
遅ればせながら、AWSのRedshiftというサービスについてです。
Redshiftはデータウェアハウス(DWH)をサービスにしたものです。
DWHというのは簡単に言うと、専用ツールなどを使って様々な角度で分析するためのあらゆるデータの集まりです。
各所に分散している様々なデータを統合して関連付け、見えない傾向や状況などを知ることでビジネスの意思決定
(ビジネスインテリジェンス:BIというそうです)をしやすくするために用いられるようです。
直接関わり合いのない業務同士のデータも関連付けに利用されたり、過去との比較も重要な分析になるため、
通常のデータベースよりも巨大になります。
従来のDWHでは、専用のハードウェアとソフトウェアを利用するため高価でしたが、Redshiftが出たことにより
はるかに安価で気軽に利用することができるようになりました。
では、具体的どのようなものか、少しずつ触ってみて勉強していきたいと思います。
Redshiftは、言ってみればAWSが提供している巨大なPostgreSQLベースのクラスタです。
まずは、たくさんのデータを集計しやすいDBだと思って触ってみます。
AWSコンソールでRedshiftの画面を開いてみます。
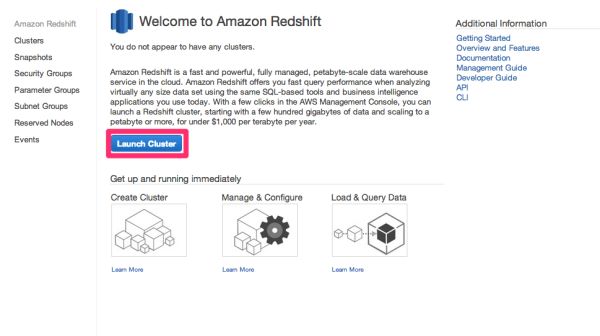
「Launch Cluster」をクリックします。
Cluster名やデータベース名などを適宜入力します。
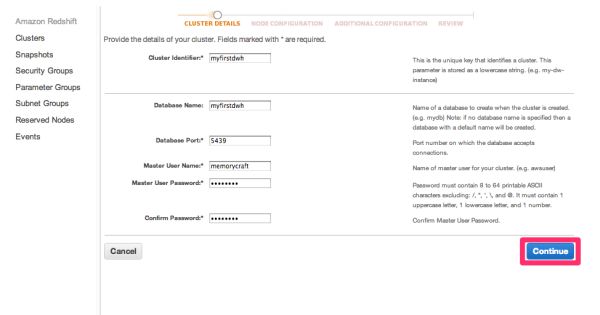
ノードの設定です。
クラスタの各ノードのインスタンスタイプとノード数を設定します。
最低2ノードからになります。
今回は2ノードにします。
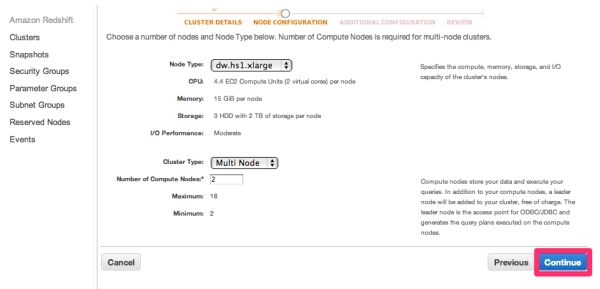
追加設定です。
パラメータグループやセキュリティグループ、VPCに入れるかなどを設定します。
今回は全てデフォルトにします。
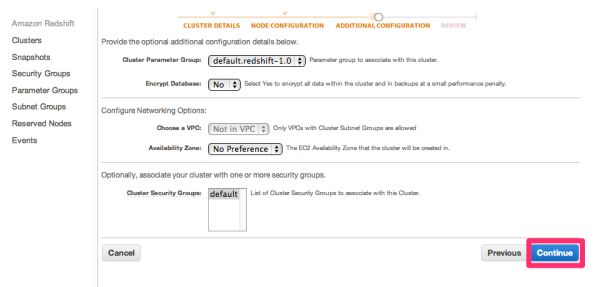
設定内容を確認して、「Launch Cluster」をクリックします。
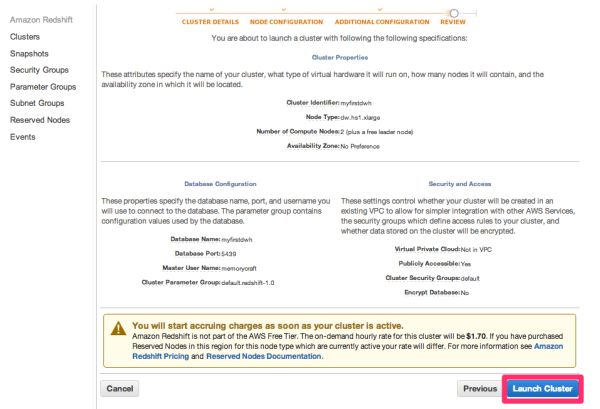
クラスタ一覧に今作成したクラスタが表示されました。
ステータスを見るとcreatingとなっているので、準備中なのだと思います。。

しばらくすると、availableに変わり、これで使えるようです。
クラスタ名のリンクをクリックしてみます。
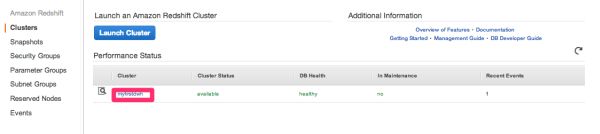
そうすると、詳細情報が開きます。
接続エンドポイントやJDBC、ODBCの接続子などが表示されています。
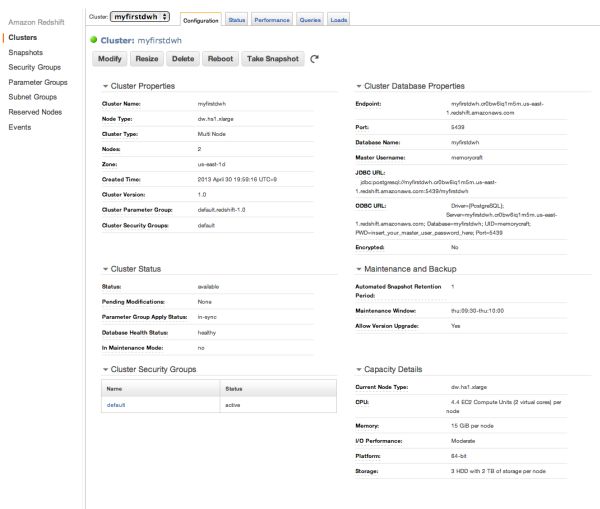
また、Security Groupsで、defaultグループにアクセス可能なIPを設定しておきます。
今回は、専用ツールなどは利用せず、psqlでこのエンドポイントに直接接続してみます。
$ psql -h myfirstdwh.cr0bw6iq1m5m.us-east-1.redshift.amazonaws.com -p 5439 -U memorycraft -W myfirstdwh
Password for user memorycraft: XXXXXXXXXX
psql (9.1.5, server 8.0.2)
WARNING: psql version 9.1, server version 8.0.
Some psql features might not work.
SSL connection (cipher: DHE-RSA-AES256-SHA, bits: 256)
Type "help" for help.
myfirstdwh=#
接続できました。
通常のpostgreSQLとRedshiftのpostgreSQLインターフェースの違いは以下のようになっているそうです。
○CREATE TABLE
Amazon Redshiftはテーブルスペース,パーティショニング,継承,制約をサポートしません。
Redshift では並列処理を最適化するために、CREATE TABLEにおいてsortとdistributionアルゴリズムを
定義することができます。
○ALTER TABLE
ALTER COLUMNはサポートされません。 ADD COLUMNは1つのALTER TABLEステートメントにつき1カラムだけ指定できます。
○COPY
RedshiftではS3バケットとDynamoDBから自動圧縮してデータをロードするために特別にカスタマイズされています。
○SELECT
ORDER BY … NULLS FIRST/LAST は未サポートです
○INSERT, UPDATE, and DELETE
WITHは未サポートです
○VACUUM
VACUUMのパラメータはpostgreSQLとRedshiftではまったく異なります。
今回は試しに、日本の郵便番号データを投入してみます。
以下のサイトからダウンロードした全国一括の郵便番号CSVファイルをS3にアップします。
現段階で、Redshiftは同一リージョンのS3でないとロードできないため、USリージョンのバケットに配置します。
次に、このCSVのフォーマットに合わせてテーブルを作成します。
create table zipcode(
official_area_code integer,
old_zipcode varchar(10),
zipcode varchar(10) distkey sortkey,
prefecture_name_kana varchar(500),
city_name_kana varchar(500),
town_name_kana varchar(500),
prefecture_name varchar(500),
city_name varchar(500),
town_name varchar(500),
flag_a smallint,
flag_b smallint,
flag_c smallint,
flag_d smallint,
flag_e smallint,
flag_f smallint
);
そしてデータをロードします。
ロードにはCOPYコマンドを利用します。
CSVはカンマ区切りなので、DELIMITER句で “,”を指定します。
また、文字列はダブルクォーテーションで囲われているので、REMOVEQUOTES句を利用します。
また、S3バケットへのアクセスにはCREDENTIALS句を利用して、AWSアクセスキーとシークレットキーを
指定します。
COPY zipcode FROM 's3://redshift-us-region/KEN_ALL.CSV' CREDENTIALS 'aws_access_key_id=;aws_secret_access_key= ' DELIMITER ',' REMOVEQUOTES;
COPY
ロードに成功した場合はCOPYと表示されます。
ロードに失敗した場合は詳細ログがstl_load_errorsテーブルに出力されるので、SELECTなどして確認します。
select * from stl_load_errors where filename = 'KEN_ALL.CSV';
データの投入が完了したので、集計などしてみます。
select count(distinct zipcode) from zipcode where prefecture_name = '北海道';
count
-------
8006
(1 row)
このように集計できました。
今回は手元のマシンからのアクセスで、データ数も少ないため、パフォーマンス面での性能はまだわかりませんが、
psqlで接続できるのはとても手軽です。
今後もいろいろ触って試してみたくなりました。
こちらの記事はなかの人(memorycraft)監修のもと掲載しています。
元記事は、こちら