテグレーションの画面から設定を行います。
Cloud Run側の実装:
Pythonの FastAPI を使用してエンドポイントを作成します。
from fastapi import FastAPI, Request
app = FastAPI()
@app.post("/api/chatbot/converse")
async def converse(request: Request):
data = await request.json()
user_message = data.get("user_message")
# ここでAI処理を行う
ai_response = await generate_ai_response(user_message)
return {"ai_reply": ai_response}
2. Vertex AI Searchでお手軽RAG
社内ナレッジを活用するため、RAG (Retrieval-Augmented Generation) を構築します。
運用負荷を考慮すると、ベクトルDBを自前で構築するのではなく、Googleのマネージドサービスである Vertex AI Search を採用しました。PDFやHTMLをデータストアにインポートするだけで、高精度な意味検索が可能になります。
3. Geminiで「画像」を理解させる (マルチモーダル)
テクニカルサポートでは「エラー画面」や「設定画面」のスクリーンショットが送られてくることが多々あります。
実装には LangChain (langchain-google-vertexai) を使用しました。画像データをBase64エンコードし、HumanMessage のcontentリストにテキストと画像URLを含めることで、簡単にマルチモーダル入力を実現できます。
from langchain_core.messages import HumanMessage
from langchain_google_vertexai import ChatVertexAI
async def process_multimodal(text_prompt: str, image_base64: str, mime_type: str):
# Geminiモデルの初期化 (LangChain)
chat = ChatVertexAI(
model_name="gemini-2.5-pro",
temperature=0.0
)
# マルチモーダルメッセージの構築
# テキストと画像をリスト形式で渡すことでGeminiが両方を認識する
message = HumanMessage(
content=[
{
"type": "text",
"text": text_prompt
},
{
"type": "image_url",
"image_url": {
"url": f"data:{mime_type};base64,{image_base64}",
"mime_type": mime_type,
},
},
]
)
# 推論実行
response = await chat.ainvoke([message])
return response.content
これにより、「スクショを貼るだけで解決策が返ってくる」という、非常にUXの高いボットが実現しました。
最大の難所:「30秒の壁」との戦い
ここからが本題です。
ZendeskのAPI接続機能には「リクエストから30秒以内にレスポンスを返さなければタイムアウト(エラー)扱いになる」という制約があります。
RAG(検索 + 生成)や画像処理は重い処理です。愚直に実装すると簡単に30秒を超えてしまいます。私たちは以下の3つのアプローチでこれを解決しました。
① モデルの「適材適所」 (Pro vs Flash)
Geminiには、高性能な Pro と、軽量高速な Flash があります。
最初は精度を出すため全てProで実装していましたが、レスポンスタイムが限界に達しました。
そこで、処理内容に応じてモデルを使い分ける戦略に切り替えました。
- 検索クエリの生成など中間処理: Gemini Flash
- 最終的な回答の生成: Gemini Pro
- 画像解析: 基本は Gemini Flash
これにより、回答品質を落とさずに全体のレイテンシを大幅に削減しました。
② 非同期処理 (Asyncio) の徹底
Pythonの asyncio をフル活用し、I/O待ち時間を極限まで減らしました。
③ 推論トークン数 (Thinking Budget) の制限
最新のGeminiモデルに見られる Reasoning(推論・思考)能力が高いモデルは、回答を出力する前に内部で「思考プロセス」を実行します。
この思考プロセスは精度向上に寄与しますが、その分だけトークンを消費し、生成時間が長くなります。
30秒という厳しい制限の中では、AIが長考しすぎるとタイムアウトの原因になります。
そこで、Vertex AIのパラメータである thinking_budget(推論トークンの上限)を適切に制限しました。
llm_pro = VertexAI(
model_name="gemini-2.5-pro",
# 思考に使うトークン数を1024に制限し、長考によるタイムアウトを防ぐ
thinking_budget=1024,
temperature=0.1,
)
このように「AIに考えさせすぎない」制約を設けることで、回答精度を維持しつつ、Zendeskが許容する時間内にレスポンスを返すチューニングを行いました。
まとめ
Zendesk AIエージェントとVertex AIを連携させることで、標準機能では手が届かない「社内独自データの活用」と「マルチモーダル対応」を実現しました。
特に「30秒制限」への対策は必須となりますが、Gemini Flash の活用と非同期処理の徹底により、実用的なレスポンス速度で運用することが可能です。
「Zendeskのボットをもっと賢くしたい」と考えている方は、ぜひCloud Run連携に挑戦してみてください。
次回予告
次回は、「Datadog LLM Observabilityを活用した感情分析によるSlack通知」について解説します。




